一种基于深度学习的中小学演奏评分方法及系统与流程
- 国知局
- 2024-06-21 11:38:28
本发明涉及深度学习,尤其涉及一种基于深度学习的中小学演奏评分方法及系统。
背景技术:
1、在传统的中小学艺术素质测评系统中,尤其是音乐演奏评分方面,通常依赖于人工评委的主观判断,这种方法不仅耗时而且容易受到个人偏好和情绪的影响,从而导致评分的不一致性和不准确性。此外,传统评分方法在捕捉和评估演奏的各个细微方面,例如音准、节奏、音色和表现力方面也存在限制。往往忽略了演奏的动态和情感表达,这对于全面理解和评价一个音乐演奏是非常重要的。同时,传统方法在提供全面、客观和一致性的评估方面存在局限,特别是在处理大量学生演奏时。因此,如何提供一种基于深度学习的中小学演奏评分方法及系统是本领域技术人员亟需解决的问题。
技术实现思路
1、本发明的一个目的在于提出一种基于深度学习的中小学演奏评分方法及系统,本发明提出的基于深度学习的音乐演奏评分系统解决了现有技术的多个缺陷。通过自动化和智能化的方法提高了评分的效率和准确性。
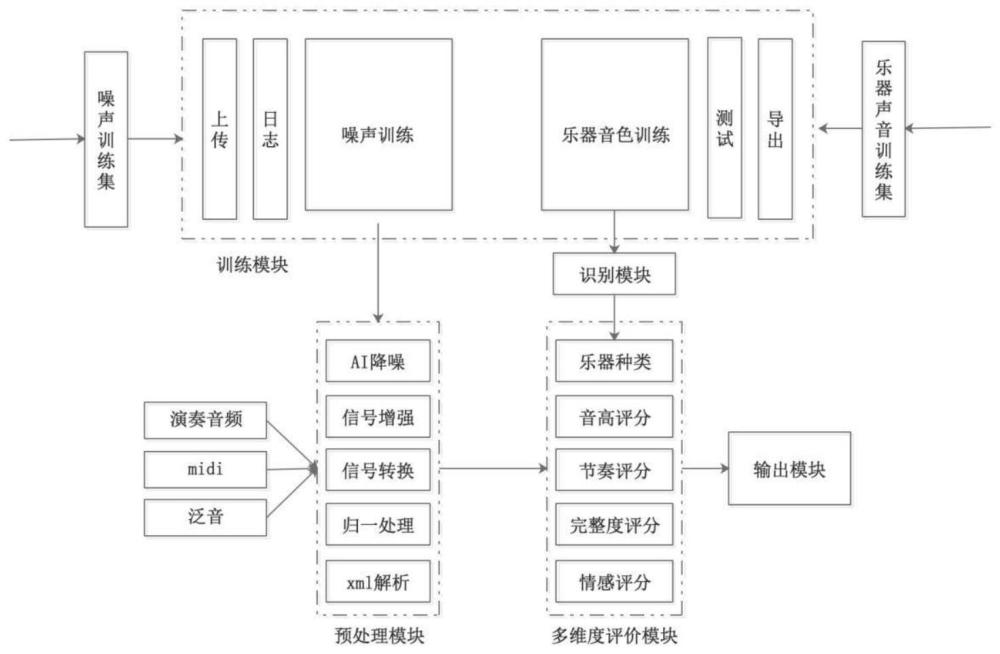
2、根据本发明实施例的一种基于深度学习的中小学演奏评分系统,包括
3、训练模块,用于对各种乐器的声音和环境噪声进行深度学习训练,得到乐器分类模型和降噪模型,并输送至预处理模块;
4、预处理模块,用于处理特定环境下的学生演奏音频和曲目信息,所述处理内容包括结合乐器分类模型和降噪模型对演奏音频、midi音和泛音的ai降噪、信号增强、信号转换、归一处理以及xml解析;
5、多维度评价模块,用于根据曲目信息,对预处理后的学生演奏音频进行多维度评价,所述多维度评价包括对乐器种类、音高评分、节奏评分、完整度评分和感情评分;
6、识别模块,用于对演奏音频使用的乐器做智能识别分类;
7、输出模块,用于将多维度评价的各维度分数和乐器识别结果做加权运算,最终输出学生演奏得分。
8、可选的,包括如下方法步骤:
9、s1、收集学生录音进行噪声提取和训练;
10、s2、收集相应乐器的演奏声作为训练样本,随机筛选学生考试乐器演奏的音频作为测试样本,并训练神经卷积网络的输出模型结构;
11、s3、对学生的录音、演奏题目的xml文件和标准的泛音样本进行处理;
12、s4、采用多维度评价模块进行打分,并通过输出模块将多维度评价模块的分数根据加权值进行汇总,得到学生演奏乐器的最终成绩。
13、可选的,所述s1具体包括:
14、s11、将学生录音断转化为单声道、16位的wav音频格式;
15、s12、将学生录音进行噪声提取并分类标注:噪声1、噪声2、…噪声n,得到噪声样本;
16、s13、将纯净学生录音进行分类标注:纯净音1、纯净音2、…纯净音n,得到纯净音样本;
17、s14、采用噪声样本与纯净音样本随机组合并随机设置信噪比的方式生成带噪音频片段,用来输入模型,快速拟合各种噪声环境下的特征。
18、可选的,所述s14具体包括将纯净音样本进行切割,得到纯净音的帧片段,每个帧片段随机选择一种噪声进行噪声训练,并设置随机信噪比,得到包含不同噪声类型和噪声强度的帧信号:
19、purgain=rand(-24,24)db;
20、noisegain=rand(-12,12)db;
21、noiseframen=fn*purgain+noise[rand(0,noise_len)[0:frame_len]*noisegain];
22、其中,noiseframen表示第n个带噪声的帧信号,fn表示第n个纯净音频帧,purgain、noisegain分别表示纯净音和噪声的随机增益值,noise_len表示噪声种类的长度,frame_len表示帧长度;
23、循环执行到纯净音的帧片段都处理结束,得到所有随机生成的不同噪声类型和噪声强度的帧信号。
