一种基于声音识别的轨道交通多维度落物分析方法及系统与流程
- 国知局
- 2024-06-21 11:45:55
本发明涉及声音信号处理、声音识别、数据分析和模式识别、多维度分析和轨道交通安全等关键技术,特别是一种基于声音识别的轨道交通多维度落物分析方法。
背景技术:
1、如今高铁已经成为了一种重要的交通工具,对于隧道产生的落物可能会对高铁运行造成严重影响,甚至引发事故。通过落物检测,可以及时发现轨道上的物体,避免碰撞和其他安全隐患,保障乘客和列车的安全。许多现有的方法主要依赖于视觉监测,即使用摄像机或其他视觉传感器来检测落物事件,这种方法容易受到天气条件、光照变化和视野受限等因素的影响,可能导致漏报或误报。
2、随着人工智能技术的快速发展,音频信号处理和语音识别领域取得了巨大的进展。梅尔频谱是一种在语音处理中广泛应用的特征表示方法,能够提取音频信号中与人耳感知相关的频谱特征。梅尔频谱能够帮助在轨道交通多维度落物分析中捕捉到语音信号中的重要信息,如语音的音调、共振峰等。
3、同时,卷积神经网络(convolutional neural networks,简称cnn)已被证明在图像分类任务中非常有效。resnet(residual network)是一种具有残差连接的深度卷积神经网络结构,通过引入残差模块解决了深度网络训练中的梯度消失和梯度爆炸问题,提高了网络的训练效果。通过在边缘端将音频信号转换为梅尔频谱,然后将梅尔频谱作为输入数据传入云端,加入到senet(squeeze-and-excitation networks)模块的resnet网络,可以进行音频信息的分类识别。通过训练这个网络,可以实现对不同音频信息的自动识别和分类,例如语音命令识别、语音情绪分析等。
技术实现思路
1、本发明所要解决的技术问题是克服现有技术的不足而提供的一种基于声音识别的轨道交通多维度落物分析方法、系统及存储介质,其目标为通过收集到的落物声音数据,分析出落物的大小和实物类型。通过声音识别的轨道交通多维度落物分析方法可以对视觉监测方法加以辅助,从而能够保证更高的准确性。
2、本发明为解决上述技术问题采用以下技术方案:
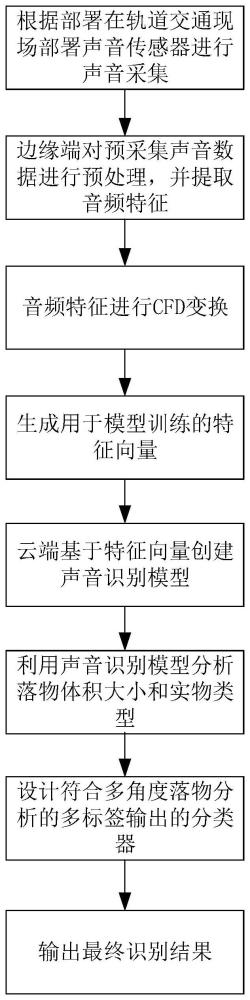
3、一种基于声音识别的轨道交通多维度落物分析方法,包括步骤如下:
4、步骤1.在轨道交通现场部署声音传感器,预采集轨道交通系统现场的声音数据;
5、步骤2.在边缘端对预采集声音数据进行预处理,并提取预采集声音数据中的音频特征;
6、步骤3.将提取到的音频特征进行cfd变换,生成用于声音识别模型训练的特征向量;
7、步骤4.将得到的特征向量,上传至云端,然后在云端基于生成的所述特征向量创建声音识别模型;
8、步骤5.声音识别模型结合多维度落物分析的多标签输出的分类器,分析落物体积大小和实物类型,输出最终识别结果。
9、进一步的,步骤1中,声音数据包括不同体积大小区间和不同实物类型的落物声音数据,将声音数据信号表示为a[n],n=0,...,n-1,n为第n个采样点,n为样本数量,n具体取决于所使用的采样频率及其持续时间。
10、进一步的,步骤2中,边缘端对预采集声音数据进行预处理时,具体步骤如下:首先对预采集声音数据进行去噪;然后进行预加重,并对声音数据信号进行高通滤波,突出高频部分,减小低频部分的能量损失,利用平滑窗函数w[·]将信号a[n]分割成多个重叠的样本块,其大小决定了时间分辨率和频率分辨率的权衡,然后计算声音数据信号短时傅里叶变换(stft)为:
11、
