逻辑推理知识引导强化的低资源无监督音节划分方法
- 国知局
- 2024-06-21 11:42:30
本发明涉及逻辑推理知识引导强化的低资源无监督音节划分方法,属于人工智能。
背景技术:
1、音节的划分常发生在语音的韵律峰值位置,是人类最容易感知的语音单元。音节通常被认为是婴儿和成人言语感知的核心,许多关于早期语言习得的理论和行为研究也是基于口语的音节级表征,尽管人们相信音节在语言习得中的重要性,但类似成年人的音节划分取决于对音韵结构和具体使用语言知识的掌握。在语音和语言处理中,正确的音节划分能够提取语音的音韵信息,从而为语音识别、语音合成以及语言理解等任务提供关键支持,尤其对于无监督语音识别中的转录文本的序列化过程。
2、根据联合国教科文组织(unesco)的估计,全球有大约7,000种活跃语言,大约有3800多种语言拥有自己的书写系统,音节划分任务是语言独立的,不同的语言有着不同的音节划分规则,且复杂程度不一。因此每一种语言都需要专门构建合理的音节划分数据集或构建音节划分模型或方法。近年来,受益于深度学习方法的推动,音节划分任务取得了较大的进展。使用有监督式训练的方法开发音节划分模型比基于规则匹配的方法更为常见,但二者各有利弊,基于有监督式训练的方法能从大量标签数据中学习到复杂的模式和规律,对未见模式具有较好的泛化性;但对于大多数低资源语言来说标注数据难以获取,通常采用基于规则的方法,此类方法通常由语言学专家定义规则,有较强的解释性,特别适用于资源有限的语言,缺点是在应对复杂多变的语言规则时,规则往往无法覆盖所有的音节模式。目前,世界上绝大多数语言尚缺乏音节划分工具、模型或方法。
3、音节划分方法主要基于数据驱动或规则的方法,数据驱动方法常使用如条件随机场[i]、隐马尔科夫模型、支持向量机、深度神经网络等;随着深度学习的兴起,对于具有大规模数据集的高资源语言,神经语言模型取得了出色的结果,在大规模文本语料库上进行预训练,然后在特定任务上进行微调,可以在许多自然语言处理任务和基准测试中取得显著的性能提升。这些模型一定程度上提高了音节划分的准确率和泛化能力,其中,gpt作为一种出色的预训练语言模型,尽管在各种nlp任务中展现出卓越的性能,但在低资源语言上仍然存在缺点和挑战,主要表现为不支持低资源语言或零资源语言,或是在支持的低资源语言上的性能依然较差。因此,对于低资源语言和零资源语言,大语言模型仍无法具有很好的通用性。因此,基于规则和传统机器学习技术仍然是开发低资源语言的主流技术。基于规则的方法需要依赖语言学家手动定义的音节划分规则和复杂的特征设计,例如基于音节结构和音变规律的等。不同语言具有不同的处理方法和规则,如使用一组有注释的有限状态转换器表达式对爱沙尼亚语进行音节划分,在巴西葡萄牙语中处理带有双元音和间断音的单词方面提出新的规则算法,使用一种改进的音节匹配策略来处理马来语,然后用于语音合成(tts)以及结合了音韵规则和每个类别中的模糊k最近邻居(fknnc),在印尼语中开发一个图形音节划分模型等。绝大多数的音节划分工作都是基于规则实现的算法。对于本文主要研究的老挝语,老挝语和其他东南亚语言一样,是用一个连续体书写的。空格在老挝语中是很少使用的字符,不同于英语,由于老挝语缺少空格字符,就引入了额外的复杂性。phissamay p等人,详细研究了老挝语音节组合的规律,并依据规律制定出许多规则,利用字符串匹配算法来实现对老挝语的音节划分。
