一种集成了MCU和声音控制器的后备箱开关系统的制作方法
- 国知局
- 2024-06-21 11:49:09
本发明涉及语音控制,尤其涉及一种集成了mcu和声音控制器的后备箱开关系统。
背景技术:
1、汽车作为现代生活的重要组成部分,车辆的智能化技术一直备受关注。随着技术的不断发展,车辆的智能控制系统已经涵盖了许多方面,包括车辆的动力系统、安全系统、信息娱乐系统等。后备箱,作为车辆的重要功能之一,也逐渐受到了智能化技术的影响。传统的后备箱开关系统通常采用物理按钮或遥控器,这种方式在一定程度上满足了用户的需求。然而,随着声音识别技术的发展,声音控制成为了一种更为便捷和人性化的操作方式。用户可以通过简单的声音命令来控制后备箱的开启和关闭,而无需触碰按钮或使用遥控器。这在日常生活中尤其对那些双手占用或难以触摸按钮的情况下,提供了额外的便利性和安全性。
2、现有的后备箱开关系统过拟合问题较多,模型准确性差,同时模型开发和部署的复杂性较高;此外,现有的后备箱开关系统语音信号处理的效率和准确性低,系统的计算效率低下,存储需求高,为此,我们提出一种集成了mcu和声音控制器的后备箱开关系统。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺陷,而提出的一种集成了mcu和声音控制器的后备箱开关系统。
2、为了实现上述目的,本发明采用了如下技术方案:
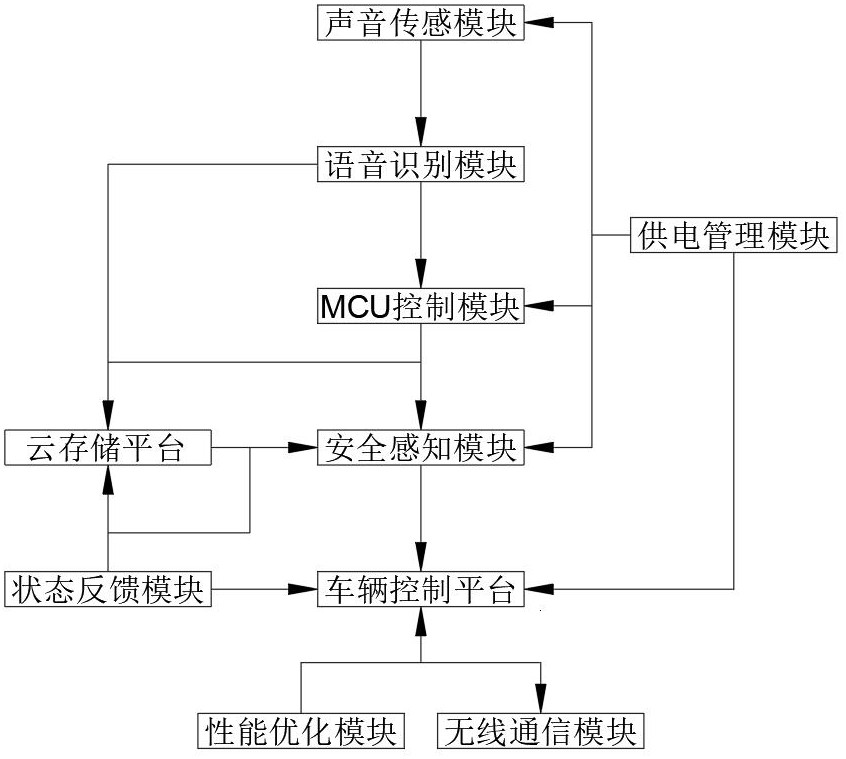
3、一种集成了mcu和声音控制器的后备箱开关系统,包括mcu控制模块、声音传感模块、语音识别模块、无线通信模块、安全感知模块、状态反馈模块、供电管理模块、车辆控制平台、性能优化模块以及云存储平台;
4、所述mcu控制模块用于整体控制和协调各个模块的工作;
5、所述声音传感模块用于采集用户的音频信号,并将其传输给mcu进行分析;
6、所述语音识别模块用于将音频信号转化为文本或命令;
7、所述无线通信模块用于用户通过智能手机应用或远程控制器与系统通信以进行远程操作;
8、所述安全感知模块用于检测打开或关闭后备箱时的安全风险;
9、所述状态反馈模块用于向用户提供后备箱实时状态信息;
10、所述供电管理模块用于监测电池电量并优化电源分配;
11、所述车辆控制平台用于用户手动操作后备箱,以及查看系统状态和交互提示;
12、所述性能优化模块用于实时监控车辆控制平台运行信息,并进行维护调整;
13、所述云存储平台用于记录用户的操作数据以及后备箱的使用情况。
14、其中,所述语音识别模块音频信号转化具体步骤如下:
15、步骤一:语音识别模块收集来自声音传感模块的音频信号,之后估计环境中的噪音以获取噪音信号的特性,再将音频信号按照20毫秒到30毫秒的区间分成时间段或帧;
16、步骤二:通过自适应滤波算法除去每组帧中环境噪音的估计值以获取声音信号,之后确定声音信号的起始和结束点的过程,并利用数字信号处理技术对其进行信号放大,之后通过数字滤波器去除特定频率的环境噪音,同时增强高频部分的声音信号,并从中提取声音特征;
17、步骤三:通过快速傅里叶变换将每组帧的时域信号转换为频域信号,之后使用梅尔滤波器模拟人耳的听觉特性,在频谱上覆盖不同的频率范围,并对每组梅尔滤波器的输出取对数,以模拟人类听觉系统对声音强度的感知;