12、其中k=0,...,k-1,,k表示第k个时间帧,k表示时间帧数,m=0,...,ndft-1代表频率,ndft表示dft变换的点数;dft变换在频域信号上进行等间的采样,将连续的频率离散化成ndft个点;通过对变换后的信号进行幅度平方运算,得到每个频率分量的功率;将功率谱通过每个梅尔滤波器进行滤波,得到梅尔频谱ψ。
13、进一步的,步骤3中,通过梅尔频谱将音频特征转换为cfd(cadence frequencydiagram)的新域,这个变换域提供了信号中每个频率的重复周期的信息,被称为节奏频率。因此,计算cfd作为与梅尔谱图一起研究的附加域,可以进一步提高对a[n]的特征提取,其公式为:
14、
15、其中ξ表示节拍频率。
16、计算cfd变换后,进行模量取对数,并在区间[0,1]内进行归一化,以符合切比雪夫矩的提取程序,通过变换操作投影到切比雪夫多项式的正交基上,其公式为:
17、
18、其中ncvd表示用于计算cfd的频率仓,是描述的归一化振幅因子,l和h是梅尔谱转化为cfd域生成的图像大小为l×h的矩阵,x、y分别是dft频域对应的第x个频率和cfd域对应的第y个频率,l和h都表示阶数;是l阶的切比雪夫多项式,是h阶的切比雪夫多项式,是cfd模量的归一化对数,最终可以的得到矩阵构造特征向量f1=[c0,0,c0,1,...c0,h,c1,0...,cl,h]t;
19、在梅尔频谱计算之后,再进行对数运算,将对数运算压缩后的信号进行离散余弦变换,可以得到梅尔频率倒频谱系数mfcc(mel-frequency cepstrum coefficients),取每个mfcc随时间的平均值,可以得到构造的特征向量:
20、
21、将特征向量f1和f2串联为可以得到用于声音识别模型训练的特征向量。
22、进一步的,步骤4中,基于通过梅尔频谱和cfd转换提取的所述特征向量作为输入数据加入到结合了se模块的resnet网络,得到音频信息的分类识别。resnet50的第一个卷积模块中只使用了1个卷积核大小为7x7的卷积层实现特征提取,但是考虑到对交通落物的多维度分析,需要对落物体积大小和实物进行更详细的分类,因此需要对网络结构进行改变,本文将第一个卷积层改造为双通道,第一个通道采用sa(scale aggregation)块来替换卷积核大小为5x5的卷积层;第二个通道采用sa块来替换卷积核大小为3x3的卷积层,输出时将两个通道的特征图相加,构成完整的多尺度特征提取模块,创建的声音识别模型为:
23、f1(f)=mp(δ1(bn(wα(f)))),
24、f2(f)=mp(δ1(bn(wβ(f)))),
25、fmulti-scale(f)=f1(f)+f2(f)
26、其中f为输入的特征向量,f1(f)对应卷积尺度为5x5分支的探头输出,f2(f)对应卷积尺度为3x3分支的探头输出,δ1为relu函数,bn为批量归一化,mp为最大池化操作,fmulti-scale(f)为多尺度探头multi-scale block模块对应的输出,wα为5x5卷积层的sa块系数,wβ为3x3卷积层的sa块系数。
27、sa块具体操作过程如公式:
28、
29、||表示沿通道尺寸连接特征映射,r表示sa块的尺度数,每个尺度r是通过进行下采样dr产生的,tr表示一个卷积层操作,ur表示反采样操作符。为更加有效地让模型能够基于通道提取特征图的信息,将senet(压缩和激励网络)引入到残差模块中,resnet50级联senet提升了残差块对通道特征信息的捕捉能力,能够进一步提升轨道交通中落物实体识别的精度。
