一种深度学习驱动的部分伪造语音数据生成方法
- 国知局
- 2024-06-21 11:51:22
本发明涉及多媒体信息安全与取证,尤其涉及的是一种深度学习驱动的部分伪造语音数据生成方法。
背景技术:
1、语音信号,是一种信息传递载体,是人类社会中信息交流中不可缺少的媒介。语音信号不仅可以相互传递表达的内容,也包含了说话人所蕴含的独特的身份特征,这使得语音信号可以在各种安全访问场景中被用于身份验证,为人们的财产和隐私安全提供有力的保障。随着信息技术的飞速发展,数字语音信号的存储、录制以及传播越来越方便快捷,人们可以轻而易举的从互联网获取大量的数字语音数据。与此同时,各种各样的语音编辑软件如adobe audition等被设计开发出来,使得任何人都可以无门槛的对语音信号进行各种编辑操作。语音编辑软件在极大地丰富了人们娱乐生活的同时,不法分子也可以简单的对数字语音进行伪造和篡改,从而达到不可告人的目的,这可能导致严重的社会安全问题和个人财产损失。但语音编辑软件生成的伪造语音与真实语音具有可识别的听觉差异,且需要大量的目标说话人的语料数据。而随着近年来深度学习技术的不断发展,深度语音合成技术在合成语音的自然度和清晰度方面达到了全新的高度,仅仅从人耳的听觉感知层面已经难以区分真实语音和合成语音的差异,且只需要很少部分的数据即可生成特定说话人音色的语音数据,进一步增加了深度伪造语音所带来的安全隐患,为全球的社会、政治和经济带来严重的威胁。
2、现阶段,大量深度伪造语音检测方法被提出,用以区分真实语音和深度神经网络合成的语音,我们将此类合成的语音称为伪造语音。这些检测方法能够一定程度上对完全真实和完全伪造的语音进行有效的判别,但对部分伪造的语音的检测性能较差。由于部分伪造语音中含有真实语音的数据,这使得此类伪造语音更加难以检测,且对自动说话人验证系统等以语音信号作为验证信息的安全访问系统具有更大的威胁。
3、传统的部分伪造语音通过对真实语音的特定区域用伪造语音片段进行增加、删除或替换的操作,从而得到部分伪造语音,在该传统的部分伪造方式下,伪造人需要两段数据空间独立的同一说话人语音片段才能够生成一段部分伪造语音。并且由于两段源语音数据之间的韵律、声调没有关联性,将导致部分伪造语音在拼接处产生明显的缺陷,如停顿、声调突变等。传统的语音造假方式的缺陷可以从两方面来说。首先是伪造生成方式,简单来说就是找两段同一个说话人的语音,随后通过将它们进行相互拼接来获得伪造语音,但是即使是两段同一说话人的两段语音进行拼接,在拼接处仍然会产生明显的听觉差异,比如突然停顿、语速突然变化、背景噪声不一致等,这是两段语音之间的上下文没有关联性导致的。其次是批量数据生成方式,传统方式通常是基于规则的方法对语音内容做篡改,篡改操作单一,甚至会出现语义逻辑混乱,对于构建部分伪造语音检测系统而言,这类数据不符合真实场景中出现的伪造语音。
