基于多任务学习框架的语音情感识别方法、设备及介质
- 国知局
- 2024-06-21 11:50:40
本技术涉及语音情感识别领域,尤其涉及一种基于多任务学习框架的语音情感识别方法、设备及介质。
背景技术:
1、语音情感识别方法主要分为基于传统的和基于深度学习的语音情感识别两部分。语谱图是一种将声音信号可视化为频谱内容的表示方式。语谱图的横轴为时间,纵轴为频率,颜色和亮度表示能量信息。
2、传统的语音情感识别方法侧重于声学特征和语音质量的分析。先将语音信号进行预处理,提取谱特征、韵律特征、音质特征等,一般还需对提取的情感特征进行降维,最后结合机器学习模型,如svm、决策树、knn进行情感分类。传统的情感特征提取由人工完成,但目前常见的方法则倾向于通过深度学习的算法来自动完成情感特征提取,以此避免人工提取情感特征时的巨大不确定性。
3、基于深度学习的语音情感识别方法利用神经网络架构,如cnn、rnn以及lstm等,能够更好地捕获语音数据中的时空特征和长期依赖性。这些方法可以处理更加复杂和抽象的情感表达,通过大规模数据集和深层神经网络结构,提高了情感识别的准确性和泛化能力。然而,它们也对大量标记数据和高计算资源要求较高。
4、现有的语音情感识别方法存在以下问题:
5、1.目前在语音情感识别中,不同情感类别的标记数据仍然存在不平衡和稀缺的问题。一些情感由于数据量较小而得到较少的关注,导致模型对这些情感的识别性能相对较差。
6、2.语音情感识别中,某些情感分类难以清晰区分,存在混淆现象。在这些类别间无法进行有效区分,部分情感识别率低。
7、3.目前多任务学习的语音情感识别存在无法有效地将辅助任务的知识迁移到目标任务上。并且传统模型在新数据上的泛化性能较差,难以适应不同情感类别、不同说话者和不同语境的语音表达。
技术实现思路
1、本发明的目的在于:为了解决上述背景技术中所提到的问题,提供一种可以准确识别语音情感的基于多任务学习框架的语音情感识别方法、设备及介质。
2、本技术的上述目的是通过以下技术方案得以实现的:
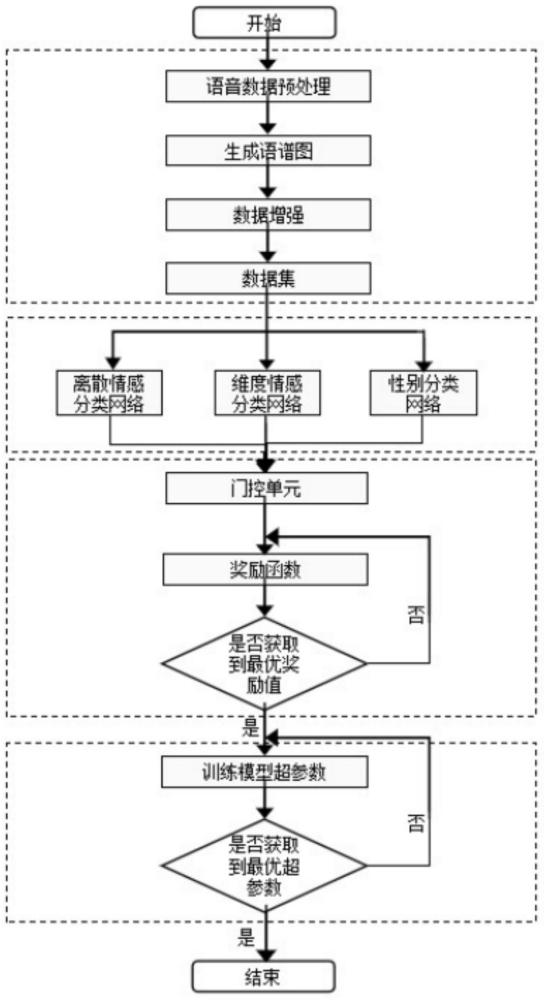
3、s1:获取语音数据并进行预处理,确定语谱图数据集;
4、s2:构建情感分类模型,所述情感分类模型包括:离散情感分类网络、维度情感分类网络、性别分类网络;
5、s3:通过门控机制以及最大化奖励函数,搭建多任务学习框架;
6、s4:通过语谱图数据集确定情感分类模型的超参数;通过语谱图数据集中的训练数据,训练情感分类模型,确定情感分类模型的最优模型参数;
7、s5:获取待识别语音数据,通过训练后的情感分类模型对待识别语音数据进行识别,完成待识别语音数据的情感类别分析。
8、可选的,步骤s1包括:所述预处理包括:数据预处理、语谱图生成以及数据增强,具体步骤如下:
9、数据预处理包括:采样、量化、预加重、加窗;
10、对语音信号进行数据预处理,生成长语谱图;
11、选取固定步长对长语谱图进行裁剪;
12、使用频率掩蔽和时间掩蔽对裁剪后的长语谱图进行数据增强,确定语谱图数据集。
13、可选的,所述离散情感分类网络包括:第一卷积层、第一最大池化层、第二卷积层、第二最大池化层、展平层、信息共享层;所述第一卷积层、第一最大池化层、第二卷积层、第二最大池化层、展平层以及信息共享层依次顺序连接;
14、在所述信息共享层后,连接全连接层与第一网络分支;所述第一网络分支包括:第一反卷积层、第一上采样层、第二反卷积层以及第二上采样层;所述第一反卷积层、第一上采样层、第二反卷积层以及第二上采样层依次顺序连接;所述第一网络分支用于输出重构后的特征图。
15、可选的,所述离散情感分类网络采用softmax激活函数,输出情感类别结果;所述离散情感分类网络采用交叉熵损失函数优化模型l1,如下:
16、
17、式中,m为类别的数量,yic为符号函数,若样本i的真实类别为类别c则取1,否则取0;pic观测样本i属于类别c的预测概率;n表示样本数量。
