一种基于神经网络的语音干扰噪声授权消除方法
- 国知局
- 2024-06-21 11:44:31
本发明属于语音隐私保护领域,尤其涉及一种基于神经网络的语音干扰噪声授权消除方法。
背景技术:
1、在现代社会,麦克风已经无处不在,它们被广泛的嵌入各种商业电子产品中,如智能手机、智能音响等。这种普遍存在的麦克风设备有可能被攻击者用于收集用户的语音信息,加剧了普通用户对语音隐私的担忧。同时,由于麦克风设备具有黑盒特性,攻击者利用、破坏或误配置麦克风进行窃听活动的行为较难识别。实际上,借助自动语音识别技术,攻击者可以从用户的声音数据中提取个人信息,从而侵犯其隐私权。
2、由于麦克风设备被操纵所导致的语音隐私泄漏问题的严峻状况,引起了设备和服务提供方,以及普通用户的广泛关注,并对反窃听技术的提出了迫切需求。现有的典型技术解决方案包括使用电磁干扰诱导麦克风内部电路产生噪音,然而但这种方法可能会影响附近的其他电子设备,如心脏起搏器,导致不可预测的结果。其他方法包括roy和zhang等人在2017年发现的一种基于麦克风侧信道的语音干扰方法,实现利用人类不可听的超声波将可听的声音信号注入麦克风。由于这种方法的传输距离适中,并且对附近其他用户和设备的影响可以忽略不计,因此被认为是一种更具实用性的语音干扰解决方案。在此研究的基础上,后续又有其他学者设计了配备多个超声波发射探头的可穿戴设备,通过持续发射超声波以干扰录音环境中的麦克风设备。
3、这些方法的显著不足在于它们大多数使用简单形式的噪音,如高斯噪声和随机频率噪声,仅依靠高功率来实现音频干扰。这种简单形式的噪声可以被现有技术轻松去除,因此无法完全防止隐私泄露。对于其他一些基于人类语音的噪声干扰的方法,由于这些方法使用连续的语音信号,这也导致添加的噪声可能被攻击者利用语音分离技术从录音中去除。因此,近年来出现了一些更为复杂的语音干扰噪声生成方法。
4、专利文献cn117059073a提供了一种语音识别信息获取方法,包括s1,获取语音信号;s2,将语音信号转换为电信号;s3,预处理电信号,首先进行能量归一化,即通过调整信号的幅度,使其在相同能量下具有一致的幅度,这有助于消除不同录音音量带来的差异,其次,采用短时能量法进行端点检测,以识别出语音信号中的活跃段落,去除静音段,最后,运用主成分分析(pca),降低语音信号的维度,保留最能代表语音特征的成分,从而减少后续计算的复杂性;s4,特征提取;s5,优化效率和精度;s6,数据匹配;s7,自动更新;s8,基于语言模型进行纠错。
5、然而,以上这些方法添加的干扰噪声往往对获得授权的用户和攻击者同样有效,即在干扰未授权录音设备的同时同样影响允许授权的录音设备,从而导致授权用户在避免语音隐私泄漏的同时无法进行授权录音。这个问题将严重限制上述干扰噪声生成方法的使用场景,不能满足符合实际的语音隐私保护安全需求。
技术实现思路
1、本发明的目的在于提供一种基于神经网络的语音干扰噪声授权消除方法,该方法能够实现授权定向清除不同形式的干扰噪音,以获得高质量的语音数据。
2、为了实现本发明的第一个目的,提供了一种基于神经网络的语音干扰噪声授权消除方法,包括以下步骤:
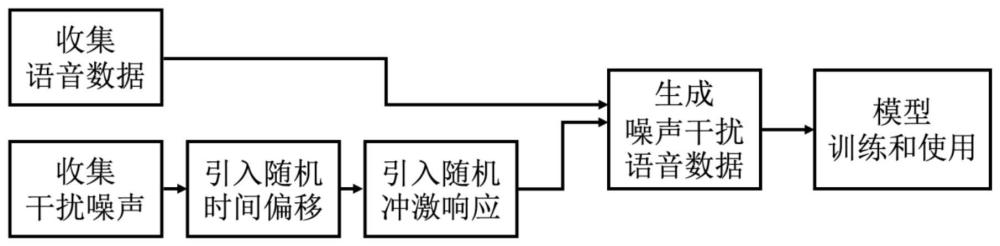
3、步骤1、获取语音数据集,其包括不同说话人和对应的说话内容;
4、步骤2、收集不同的音频噪声数据集;
5、步骤3、给音频噪声数据集和语音数据集打上对应的时间戳信息,得到初始噪声训练数据集,再根据音频采样率给初始噪声数据集引入随机时间偏移;