30、进一步的,步骤5中,原始的resnet50输出层采用softmax的激活函数进行单标签预测,而对轨道交通的落物需要进行多维度分析,需要对分类器进行结构改造。首先先对数据集进行标注,将落物的体积大小、落物的类型及落物距音频传感器的位置分别设置多个标签,例如,可以将落物的体积大小分为“大”,“中”,“小”,可以将落物的类型分为“金属块”,“石块”,“塑料块”,这些都有可能来自车辆部件、轨道设施的碎片或其他物体的碎片,对于落物位于音频传感器的位置可以分为“远”,“近”。然后在堆叠的se-resnet残差块级联一个全局平均化池层,使用贝叶斯分类器链来预测每个标签的概率;
31、预测每个标签的概率时,具体步骤为:以先预测体积大小,然后预测类型,最后预测位置来为每个标签训练一个独立的二分类器,对于每个标签,将前面标签的预测结果作为输入特征来预测当前标签,依次预测每个标签的概率。
32、根据预测的概率,最后添加一个阈值分类器来确定标签的预测结果,分类器的阈值设定采用最大化训练集预测结果macro-f1值的原则进行训练集和测试集的阈值统一设置,用于判断实体是否出现在落物数据集中,具体公式如下:
33、dtrain={(xi,yi)|1≤i≤n},
34、dtest={(xi,yi)|1≤i≤m},
35、
36、采用固定阈值方式对每个标签的预测概率进行拦截输出。xi表示第i个样本的特征,yi是第i个样本输出的标签,yi是第i个样本的模型输出的概率,取0到1;m、n分别是测试数据集和训练数据集的样本数量;dtrain为训练数据集,dtest为测试数据集,f()为多维度落物识别输出预测模型,是采用f()对样本x的预测输出,为训练集通过模型预测的标签集合,ytrain为训练集实际标签集合,t为固定阈值。
37、由于数据集分类的复杂性,需要综合考虑每个标签的识别结果,采用宏平均macro-f1作为模型分类的评价指标,其计算公式为:
38、
39、
40、
41、其中v为标签分类的标签总数,precisionv,recallv分别为第v个标签的精确率和召回率;macro-presision、macro-recall分别为所有标签的平均精确率和平均召回率。实验中对于固定阈值t的选取,是从0开始以步长为0.01递增至1,得到不同阈值下预测输出,选取使得评价指标macro-f1最大的t值作为固定阈值。
42、一种基于声音识别的轨道交通多维度落物分析系统,包括:
43、采集模块:在轨道交通现场部署声音传感器,预采集轨道交通系统现场的声音数据;
44、预处理模块:在边缘端对预采集声音数据进行预处理,并提取预采集声音数据中的音频特征;
45、变换模块:将提取到的音频特征进行cfd变换,生成用于声音识别模型训练的特征向量;
46、模型生成模块:将得到的特征向量,上传至云端,然后在云端基于生成的所述特征向量创建声音识别模型;
47、输出模块:声音识别模型结合多维度落物分析的多标签输出的分类器,分析落物体积大小和实物类型,输出最终识别结果。
48、一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时实现上述的基于声音识别的轨道交通多维度落物分析方法。
49、本发明采用以上技术方案与现有技术相比,具有以下有益效果:
50、(1)本发明基于声音识别的方法可以实时地对轨道上的声音进行分析和识别,及时发现落物并确定位置范围,避免事故的发生。
51、(2)本发明基于声音识别的方法可以从多个角度对轨道上的落物进行分析,不仅可以检测到大型的落物,还可以识别出小型或难以察觉的物体,识别度更高,且不易受到天气条件、光照变化和视野受限等因素的影响,抗干扰性更强,识别更准确,提供更全面的落物监测和分析。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23413.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表