一种车载环境下多说话人目标语音增强与识别方法及系统
- 国知局
- 2024-06-21 11:41:43
本发明涉及语音增强与识别,特别是涉及一种车载环境下多说话人目标语音增强与识别方法及系统。
背景技术:
1、随着生活水平的提高,车辆不仅只局限于载人,也成为了工作、会议、合作和休闲的场所。在车内进行工作、开会和自驾旅游已成为常态,车载语音识别技术也面临了新的挑战。车内多说话人环境下,语音识别系统常常受到其他说话人的声音干扰,导致指令识别的准确率下降。这一问题不仅影响了语音识别的性能,还影响了乘坐者的体验和安全性。因此解决在多说话人环境中的语音识别问题对于提高驾驶安全性、提升用户体验至关重要。
2、在嘈杂的多说话人环境中,语音识别的准确度受到多种因素的影响,包括语音清晰度、可懂度和语音质量。语音增强技术的作用是尽可能保留语音信号中的有用语音信息,同时抑制其他无用的噪声,以提高语音识别的准确率。目前,常用的语音处理方法包括谱减法、维纳滤波法和麦克风阵列法等,尤其是麦克风阵列法被广泛用于车载语音识别。然而,这些方法在低信噪比多说话人环境下的性能有限,包括增强后的语音失真以及难以保留目标说话人语音,这可能导致语音识别准确率的降低,难以满足人们日益增长的对车载语音识别准确率的需求。
技术实现思路
1、鉴于以上所述现有技术的缺点,本发明的目的在于提供一种车载环境下多说话人目标语音增强与识别方法及系统,本发明从密闭车载空间内嘈杂的多说话人语音中提取目标驾驶员说话人语音,以提高语音识别的准确率和网络的性能。
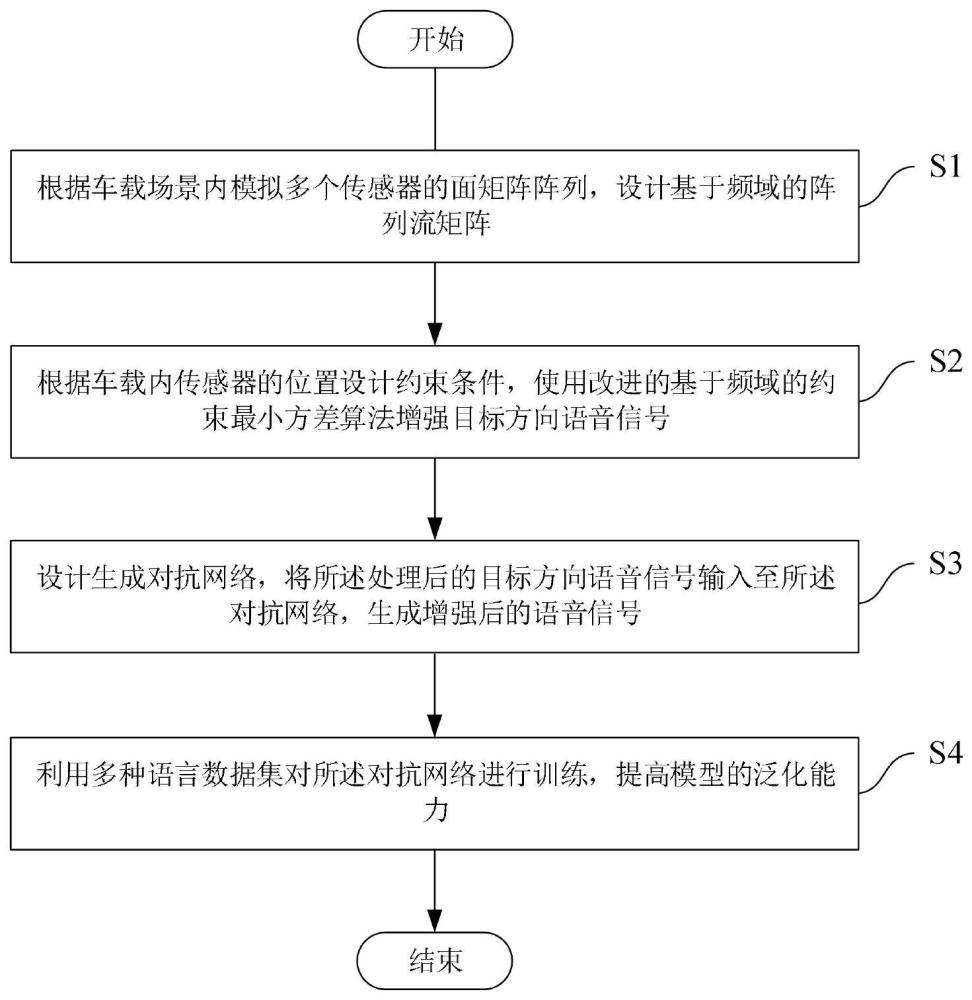
2、为实现上述目的及其他相关目的,本发明提供一种车载环境下多说话人目标语音增强与识别方法,包括:
3、s1、根据车载场景内模拟多个传感器的面矩阵阵列,设计基于频域的阵列流矩阵;
4、s2、根据车载内传感器的位置设计约束条件,使用改进的基于频域的约束最小方差算法增强目标方向语音信号;
5、s3、设计生成对抗网络,将所述处理后的目标方向语音信号输入至所述对抗网络,生成增强后的语音信号;
6、s4、利用多种语言数据集对所述对抗网络进行训练,提高模型的泛化能力。
7、在本发明的一实施例中,步骤s1中的根据车载场景内模拟多个传感器的面矩阵阵列,设计基于频域的阵列流矩阵包括:
8、一组车内有四个传感器的面矩阵阵列,设计基于频域的阵列流矩阵,所述阵列流矩阵的行对应传感器,列对应传感器的空间角度,所述阵列流矩阵的表达式为:
9、
10、其中,θ与φ分别表示麦克风的仰角和方位角,阵列流设为4×n矩阵,n取决于角度采样数量,dx与dy分别表示目标方向语音信号与麦克风之间的水平间距和垂直间距,c为光速;aij和bij分别表示传感器的索引。
11、在本发明的一实施例中,步骤s2中的根据车载内传感器的位置设计约束条件,使用改进的基于频域的约束最小方差算法增强目标方向语音信号包括:
12、根据所述车载内传感器的分布设计约束条件,确定目标方向语音信号的输出为一个期望值;
