一种声学场景与声音事件联合任务分析方法
- 国知局
- 2024-06-21 11:48:13
本发明涉及声学场景分类和声音事件检测,特别涉及一种基于cross_mmoe模型和class-balanced loss的多任务学习的声学场景与声音事件联合分析方法。
背景技术:
1、多任务学习(multitask learning,mtl)是通过同时学习多个相关联的任务,利用不同任务间丰富的关联信息,达到相互提升任务性能的目标。多任务学习应用范围广泛,从计算机视觉到自然语言处理领域,甚至推荐领域也可以通过采用多任务学习方式进行目标的优化,例如,电商场景的优化目标需要考虑收藏量、加购物车数量、购买量等指标,这些任务之间是有关联的。若采用一个模型来进行多任务学习,不仅节省数据处理、训练、部署的成本,还能提升学习效率和预测准确性。
2、随着现代智能设备的飞速发展,环境声音的自动分析有了更广泛的应用,例如智能驾驶、异常声音检测系统、听力障碍支持系统等。大多数研究分别针对声学场景分类(asc)和声音事件检测(sed)进行分析,但这二者之间有着密切的关系,声音事件信息可以辅助进行声音场景分类,例如,将声音事件信息作为先验信息,可以缩小可能的场景类型的范围。通过结合声音事件信息,可以提升声学场景分类的性能。与标准的单任务学习相比,多任务学习的方法可以从网络结构与损失函数两个角度出发设计,以提升任务性能。模型网络结构的不断创新,解决的是多个任务之间如何最高效的实现参数的共享与分离,让模型既能融合不同任务之间的共性,又能给每个任务提供独立的空间防止干扰。另一个角度是如何优化多任务学习的训练过程,如损失函数的优化。
3、模型方面,在处理asc和sed联合任务问题时,前人多采用传统结构的多任务学习模型,通过使用多任务学习框架中的共享表示,共享领域信息来提高泛化能力。但是类似的多任务学习模型对数据分布差异和任务间关系等因素非常敏感,往往会导致多任务学习的性能比单任务学习差。
4、损失函数方面,多任务学习训练过程中,损失函数的设计也是影响模型表达能力的重要因素。一般来说,损失函数是由不同任务损失加权得到的,损失函数的权重在训练过程中是恒定的或需要手动调整,而模型性能高度依赖于损失函数权重的选择,但搜索最优权重的成本高得令人望而却步,而且很难通过手动调整来解决。尽管采用动态权重自适应方法可以一定程度上改进上述问题,但在模型和数据集通用性方面存在一定的局限性。
5、参考文献
6、[1]y.zhang,and q.yang,“a survey on multi-task learning,”ieeetransactions on knowledge and data engineering,vol.34,no.12,pp.5586-5609,2021;
7、[2]y.hou,b.kang,w.van hauwermeiren et al.,"relation-guided acousticscene classification aided with event embeddings."pp.1-8,2022。
技术实现思路
1、本发明针对现有技术的缺陷,提供了一种声学场景与声音事件联合任务分析方法,通过结合声音事件信息,重点提升声学场景分类的性能。
2、为了实现以上发明目的,本发明采取的技术方案如下:
3、一种声学场景与声音事件联合任务分析方法,其特征在于,包括以下步骤:
4、1)音频特征提取:收集原始音频数据,采用梅尔频谱倒谱系数将原始音频数据转换为音频特征;
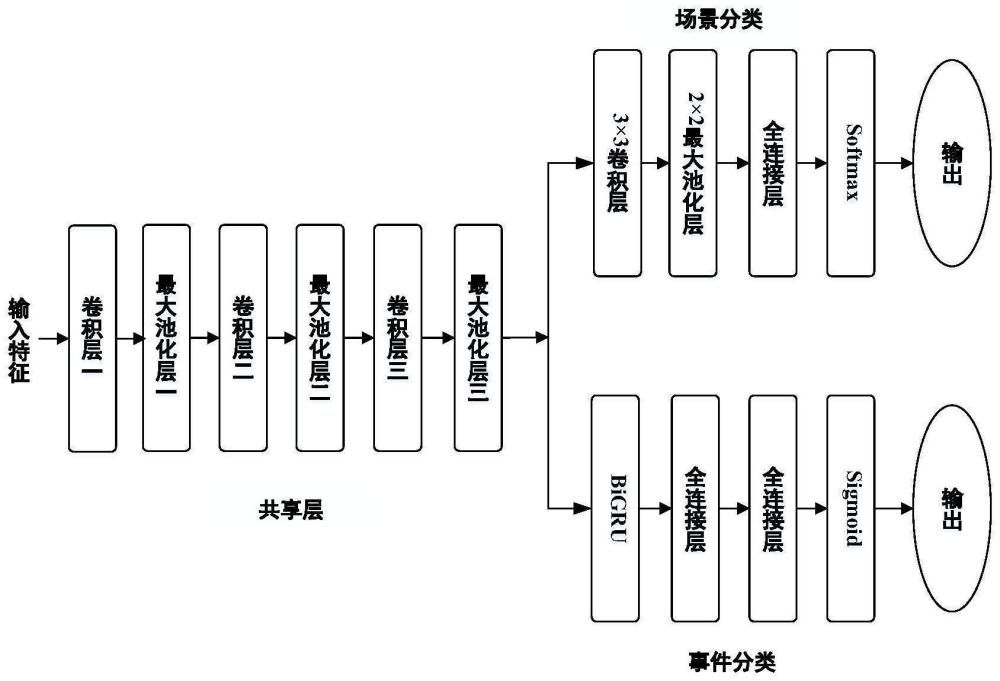
5、2)基线模型构建:构建共享底层网络,包括三组3×3卷积和2×2最大池化层,基线模型中使用crnn模型用于声音事件分类任务分支,基线模型中使用cnn用于声学场景分类任务分支;
6、3)基线模型训练:使用基线模型的结构和参数进行训练;通过输入音频特征,训练模型并进行场景和事件感知能力学习;