4、而随着深度神经网络的生成能力不断提高,一些基于深度神经网络的语音编辑模型被提出,此类模型能够根据上下文信息和文本信息对语音进行编辑,直接生成韵律、声调一致的语音波形,且能够对很小的时间区间做编辑,如对语音中某单词、音节进行编辑。在人们提供便利的同时,这也为不法分子提供了一种全新的伪造篡改方式。其相对于传统的部分篡改方式具有更好的数据和听觉感知层面的一致性,且只需要一段原始语音即可生成具有很小篡改区域的伪造语音数据。该伪造方式具有更强的灵活性,也大大增加了检测难度。因此,对此类伪造数据的检测是亟待解决的现实问题,而此类伪造数据的批量生成是后续构建模型和检测方法的基础。
技术实现思路
1、本发明要解决的技术问题在于,针对现有技术缺陷,本发明提供一种深度学习驱动的部分伪造语音数据生成方法,以解决传统方式无法批量生成上下文一致的伪造语音数据的技术问题。
2、本发明解决技术问题所采用的技术方案如下:
3、第一方面,本发明提供一种深度学习驱动的部分伪造语音数据生成方法,包括:
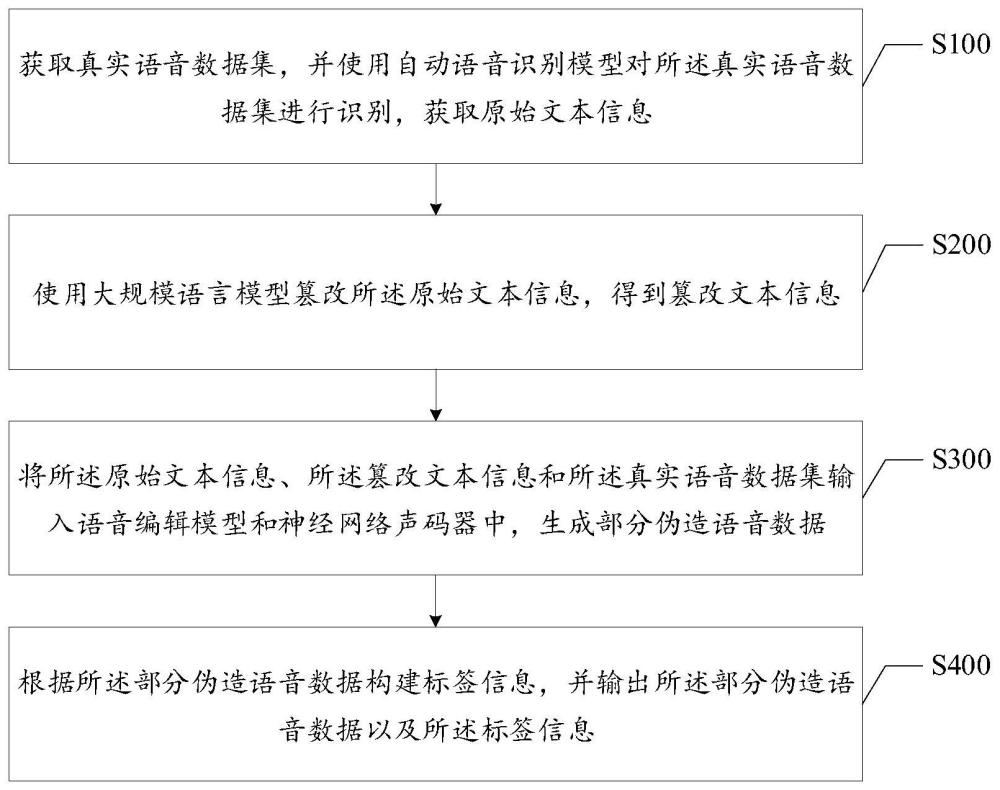
4、获取真实语音数据集,并使用自动语音识别模型对所述真实语音数据集进行识别,获取原始文本信息;
5、使用大规模语言模型篡改所述原始文本信息,得到篡改文本信息;
6、将所述原始文本信息、所述篡改文本信息和所述真实语音数据集输入语音编辑模型和神经网络声码器中,生成部分伪造语音数据;
7、根据所述部分伪造语音数据构建标签信息,并输出所述部分伪造语音数据以及所述标签信息。
8、在一种实现方式中,所述获取真实语音数据集,并使用自动语音识别模型对所述真实语音数据集进行识别,获取原始文本信息,包括:
9、获取真实语音数据,并对所述真实语音数据进行标准化裁剪,得到所述真实语音数据集;
10、将所述真实语音数据集输入到所述自动语音识别模型中,获取与所述真实语音数据集对应的原始文本信息。
11、在一种实现方式中,所述使用大规模语言模型篡改所述原始文本信息,得到篡改文本信息,包括:
12、通过预设的提示语指示所述大规模语言模型,对所述原始文本信息进行篡改;
13、通过替换、删除和添加文本信息的操作改变所述原始文本信息的表达语义和逻辑,得到所述篡改文本信息。
14、在一种实现方式中,所述使用大规模语言模型篡改所述原始文本信息,得到篡改文本信息,之后包括:
15、将所述原始文本信息和对应的篡改文本信息以预设文件格式存储为原始文本信息和篡改文本信息对。
16、在一种实现方式中,所述将所述原始文本信息、所述篡改文本信息和所述真实语音数据集输入语音编辑模型和神经网络声码器中,生成部分伪造语音数据,包括:
17、将所述原始文本信息、所述篡改文本信息和所述真实语音数据集组成三元组输入所述语音编辑模型,通过所述语音编辑模型输出所述篡改文本信息对应的梅尔频谱图;
18、截取篡改区域的梅尔频谱图,输入所述神经网络声码器,生成篡改区域的伪造语音波形;
19、将未篡改区域的真实语音与所述篡改区域的伪造语音波形进行拼接,得到所述部分伪造语音数据。
20、在一种实现方式中,所述根据所述部分伪造语音数据构建标签信息,并输出所述部分伪造语音数据以及所述标签信息,包括:
21、根据所述部分伪造语音数据中各个片段的数据来源制作多时间分辨率的分段级标签、话语级标签和单词级标签,并输出所述部分伪造语音数据以及所述标签信息。
22、在一种实现方式中,所述根据所述部分伪造语音数据中各个片段的数据来源制作多时间分辨率的分段级标签、话语级标签和单词级标签,包括:
23、对所述部分伪造语音数据赋予所述分段级标签,将所述部分伪造语音数据按预设的时间间隔切分成片段,判断切分后的片段是否存在篡改区域,若所述切分后的片段不存在篡改区域,则赋予真实标签,若所述切分后的片段存在篡改区域,则赋予伪造标签;
24、对所述部分伪造语音数据赋予所述话语级标签,判断所述部分伪造语音数据是否存在篡改区域,若所述部分伪造语音数据中存在篡改区域,则赋予所述伪造标签,若所述部分伪造语音数据中不存在篡改区域,则赋予所述真实标签;
25、对所述部分伪造语音数据赋予所述单词级标签,判断所述部分伪造语音数据中各单词是否存在篡改痕迹,从语义层面对所述部分伪造语音数据的单词标注真伪属性,若所述单词存在篡改痕迹,则赋予所述伪造标签,若所述单词为原始单词,则赋予所述真实标签。
26、在一种实现方式中,所述输出所述部分伪造语音数据以及所述标签信息,包括:
27、输出所述部分伪造语音数据以及输出所述部分伪造语音数据携带的所述分段级标签、所述话语级标签和所述单词级标签。
28、第二方面,本发明还提供一种终端,包括:处理器以及存储器,所述存储器存储有深度学习驱动的部分伪造语音数据生成程序,所述深度学习驱动的部分伪造语音数据生成程序被所述处理器执行时用于实现如第一方面所述的深度学习驱动的部分伪造语音数据生成方法的操作。
29、第三方面,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有深度学习驱动的部分伪造语音数据生成程序,所述深度学习驱动的部分伪造语音数据生成程序被处理器执行时用于实现如第一方面所述的深度学习驱动的部分伪造语音数据生成方法的操作。
30、本发明采用上述技术方案具有以下效果:
31、本发明通过获取真实语音数据集,并使用自动语音识别模型对真实语音数据集进行识别,可以获取原始文本信息;使用大规模语言模型篡改所述原始文本信息,从而得到篡改文本信息;将原始文本信息、篡改文本信息和真实语音数据集输入语音编辑模型和神经网络声码器中,可以生成部分伪造语音数据;根据部分伪造语音数据构建标签信息,并输出部分伪造语音数据以及对应的标签信息,从而实现高听觉质量的部分伪造语音的批量生成;本发明提出新的部分伪造语音数据生成的方法,能够基于深度语音编辑技术、大规模语言模型和自动语音识别模型,生成批量上下文一致、多样性丰富、语义逻辑完整的部分伪造语音数据。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24008.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表