一种具有选择性听觉的目标说话人追踪方法及系统
- 国知局
- 2024-06-21 11:52:36
本发明涉及语音识别,特别是指一种具有选择性听觉的目标说话人追踪方法及系统。
背景技术:
1、在多说话人场景中,常常需要从混合的语音信号中准确地跟踪和分离特定的说话人。说话人定位的核心要素是估计说话人相对麦克风阵列的到达方向(doa,direction ofarrival)。通常,说话人定位被视为信号处理问题。信号时延估计算法(gcc-phat)和多信号分类(music)是两种最流行的常规说话人定位算法。然而,传统的基于信号处理的说话人定位方法往往受到环境噪声、语音重叠和说话人变化等因素的干扰,在具有强背景噪声和多说话人同时说话的场景中表现不佳,追踪精度不高。
2、目前,研究人员利用大规模数据集探索了基于深度神经网络(dnn)的方法,以改进多说话人定位算法。这些算法将传统信号处理技术,如gcc-phat和music,与深度神经网络相结合,使传统方法更适合处理多扬声器场景中的问题。其他研究人员还提出了完全基于深度神经网络的解决方案,展示了深度神经网络在多扬声器说话人定位任务中的鲁棒性和效率。
3、然而,现阶段的研究仍然存在一个关键的问题,即由于说话人的顺序不确定性而导致的身份混淆问题。现有方法可以估计所有说话人的doa,但往往难以确定哪个doa属于特定身份的目标说话人。这限制了多说话人定位在实际场景中的应用。
4、一些研究为了解决多目标说话人定位问题,通过特定线索来估算与目标说话人相关的掩码,这些掩码随后在定位算法中用于推导目标说话人的到达方向(doa)。例如,利用目标说话人的参考关键字来估算相关掩码,以便定位该说话人;或者,通过结合目标说话人附近的辅助麦克风与原始麦克风,来估算这些掩码。然而,这些方法在实际应用中受限于特定条件,如参考关键字的可用性或额外麦克风的配置,导致适用性受到限制。
技术实现思路
1、针对上述问题,本发明的目的在于提供一种具有选择性听觉的目标说话人追踪方法及系统,通过预注册的目标说话人语音信息作为参考音频,使算法只关注目标说话人的语音内容,忽视其他背景干扰声,从而实现更精确和可靠的目标说话人追踪。
2、为解决上述技术问题,本发明提供如下技术方案:
3、一方面,提供了一种具有选择性听觉的目标说话人追踪方法,该方法包括以下步骤:
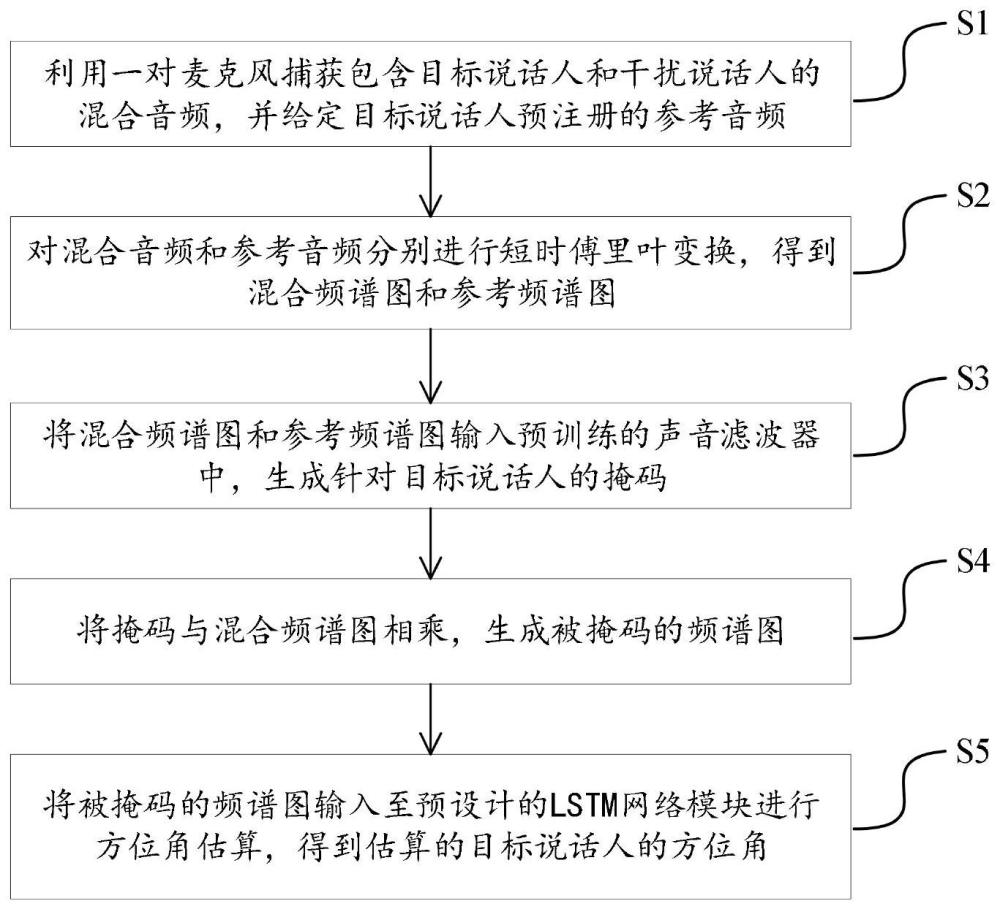
4、s1、利用一对麦克风捕获包含目标说话人和干扰说话人的混合音频,并给定目标说话人预注册的参考音频;
5、s2、对所述混合音频和所述参考音频分别进行短时傅里叶变换,得到混合频谱图和参考频谱图;
6、s3、将所述混合频谱图和所述参考频谱图输入预训练的声音滤波器中,生成针对目标说话人的掩码;
7、s4、将所述掩码与所述混合频谱图相乘,生成被掩码的频谱图;
8、s5、将所述被掩码的频谱图输入至预设计的lstm网络模块进行方位角估算,得到估算的目标说话人的方位角;
9、所述目标说话人的方位角的表达式为公式(1):
10、θt=argmaxpt(θ) (1)
11、其中,pt(θ)是一个函数,表示特定时间t下,声音来自不同角度的后验概率分布,θ是函数pt(θ)的自变量,argmax是一个数学运算用于找出使函数取得最大值的自变量;θt是预测出的概率最高的θ值,为目标说话人的方位角。
12、可选地,所述一对麦克风捕获的混合音频转换的混合频谱图,表示为公式(2):
13、
14、其中,y(t,f)=[y1(t,f),y2(t,f)]t,y(t,f)代表2通道麦克风观察向量,y1(t,f)为第一个麦克风通道捕获的混合音频的向量表示,y2(t,f)为第二个麦克风通道捕获的混合音频的向量表示,t为转置计算符号;t为时间;f为频率;
15、s(t,f)代表目标说话人的纯净语音信号;ak(t,f)代表第k个干扰说话人的语音信号;s(t,f)代表环境噪音信号;k表示干扰说话人的数量。
16、可选地,所述lstm网络模块包括第一全连接层、双向门控循环单元、第二全连接层和sigmoid激活函数,所述lstm网络模块从输入的被掩码的频谱图中估算目标说话人的方位角。