7、4)mmoe模型构建:在共享底层网络上使用多个专家网络和门控单元构建mmoe模型的初始版本;mmoe模型中使用crnn模型用于声音事件分类任务分支,mmoe模型中使用cnn用于声学场景分类任务分支;通过实验调整,找到最佳的专家网络数量;
8、5)mmoe模型训练:输入音频特征并对mmoe模型进行训练和优化,进行场景和事件感知能力学习;
9、6)cross_mmoe模型构建和训练:在mmoe模型基础上,增加两条信息交互分支,得到cross_mmoe模型;输入音频特征并对cross_mmoe模型进行训练和优化,进行场景和事件感知能力学习;
10、7)class-balanced loss使用:替换基线模型、mmoe模型和cross_mmoe模型中的交叉熵损失函数为class-balanced loss,进行声学场景分类任务评估;
11、8)评估模型:对基线模型、mmoe模型和cross_mmoe模型进行评估,检查其在声学场景感知任务上的f1值,得到评估结果。
12、进一步地,步骤4)中mmoe模型的底层模型结构包含三个专家网络,每个专家网络是一个前馈网络,为每个任务引入一个门控单元,门控单元通过softmax函数输出不同的权重,将权重与每个专家网络的输出结果进行加权求和,作为声学场景与声音事件两条任务分支的输入;
13、mmoe模型能够明确地对任务关系进行建模,并学习特定于任务的功能以利用共享表示法,允许自动分配参数以捕获共享任务信息或特定于任务的信息。
14、进一步地,步骤6)中将声音事件分类任务分支的输出与共享底层网络的输出相加后作为声音场景分类任务分支的输入,采用同样的方式丰富声音事件分类任务分支的输入信息,增加两个任务间的交互信息。
15、进一步地,步骤7)中使用class-balanced loss替代传统的交叉熵损失函数,引入与有效样本数量成反比的加权因子。
16、进一步地,所述class-balanced loss用以下公式表示:
17、
18、式中,p表示:模型估计的类别概率向量,表示样本属于各个类别的概率。向量长度为c,c是类别总数。
19、y表示:样本的真实标签,属于类别{1,2,…,c}中的一个。
20、表示:第y类数据的有效样本数,表示目标类别的有效样本数量。通过加权因子来计算,加权因子由参数β决定。
21、l(p,y)表示:损失函数。
22、与现有技术相比,本发明的优点在于:
23、1.突破传统多任务学习模型的局限性:首次将mmoe模型引入声学场景和事件感知领域,替代传统的多任务学习模型,增强了处理不同任务的性能,可以提高模型的性能和准确率。mmoe通过引入多个专家网络和门控机制,可以实现自动调整建模共享信息和建模任务特定信息之间的参数化程度,提高模型的表达能力,在一定程度上解决了传统多任务学习模型由于任务差异引起的性能冲突现象。在数据集类别不平衡的情况下,仍能获得较高的准确率,f1值提升至98.74%,相比传统的多任务学习模型提升了1.43%。
24、2.提升模型的性能:在mmoe模型的基础上进行改进,提出一种新的模型结构—cross_mmoe模型,增加了声学场景分类和声音事件分类两个任务分支间的信息交互,在mmoe的基础上进一步提升了两种任务的分类精确率,提高了模型的鲁棒性和泛化能力。
25、3.损失函数改进:结合本发明数据类别不平衡的特点,最终选取class-balancedloss作为改进的方法,cb loss中每个类别的损失权重与其样本数量成反比,可以提升模型对少数类别的关注,动态平衡模型在整个数据集上的表现,实验表明,这种方法在不同模型上都具备优势。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23656.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表