24、可选的,所述噪声训练具体包括采用循环神经网络技术方案,深度学习框架采用keras、tensorflow,音频处理算法采用librosa,将噪声帧数据和纯净音数据分别进行dct变换,得到bfcc巴克频率倒谱系数,计算mfcc特征和谱质心、谱衰减、基频周期特征系数,输入到由密集层和gru层组成的训练网络中进行多轮次训练,得到一个过滤噪声的网络模型,并将网络模型保存到训练模块中用于后续的测试和运行。
25、可选的,所述s2具体包括:
26、s21、将训练样本和测试样本处理成16位、单声道、16khz采样率的wav文件并裁切得到样本单元的数据结构;
27、s22、将数据结构进行mfcc梅尔倒谱系数转换,得到梅尔倒谱频带数据量的样本单元数据结构,并进行拟合得到单次训练样本数据结构;
28、s23、对每个乐器样本单元的类别进行onehot转换,并且扩展到与样本单元数据结构一致的形态;
29、s24、采用神经卷积网络架构对训练数据进行处理,使用神经卷积网络层将数据特征图降维处理,输入到密集层进行近似预测,得到最终预测结果数据,构成神经卷积网络的输出模型结构。
30、可选的,所述演奏题目的xml文件是由专业的打谱软件将制作好的midi导出的谱信息文件,所述泛音样本是由演奏题的命题人员现场录制的样本音频,用来作为演奏情感判定的标准。
31、可选的,所述s3具体包括:
32、s31、将学生的录音通过s1中的训练模块降噪,对降噪后的学生音频采用带通滤波器进行信号增强,得到最终学生录音预处理音频;
33、s32、将演奏题目中的xml数据文件进行解析,得到曲目基础信息,所述曲目基础信息包括小节数、每小节拍数、每拍的时值、调性、音符的时值与频率序列,对xml数据进行填充或压缩,将xml信息转化成时域下各个音符频率的序列:xmlseq;
34、s33、将降噪后的学生wav音频通过pyin技术提取基频序列,得到与xml相同时间轴的频率序列:stuseq;
35、s34、将标准的泛音样本进行响度提取,得到每个采样点的振幅数据:
36、sample_loundness1,sample_loundness2,...sample_loundnessn;
37、得到泛音时域范围下的声音振幅序列;
38、s35、同样的处理方法将学生音频进行响度提取,得到学生时域范围下的振幅序列。
39、可选的,所述完整度评价参考xmlseq标准曲谱序列,对比学生演奏序列,将学生演奏序列stuseq取掩码,将静音掩码提取,计算静音掩码的分布:
40、将xmlseq标准曲谱序列中本身是静音的部分过滤;
41、将过滤后的静音序列进行小节间隙的换气识别,如果分布符合周期性的、并且间隔在预设范围之间,将静音序列纳入正常演奏换气序列,不计入扣分部分;
42、将最终过滤后的静音序列进行所属小节和所属拍点的归档,将连续丢帧数量*拍点总帧数作为扣分区间,即拍点所有帧全部丢失为全扣,最终乘以完整度扣分系数即为完整度总扣分;
43、所述音高评价参考xmlseq标准曲谱序列,对比学生演奏序列,将xmlseq和stuseq两个序列进行归一化处理,让两个序列值范围固定在相同的频率维度,采用逐小节归一化处理进行校对,如果校对异常,就会用逐小节归一化处理的方式处理序列,将两个序列按照小节和拍点进行切分,然后通过dtw算法将每小节序列进行对齐操作,将逐小节对齐的序列进行逐帧的音高对比:
44、标准拍的帧序列是xf1,xf2,xf3,...xfn;
45、学生拍点帧序列sf1,sf2,sf3,...sfn;
46、将两个序列进行标准均值对比:
47、
48、
49、其中,分别表示标准曲谱和学生演奏的一个拍点的序列标准均方差,两个均方差越接近说明演奏的越平稳,取序列的均值两个均值越接近说明音高越准,meanxf-meansf结果是负数时,认为是音高降低,当结果为正数时,认为音高提升;