17、可选地,所述第一全连接层通过relu激活函数和批量归一化处理单元对输入数据进行初步处理,并进行特征提取,得到第一特征表示;
18、所述双向门控循环单元捕捉所述第一特征表示中时间序列数据的长期依赖关系和短期依赖关系;
19、所述第二全连接层对所述第一特征表示中时间序列数据的长期依赖关系和短期依赖关系进行提取特征,得到用于方位角估算的第二特征表示,以进行最终的分类任务;
20、所述sigmoid激活函数将所述第二特征表示转换为后验概率,所述后验概率的输出范围是(0,1)。
21、可选地,所述lstm网络模块从输入到输出的整体映射关系描述为公式(3):
22、
23、其中表示构建的lstm网络,ω是lstm网络中的可学习参数,y(t,f)表示由一对麦克风捕获的混合音频转换的混合频谱图,r(t,f)表示生成的目标说话人的掩码。
24、可选地,所述方法还包括:
25、使用平均绝对误差mae和准确率acc来评估所述方法的性能。
26、另一方面,提供了一种具有选择性听觉的目标说话人追踪系统,该系统包括:
27、音频获取模块,用于利用一对麦克风捕获包含目标说话人和干扰说话人的混合音频,并给定目标说话人预注册的参考音频;
28、音频转换模块,用于对所述混合音频和所述参考音频分别进行短时傅里叶变换,得到混合频谱图和参考频谱图;
29、第一生成模块,用于将所述混合频谱图和所述参考频谱图输入预训练的声音滤波器中,生成针对目标说话人的掩码;
30、第二生成模块,用于将所述掩码与所述混合频谱图相乘,生成被掩码的频谱图;
31、预测模块,用于将所述被掩码的频谱图输入至预设计的lstm网络模块进行方位角估算,得到估算的目标说话人的方位角。
32、另一方面,提供了一种电子设备,所述电子设备包括:
33、处理器;
34、存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器加载并执行时,实现如上述目标说话人追踪方法的步骤。
35、另一方面,提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现如上述目标说话人追踪方法的步骤。
36、本发明提供的技术方案带来的有益效果至少包括:
37、(1)实用性
38、环境适应性:本发明的方法考虑了多种环境因素,包括噪声、多扬声器和混响等,能够在各种复杂环境中准确地定位目标说话人,从而具有很高的实用性。
39、多场景应用:本发明的通用性和灵活性使其不仅适用于会议室这种相对静态的环境,还可以广泛应用于家庭助手、机器人导航、公共交通系统以及其他需要声源定位的多变场景。
40、(2)表现性
41、准确性:通过结合深度学习技术和人类的选择性听觉机制,本发明在声源定位的准确性上实现了显著的提升,并且通过与现有技术的对比实验得到了充分的验证。
42、鲁棒性:本发明方法采用了先进的噪声过滤技术,能有效地滤除环境噪声和干扰声音的影响。这意味着即使在低信噪比(snr)或者多干扰声源的条件下,该方法也能保持高水平的性能。
43、(3)同步性
44、实时处理:本发明采用了高效的计算结构和算法优化,使得声源定位几乎可以实时进行。这对于需要快速响应的应用场景(如紧急救援、实时交流等)具有重要意义。
45、数据同步:该方法能够同步处理来自多个麦克风或者传感器的数据,这不仅提高了定位的准确性,也确保了在多麦克风系统中各个传感器数据的时效性和一致性。
46、(4)可控性
47、本发明采用了模块化的设计思路,掩码预测和doa估计是两个独立但协同工作的模块。这样的设计不仅方便了算法的调试和优化,也使得它更容易与其他系统或模块进行集成。
48、(5)扩展性
49、模型适应性:由于采用了模块化的设计,本发明能够轻易地适应不同规模和复杂度的应用场景。例如,可以通过添加更多的网络层或者引入更复杂的算法来提高模型的性能。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24185.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表