技术实现思路
1、本发明提供了逻辑推理知识引导强化的低资源无监督音节划分方法,以用于更好的对知识库未见模式将进行较好的预测,大大降低了音节词错率。
2、本发明的技术方案是:逻辑推理知识引导强化的低资源无监督音节划分方法,所述方法的具体步骤如下:
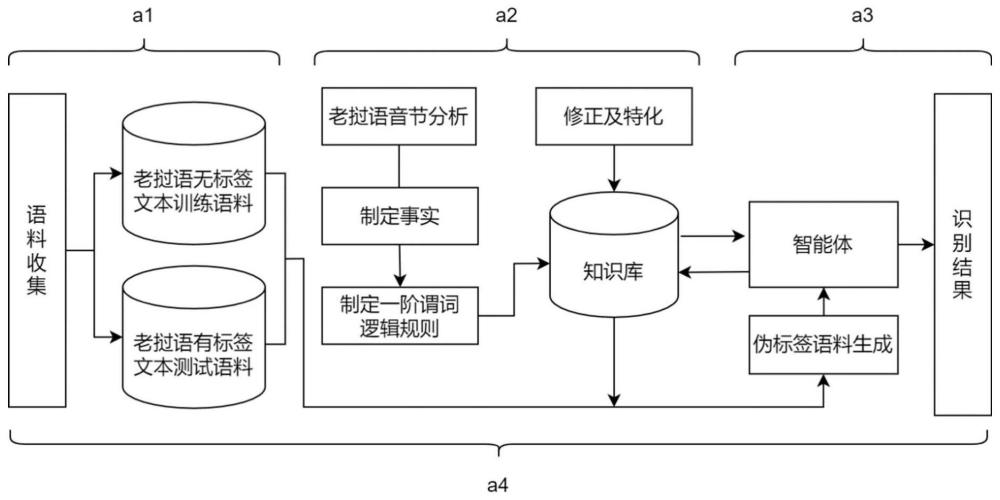
3、step1、构建老挝语音节划分逻辑推理知识库作为交互环境:
4、根据老挝语音节划分先验知识编写事实和一阶逻辑规则来构建老挝语音节划分逻辑推理知识库kb;
5、老挝语语音由音素、音节和声调构成,其中元音共有28个,单元音18个,复合元音6个,特殊元音4个;辅音共有32个,其中低辅音12个,高辅音12个,中辅音8个;复合辅音共有13个;尾辅音共有8个,死音节尾辅音3个,活音节尾辅音5个(详见图2左)。音节组合遵循如下规则:1.中辅音和单元音可相拼;2.低辅音和单元音可相拼;3.复合元音可与中辅音和低辅音相拼;4.高辅音可与单元音、复合元音和特殊元音相拼;5.特殊元音可与中辅音和高辅音相拼;6.声调写在每个辅音字母上,如有元音在该辅音上面,则写在元音之上;7.特殊元音不能加尾辅音,因其本身已包含了尾辅音。8.部分元音和尾辅音相拼要变形。我们将上述规则编写为一系列事实和逻辑规则来执行逻辑推理,即只对一个可能的音节字符串给出true or false的回答。用f1、f2、...、fk表示逻辑条件或规则,用于确定字符串是否构成一个音节。每个fk代表一个具体的规则,逻辑运算符"λ"表示逻辑与,逻辑推理元规则可如下式表示:
6、syllable←f1∧f2∧...∧fk,(1)
7、
8、当且仅当所有逻辑条件f1、f2、...、fk都满足(为真)时,字符序列构成一个音节(syllable==真),如式(1)。当且仅当存在任一逻辑条件fk不满足(为假),则该字符串不构成一个音节(syllable==真),逻辑符号表示”非”的意思,式(2)。
9、假设我们有以下事实:c={ca,cb,cc},其中,c是辅音,ca是低辅音,cb是高辅音,cc是中辅音,cak∈ca,cbk∈cb,cck∈cc,k={1,2,...,n}。u是尾辅音,v={va,vb,vc},其中v是元音,va是单元音,vb是特殊元音,vc是形变元音,vak∈va,vbk∈vb,vck∈vc。根据正字法规则及组合规律,可以总结出以下元规则,如下式所示.
10、syllable(c1,c2,...,cn):-consonnant(c1,...,ck),vowel(ck+1,...,cn).
11、syllable(c1,c2,...,cn):-consonnant(c1,...,ck),vowel(ck+1,...,cn-1),tail_consonnant(cn).
12、syllable(c1,c2,...,cn):-vowel(c1,...,ck),consonnant(ck+1,...,cn).
13、syllable(c1,c2,...,cn):-vowel(c1,...,ck),consonnant(ck+1,...,cn-1),tail_consonnant(cn).