13、约束向量c(f)hw=1为目标方向语音信号的输出方向,c(f)hwi=γ(γ<1)为非目标方向语音信号的输出方向,γ用于削弱非目标方向语音信号。
14、在本发明的一实施例中,在步骤s3中,设计跳跃连接正则化联合注意力生成对抗网络,使用skip-regularized方式将所述对抗网络的生成器的并行双通道编码结构与解码结构的对应层进行连接,以实现校准;所述对抗网络包括噪声语音和无噪声语音的并行输入,在所述对抗网络的网络奇数层的跳跃连接校准模块,所述噪声语音分别与无噪声语音的网络层连接进行校准、与所述解码结构的对应层跳跃连接传递信息和梯度。
15、在本发明的一实施例中,所述使用skip-regularized方式将所述对抗网络的生成器的并行双通道编码结构与解码结构的对应层进行连接,以实现校准包括:
16、lossdistance=λ||xm-ym||1,
17、其中,λ为权重因子,xm、ym分别为第m层双通道解码结构输入的无噪声语音、噪声语音的特征表示。
18、在本发明的一实施例中,在所述生成器编码结构的最后一层网络与空间和通道注意力层之间加入并行双向门控循环单元,以提取目标语音的关键特征。
19、本发明还提供一种车载环境下多说话人目标语音增强与识别系统,包括:
20、阵列流矩阵设计模块,用于根据车载场景内模拟多个传感器的面矩阵阵列,设计基于频域的阵列流矩阵;
21、目标方向语音信号处理模块,用于根据车载内传感器的位置设计约束条件,使用改进的基于频域的约束最小方差算法增强目标方向语音信号;
22、对抗网络生成模块,用于设计生成对抗网络,将所述处理后的目标方向语音信号输入至所述对抗网络,生成增强后的语音信号;
23、训练模块,用于利用多种语言数据集对所述对抗网络进行训练,提高模型的泛化能力。
24、本发明还提供一种电子设备,包括处理器和存储器,所述存储器存储有程序指令,所述处理器运行程序指令实现上述的车载环境下多说话人目标语音增强与识别方法。
25、如上所述,本发明的车载环境下多说话人目标语音增强与识别方法及系统,具有以下有益效果:
26、(1)本发明的车载环境下多说话人目标语音增强与识别方法通过综合利用多传感器数据、多语种数据训练和先进的增强技术,有效解决了多说话人环境下的语音干扰问题。本发明能够提供高质量的增强语音,减少目标说话人语音的失真,并显著提高语音识别的准确率,不仅改善了驾驶安全性和用户体验,还使车内的工作和娱乐更加便捷和高效。
27、(2)本发明的车载环境下多说话人目标语音增强与识别方法在网络中加入双向门控循环单元,既可以解决车载低资源语音数据集的问题,又可以更加全面的了解语音的时序特征,为接下来的语音识别提高准确率。
28、(3)本发明的车载环境下多说话人目标语音增强与识别方法使用多语种数据集对网络进行训练,可以提高网络的性能,生成质量更好的增强语音。