18、可选的,所述维度情感分类网络包括:卷积层、最大池化层、残差块、多尺度卷积块、拼接层、信息共享层、最大池化层、第一全连接层以及第二全连接层;所述卷积层、最大池化层、残差块、多尺度卷积块、拼接层、信息共享层、最大池化层、第一全连接层以及第二全连接层依次顺序连接;
19、所述残差块包括:主要分支和跳跃连接,主要分支由一系列的卷积层、批量归一化层和激活函数构成;所述残差块通过跳跃连接将上一层的输入直接添加到主要分支的输出上,以使维度情感分类网络学习残差映射;
20、所述多尺度卷积块包括:三个并行的卷积块,三个卷积块分别使用3×3、5×5和7×7大小的卷积核;
21、可选的,所述维度情感分类网络使用线性激活函数输出效价度、激活度和控制度三个维度上的连续值;
22、所述维度情感分类网络使用均方差损失函数优化模型l2,如下:
23、
24、其中,f(x)为预测值,y为目标值;i表示样本的索引;n表示样本数量。
25、可选的,所述性别分类网络包括:金字塔瓶颈块,卷积层、最大池化层、信息共享层、最大池化层、全局注意力块、第一全连接层以及第二全连接层;所述金字塔瓶颈块,卷积层、最大池化层、信息共享层、最大池化层、全局注意力块、第一全连接层以及第二全连接层依次顺序连接;
26、所述金字塔瓶颈块的最上层包括1×1卷积以及bn层;所述金字塔瓶颈块的中间层包括3×3卷积、bn层、relu激活函数、1×1卷积以及bn层;所述金字塔瓶颈块的最下层包括5×5卷积、bn层、relu激活函数、3×3卷积、bn层、relu函数、1×1卷积以及bn层;所述金字塔瓶颈块用于捕获特征图中的局部和全局信息;
27、所述性别分类网络采用交叉熵损失函数优化模型l3,如下:
28、
29、其中,yi表示样本i的标签,yi=1表示男性,yi=0表示女性;pi表示样本i为男性的概率;n表示样本数量。
30、可选的,所述步骤s3包括:
31、s31:对于所述情感分类模型的每个共享编码层的输出,引入门控单元来生成一个介于0和1之间的门控值g,如下
32、g=sig(w×h+b)
33、式中sig表示sigmoid函数,w为门控权重,h为每个任务层的特征表示,b为门控偏置,门控值表示任务对于当前表示的关注程度;
34、s32:设计最大化奖励函数r,如下:
35、
36、式中,accm为主任务离散情感分类的准确率,λ为权重因子,gi为各个辅助任务的门控值,取值范围为[0,1];通过调节权重因子λ平衡主任务准确率和门控值的贡献;较大的λ倾向于强调门控值的影响,而较小的λ更注重主任务准确率的贡献。
37、一种电子设备,包括处理器、存储器、用户接口及网络接口,所述存储器用于存储指令,所述用户接口和网络接口用于给其他设备通信,所述处理器用于执行所述存储器中存储的指令,以使所述电子设备执行一种基于多任务学习框架的语音情感识别方法。
38、一种计算机可读存储介质,所述计算机可读存储介质存储有指令,当所述指令被执行时,执行一种基于多任务学习框架的语音情感识别方法。
39、本技术提供的技术方案带来的有益效果是:
40、1.采用多任务学习框架使得情感分类模型能够同时处理多个相关的任务,通过维度情感分类以及性别分类的特征学习降低易混淆情感分类问题。在多任务学习的框架中,引入门控机制,有效整合各个辅助任务的自编码器网络,门控机制在共享编码层之间动态地控制任务间信息的传递。通过最大化奖励函数,情感分类模型通过调整门控值寻找最大化奖励的策略,学习其他任务的特征,提高共享编码层对整体任务的表示能力,有助于在有限标记数据的情况下更好地利用每个任务的信息,提高对所有情感类别的识别率。
41、2.采用由三个不同卷积大小的卷积块构成多尺度卷积块,提供多尺度的特征表示,增加网络的非线性度,有助于提高模型的性能和泛化能力。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23920.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。