14、...
15、在上式中,逻辑规则syllable(c1,c2,...,cn):-consonnant(c1,...,ck),vowel(ck+1,...,cn).含义如下,有字符序列(c1,c2,...,cn),如果序列c1到ck是辅音,并且剩余的字符ck+1到cn是元音,那么该序列c1,c2,...,cn符合辅音-元音的组合模式。
16、step2、修正知识库逻辑规则:通过“生成-测试法”(generate-then-test)自顶向下的逐渐“特化”及修正逻辑规则;包括老挝语元音能和辅音组合,逐渐特化为老挝语特殊元音和复合辅音的组合;如式(3)(4)。
17、syllable(x,vbk):-consonant(xa),single_vowel(vbk).(3)
18、syllable(x,y,vbk):-consonant(xb,yc),single_vowel(vbk). (4)
19、上式中,consonant(xa)表示x是老挝语低辅音音素,consonant(xb,yc)表示使xbyc的组合是老挝语的复合辅音,vbk表示老挝语特殊元音集合中的第k个音素。
20、进一步地,所述step2中,特化过程是指老挝语音节组合由一般到特殊的组合规律的生成过程,包括从老挝语元音和辅音的一般组合开始,逐渐特化为老挝语特殊元音和复合辅音的组合规则,,这过程涉及在生成过程中不断测试和修正规则,以使其更符合老挝语的语音结构。
21、step3、老挝语音节划分知识引导的训练策略构建:
22、循环神经网络分类器建模智能体,利用知识库kb对每一次智能体的动作(音节划分)执行后的新状态给出奖励reward,并添加到经验池,随后经验池中的历史经历将作为训练资料(transition)被用于智能体的学习,重复以上步骤直至智能体收敛。
23、本发明设计了无监督音节划分的训练策略,核心的逻辑决策模块(kb)在此起到关键作用。知识库kb包含了所有人类语言学家总结出来的先验知识。首先智能体从环境(dataset)中获取一个句子或词,每一次划分的结果作为一个新状态,数个epoch作为一个episode。训练过程具体如下:给定一个状态序列s,智能体按贪婪原则对s的执行动作为a,将s和a输入知识库kb,观察到新的状态s’和reward r,将[s,a,r,s’]存入d作为transition,从d中取出mini batch[sj,aj,rj,sj+1]计算贝尔曼损失和crf损失,损失函数如式(5)。在这里,强化学习用于建模智能体与kb之间的交互过程,crf用于建模相邻标签之间的依赖关系。下一步,计算梯度更新智能体,重复该过程直到模型收敛。其中kb对智能体的划分结果进行逻辑推断,定义syllable yi∈c←u(kb,yi),syllable yi∈e←v(kb,yj),u(kb,yi)表示第i个子序列符合音节模式推断,v(kb,yj)表示第j个子序列不合符音节模式推断,c表示知识库推断为正确的模式集合,反之,e为知识库推断错误或无法确定的模式集合。对于单个输入文本序列,其全集u=c+e,训练资料transition的标签生成过程为对每一次推断得到的集合c,标记为正例伪标签,对知识库推断错误或无法确定的模式集合e,全部标记为负例伪标签,标记的标签用于crf的计算,每个mini batch的目标标签的推理过程如式(6)所示。
24、loss=-αlog(p(ykb|x))+(1-α)(rkb+γmaxa′q(s′,a′;θ-)-q(s,a;θ))2 (5)
25、
26、式(6)中,x为输入序列,y为知识库kb对智能体的执行结果进行逻辑推理后的标签序列,该标签序列的得分记为score(x,y),y’表示其它可能的标签序列,yj为对应的第j个字符的标签。上述算法详细说明了逻辑推理知识引导强化的低资源无监督音节划分交互过程。
27、本发明的有益效果是:
28、本发明首先构建老挝语音节逻辑知识库(kb),通过引入逻辑推理知识及建模智能体与知识库kb之间的交互过程,实现音节划分知识引导的无监督音节划分方法,该方法能使模型在大量无标注数据中很好的学习老挝语语言结构和规律。实验结果表明,该方法取得了很好的音节划分结果,词错率(wer)达到了1.77%,验证了方法的有效性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23052.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表