50、将音高平稳度和准度两个标准进行扣分设置,,当标准均方差两者的绝对值差在此范围内,进行平稳度扣分,当均值差的绝对值范围在预设倍的标准均值范围内,进行准度扣分,两项指标乘以扣分系数及指标权重配比,得到每个拍点的音高扣分;
51、所述节奏评价对于序列的处理方式同音高,将对齐后的xmlseq和stuseq序列直接进行dtw路线对比,得到每个拍点每个帧偏移的位置分布,并得到帧偏移序列;
52、shf1,sf2,sf3,...sfn;
53、将帧偏移按小节为单位进行归档,每小节的帧偏移计算标准均方差:
54、
55、得到的值越小说明当前小节的节奏偏移越稳定,同时计算小节节奏偏移均值meanshf的值代表小节节奏点偏移的平均帧数,当meanshf<小节拍点帧数*10%范围认定当前小节节奏踩点是准确的,在此范围外扣分,节奏评价同样包含了节奏平稳度和节奏准确度两个指标,根据指标的配置和扣分系数权重配置,得到每个小节节奏的扣分。
56、可选的,所述泛音响度参考序列和学生演奏响度序列,根据完整度、音高和节奏的dtw校准,将泛音响度参考序列和学生演奏响度序列剔除静音掩码后与泛音进行时域上的重新校准,得到每个小节、每一拍的声强对比序列,将校准后的两个声强序列进行归一化处理,得到分贝刻度为[0,1]的序列,将每一拍对应的采样点进行归档,得到每一拍声强的子序列:
57、batch1:[ln1,ln2,ln3,...lnn];
58、得到泛音和学生音频声强每一拍的序列:
59、sample_ln_seq=[[ln1,ln2,ln3...lnn],...[ln1,ln2,..lnk]];
60、stu_ln_seq=[[ln1,ln2,ln3...lnn],...[ln1,ln2,..lnk]];
61、将两个序列同时做声强趋势和差值量化,拍的声强变化趋势及拍升高变化差值,对于声强趋势可以直接进行拍点对比,升代表1,将代表-1,平代表0,将两个序列每个拍进行且运算和乘法运算:
62、result_upi=sample_upi and stu_upi*(sample_upi*stu_upi);
63、其中,result_upi结果代表的是第i拍,两个音频声音强度变化趋势,如果非负数代表趋势一致,如果是负数代表趋势相反;
64、对于声强差值的运算,采用直接计算拍声强均值间的差值:
65、result_sample_shifti=sample_shifti-sample_shifti-1;
66、学生音频做同样的序列化操作:
67、result_stu_shifti=stu_shifti-stu_shifti-1;
68、得到两个声强拍点间差值的序列,两个序列每个点都进行差值运算,并将差值运算的结果求标准均方差,得到整体拍点声强幅度变化的趋势:
69、shift_diff i=result_sample_shifti-result_stu_shifti;
70、
71、其中,是整首曲子所有拍点声强幅度变化的标准均方差,此结果越小代表的两首曲子整体声音强度变化趋势一致。
72、本发明的有益效果是:
73、本发明提出的基于深度学习的音乐演奏评分系统解决了现有技术的多个缺陷。通过自动化和智能化的方法提高了评分的效率和准确性。系统能够全面分析音频,客观评估音准、节奏和音色等多个维度,从而提供更全面和一致的评估。这减少了人工评分的主观性和时间成本,使评估过程更为公正、高效。对于大规模的学生演奏评估,这种系统尤为有益,能够为中小学艺术教育带来更高的质量和标准。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22605.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。