18、步骤四:对取对数后的梅尔滤波器进行离散余弦变换获得mfcc系数,并通过获取的mfcc系数构建对应特征向量,对各组特征向量进行归一化处理使它们在不同音频帧之间具有一致的尺度,将提取的特征向量将与已知的声音模式进行比对,根据比对结果生成对应文本或命令;
19、所述安全感知模块风险检测具体步骤如下:
20、步骤1:安全感知模块通过多组传感器收集有关后备箱及其周围环境的信息,之后通过高斯滤波去除各组实时信号数据中的噪声并平滑数据,之后计算信号数据集的标准偏差,并依据计算出的标准偏差分别对异常数据进行检测并筛除,并将各组数据进行时间同步;
21、步骤2:从每组传感器的原始数据中提取有用的特征,通过数据融合算法根据传感器提取的特征,将这些特征整合成一个综合的环境感知数据,之后基于综合的数据构建一组环境模型,并确定相关风险指标或标准;
22、步骤3:收集并处理历史风险数据,将各组数据整合归纳成样本数据集,之后按照预设阈值将样本数据集划分为两组特征子集,随机选择一组特征子集,重复进行特征选择和数据集分割,直至决策树的深度达到预定值,将叶子节点的标签确定为该节点中样本数量最多的类别;
23、步骤4:通过递归分裂和叶子节点标签确定,构建出一个完整的决策树,将生成的多组决策树组成随机森林模型,对于每一组数据,选取任意一个子集作为测试集,其余子集作为训练集,训练随机森林模型后,通过测试集进行检测;
24、步骤5:统计检测结果的损失值,再将测试集更换为另一子集,再取剩余子集作为训练集,再次计算损失值,直至对所有数据都进行一次预测,通过选取损失值最小时对应的组合参数作为数据区间内最优的参数并替换随机森林模型原有参数;
25、步骤6:该随机森林模型接收环境模型生成的实时数据以及风险指标,从随机森林模型的根节点开始,根据参数信息的特征条件逐步遍历树的分支,直到达到叶子节点,并将该叶子节点的标签作为检测结果并输出;
26、步骤7:将各组检测结果中存在风险因素的评估结果整合在一起,形成总体的风险评估,并判断该风险级别,若风险评估的结果表明存在风险,系统会触发风险报警,同时自动调整后备箱操作并告知用户。
27、作为本发明的进一步方案,步骤三所述快速傅里叶变换具体计算公式如下:
28、;
29、式中,代表频域中第个频率分量的复数表示;代表时域序列;代表序列的长度;
30、步骤三所述梅尔滤波器具体公式如下:
31、;
32、式中,代表第组梅尔滤波器的输出;代表梅尔刻度下的频率;代表离散频率;
33、步骤四所述离散余弦变换具体计算公式如下:
34、;
35、式中,代表第个dct系数;代表输入的信号或频谱分量。
36、作为本发明的进一步方案,步骤7所述风险因素加权和具体计算公式如下:
37、;
38、式中,代表风险评估得分;代表第个风险因素的权重;代表第个风险因素的值。
39、作为本发明的进一步方案,所述安全感知模块采集的传感器具体包括距离传感器、雷达、力传感器以及光电传感器;同时安全感知模块通过传感器数据检测后备箱的当前状态,包括是否已经打开或关闭,以及后备箱的位置。
40、作为本发明的进一步方案,所述性能优化模块维护调整具体步骤如下:
41、步骤ⅰ:依据管理员预设信息确定系统中被访问的数据以及计算开销的数据以及对应指针结构,并依据数据对象以及指针结构确定链表节点结构,创建一个空链表,同时根据系统内存资源和性能需求设置链表的最大容量;
42、步骤ⅱ:当需要访问数据时,在缓存链表中查找该数据,如果数据存在于链表中,将其移动到链表头部,表示最近使用过,如果数据不在链表中,则从数据库或其他数据源获取数据,并将其添加到链表头部,定期监控链表的长度、缓存命中率以及性能指标;
43、步骤ⅲ:当缓存容量达到上限时,基于最近访问的时间来判断链表中最久未被访问的数据,并将对应数据节点从链表尾部移除并释放资源,同时将链表的头部指针更新到新的头部节点,记录缓存命中率和淘汰操作的次数,并定期监控平台性能。
44、相比于现有技术,本发明的有益效果在于:
45、1、本发明对收集到的各组传感器数据进行预处理后,从每组传感器的原始数据中提取有用的特征,通过数据融合算法根据传感器提取的特征,将这些特征整合成一个综合的环境感知数据,之后基于综合的数据构建一组环境模型,并确定相关风险指标或标准,之后收集并处理历史风险数据,将各组数据整合归纳成样本数据集,再按照预设阈值将样本数据集划分为两组特征子集以构建随机森林模型,该随机森林模型接收环境模型生成的实时数据以及风险指标,从随机森林模型的根节点开始,根据参数信息的特征条件逐步遍历树的分支,直到达到叶子节点,并将该叶子节点的标签作为检测结果并输出,将各组检测结果中存在风险因素的评估结果整合在一起,形成总体的风险评估,并判断该风险级别,若风险评估的结果表明存在风险,系统会触发风险报警,同时自动调整后备箱操作并告知用户,有效减少过拟合问题,提高模型的准确性,同时能够更好地适应现实世界中的不完美情况,且可以提供有关输入特征的重要性评估,模型开发和部署的复杂性低,且能够有效地处理大规模数据集,提高数据处理效率跟风险响应速度。
46、2、本发明收集各组音频信号,之后估计环境中的噪音以获取噪音信号的特性,再将音频信号分成时间段或帧,通过自适应滤波算法除去每组帧中环境噪音的估计值以获取声音信号,之后确定声音信号的起始和结束点的过程,并进行信号放大后通过数字滤波器去除特定频率的环境噪音,同时增强高频部分的声音信号并提取声音特征,将每组帧的时域信号转换为频域信号,之后使用梅尔滤波器模拟人耳的听觉特性,在频谱上覆盖不同的频率范围,并对每组梅尔滤波器的输出取对数,以模拟人类听觉系统对声音强度的感知,对取对数后的梅尔滤波器进行离散余弦变换获得mfcc系数,并通过获取的mfcc系数构建对应特征向量,对各组特征向量进行归一化处理使它们在不同音频帧之间具有一致的尺度,将提取的特征向量将与已知的声音模式进行比对,根据比对结果生成对应文本或命令,能够更好地区分不同声音的频谱特征,提高语音信号处理的效率和准确性,有助于减少处理复杂度,提高系统的计算效率,并降低存储需求,使系统更适应复杂的环境。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23746.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表