29、(4)本发明的车载环境下多说话人目标语音增强与识别方法采用激光雷达和相机作为传感器,分别采集点云信息和图像信息。从而有效地感知车辆周围的环境状况,能够精确检测道路场景中的目标。
技术特征:1.一种车载环境下多说话人目标语音增强与识别方法,其特征在于,包括:
2.根据权利要求1所述的一种车载环境下多说话人目标语音增强与识别方法,其特征在于,步骤s1中的根据车载场景内模拟多个传感器的面矩阵阵列,设计基于频域的阵列流矩阵包括:
3.根据权利要求2所述的一种车载环境下多说话人目标语音增强与识别方法,其特征在于,步骤s2中的根据车载内传感器的位置设计约束条件,使用改进的基于频域的约束最小方差算法增强目标方向语音信号包括:
4.根据权利要求3所述的一种车载环境下多说话人目标语音增强与识别方法,其特征在于:在步骤s3中,设计跳跃连接正则化联合注意力生成对抗网络,使用skip-regularized方式将所述对抗网络的生成器的并行双通道编码结构与解码结构的对应层进行连接,以实现校准;所述对抗网络包括噪声语音和无噪声语音的并行输入,在所述对抗网络的网络奇数层的跳跃连接校准模块,所述噪声语音分别与无噪声语音的网络层连接进行校准、与所述解码结构的对应层跳跃连接传递信息和梯度。
5.根据权利要求4所述的一种车载环境下多说话人目标语音增强与识别方法,其特征在于,所述使用skip-regularized方式将所述对抗网络的生成器的并行双通道编码结构与解码结构的对应层进行连接,以实现校准包括:
6.根据权利要求4所述的一种车载环境下多说话人目标语音增强与识别方法,其特征在于,在所述生成器编码结构的最后一层网络与空间和通道注意力层之间加入并行双向门控循环单元,以提取目标语音的关键特征。
7.一种车载环境下多说话人目标语音增强与识别系统,其特征在于,包括:
8.一种电子设备,包括处理器和存储器,所述存储器存储有程序指令,其特征在于:所述处理器运行程序指令实现如权利要求1至6任意一项所述的车载环境下多说话人目标语音增强与识别方法。
技术总结本发明涉及语音增强与识别技术领域,特别是涉及一种车载环境下多说话人目标语音增强与识别方法及系统。包括根据车载场景内模拟多个传感器的面矩阵阵列,设计基于频域的阵列流矩阵;根据车载内传感器的位置设计约束条件,使用改进的基于频域的约束最小方差算法增强目标方向语音信号;设计生成对抗网络,将处理后的目标方向语音信号输入至所述对抗网络,生成增强后的语音信号;利用多种语言数据集对所述对抗网络进行训练,提高模型的泛化能力。本发明解决了多说话人环境下的语音干扰问题,能够提供高质量的增强语音,减少目标说话人语音的失真,并显著提高语音识别的准确率。技术研发人员:任悦悦,丁绪星,钱强,周学顶受保护的技术使用者:安徽师范大学技术研发日:技术公布日:2024/4/7本文地址:https://www.jishuxx.com/zhuanli/20240618/22965.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表