6、步骤4、从多个公开的声学数据集中随机选择冲激响应并与引入随机时间偏移后的初始噪声训练数据集融合;
7、步骤5、将步骤4中处理之后的噪声数据与语音数据随机融合,以得到含噪的语音训练数据集;
8、步骤6、以步骤3获得的初始噪声训练数据集和步骤5获得的语音训练集作为预构建噪声消除神经网络的输入,并以步骤1中的语音数据集作为输出评估目标,以获得用于过滤语音信号噪声的噪声消除模型。
9、具体的,获取语音数据集时还包括数据扩充,所述数据扩充通过音色迁移的方式扩充较少说话人的语音数据。
10、具体的,音色迁移的具体流程为:针对数据集中某个数据较少的说话人a,使用神经网络先提取其声纹,其中音色提取的神经网络表示为e=f(x),x为长度大于1.6秒的语音信号,e为输出的一维声纹特征。再将任意其他人的语音数据和说话人a的声纹特征e输入到音色迁移的神经网络中,从而获取符合说话人a音色的大量语音数据。
11、具体的,所述噪声信号包括单频噪声,扫频噪声或语音噪声。
12、具体的,在现有的一些噪声种类之外,额外生成基于人类语音音素的干扰噪声,保证去噪网络对于复杂噪声的去噪能力。
13、具体的,在步骤5中,在语音训练数据集中添加噪声后语音信号的表达式如下:
14、r(t)=s(t)+α·h1(t)*n(t)+a(t)
15、其中,r(t)表示添加噪声后的语音信号,h1(t)代表不同环境中信号传播的冲激响应,a(t)代表环境噪声,α表示噪声的放大因子,s(t)表示语音信号,n(t)表示音频噪声。
16、具体的,对于语音和噪声,统一重采样到16khz采样率,其赋予噪声的时间戳精确到16khz采样率下的单个采样点,即1/16000=0.0625ms。
17、具体的,在步骤3中,对噪声信号中引入了随机偏移,偏移间隔为[-fs,fs],其中fs表示音频采样率,在训练数据中引入随机偏移,通过优化训练损失函数迫使模型能够自动对齐添加噪声的音频信号和被添加噪声信号的时间域。
18、具体的,在步骤4中,利用多个公开的声学cir数据集构建测试集,在每个模型训练步骤中随机选择冲激响应,通过在训练过程中引入丰富的cir数据,激励模型学习冲激响应特征,以消除模型生成掩码时的冲激响应影响。
19、具体的,所述噪声消除神经网络基于transformer架构构建。
20、具体的,所述噪声消除神经网络包括含编码器,掩码网络和解码器;
21、所述编码器用于将输入语音信号转换为二维特征图;
22、所述掩码网络包含两个sepformer模块,所述sepformer模块用于学习音频数据图表征中包含的短期和长期的音频特征,使得掩码网络能够捕捉到添加干扰噪声的录音信号和噪声信号的特征图之间的内在联系;
23、所述解码器采用和编码器对称的模型架构,用于将掩码网络处理后的音频特征图恢复为去除噪声的干净音频信号。
24、具体的,采用损失函数对噪声消除神经网络进行训练。
25、具体的,所述损失函数基于尺度不变信噪比进行设计,其表达式如下:
26、
27、式中,s为训练过程中的目标纯净语音,为神经网络输出的估计纯净语音,t表示矩阵的转置运算,||x||表示x的l2范数。
28、与现有技术相比,本发明的有益效果:
29、现有的语音干扰噪声生成技术基础上,采用训练数据时间域随机偏移处理算法,以提高噪声消除神经网络模型具有鲁棒性,噪声清除普适性更强。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23272.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。