一种基于人工智能的电网运维语音交互系统的制作方法
- 国知局
- 2024-06-21 11:54:27
本发明涉及电网运维语音交互,特别涉及一种基于人工智能的电网运维语音交互系统。
背景技术:
1、随着电力行业的不断发展,电网规模不断扩大,运维管理工作变得越来越复杂。传统的运维管理方式存在许多不足,如效率低下、误操作多、信息传递不及时等。随着人工智能技术的不断发展,人机交互已成为日常生活中不可或缺的一部分。传统的交互方式主要依赖于键盘、鼠标等输入设备,无法满足人们对于更自然、更便捷的交互方式的需求。
2、但现有技术中的电网运维语音交互系统还存在以下缺陷:
3、在实际电网运维过程中,由于电网运维现场自身的特殊性,例如机械运转声、电流声以及其他可对语音接收造成影响的环境因素,导致在实际应用过程中运维人员使用语音交互识别的准确性较低,不能将当前接收的语音指令转换成文本,并基于文本中字符分析结果判定语音指令的准确性;
4、同时语音交互系统的智能化程度和互联性较差,不能在语音交互失败的情况下,利用运维现场的摄像装置以及预设的手势指令,进一步实现交互的功能。
5、为此,推出一种基于人工智能的电网运维语音交互系统。
技术实现思路
1、有鉴于此,本发明提供一种基于人工智能的电网运维语音交互系统,以解决上述背景技术提出的问题。
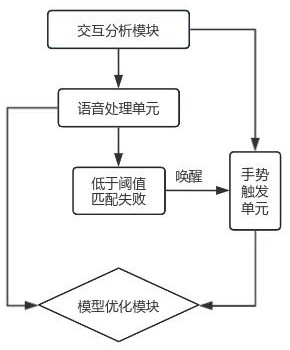
2、本发明的目的可以通过以下技术方案实现:包括交互分析模块和模型优化模块;
3、交互分析模块内设置有语音处理单元和手势触发单元;
4、语音处理单元通过在运维环境中布设的麦克风阵列接收运维人员发出的语音指令并进行初步比对和匹配,在匹配成功后进一步对语音指令的接收误差进行分析,基于分析的结果发出下一步的系统响应,具体步骤为:
5、步骤一:运维人员通过唤醒语音指令对交互系统进行唤醒,并发出相关语音指令;其中相关语音指令包括但不局限于“查询当前电网状态”、“处理电网告警”、“开启3号或关闭3号的设备”、“查询电网历史数据”、“触发变电站检修任务”;
6、步骤二:系统将接收到的语音指令进行录入,并提取当前接收语音指令对应音频的分贝大小,利用声学处理算法计算当前音频的分贝大小,将计算得到的分贝大小与预设的分贝阈值进行比对,若分贝大小大于预设的分贝阈值则判断当前语音指令接收环境太吵需要对声音进行下一步处理,当声音分贝小于阈值则不进行下一步处理,直接对当前语音指令内容的接收误差进行分析;
7、步骤三:当分贝大小大于预设的分贝阈值时,通过抗混叠滤波、模数变换、分帧以及预加重处理步骤,提取出当前声音数据所对应的梅尔-频率倒谱系数、共振峰和过零率三个特征参数,并对提取得到的特征参数进行合并组合,得到完整的声学特征表示;
8、步骤四:利用事先经过训练及搭建好的多位运维人员的声学模型,将提取得到的声学特征与各个模型进行匹配,得出每个模型匹配的概率;提取当前各模型匹配概率中最大的概率值,并将该概率值作为比对数据,与预设的匹配阈值进行比对,若大于预设的匹配阈值,则判断匹配成功,并进一步对当前语音指令内容的接收误差进行分析;若小于预设的匹配阈值,则判断匹配失败,通过系统发出响应“语音指令识别失败,请再说一遍”,同时唤醒手势触发单元内设置的手势识别功能;
9、对当前语音指令内容的接收误差进行分析,具体为:
10、利用语音识别技术将当前接收到的语音指令转换为文本格式,并将转换后的文本格式与多个相关语音指令对应文本进行匹配,得到当前转换文本格式对应匹配程度最高的对应文本;
11、统计当前转换文本格式与匹配对应文本中的差异字数量并标记为a1;分别统计当前转换文本与对应文本的总字数,并标记为a2和a3,基于两者的比对结果,计算不匹配字数的占比值jg;即通过公式计算得到;
12、基于词库的精确分词,对当前转换文本格式和匹配对应文本进行分词处理;
13、按照以下方式对分词后的文本进行单词级别的比对:
14、统计在转化后的文本格式中出现但在匹配对应文本中未出现的单词数量,得到新增值xz;
15、统计在匹配对应文本中出现但在转化后的文本格式中未出现的单词数量,得到删减值xy;
16、统计转化后的文本格式与匹配对应文本中位置对应但内容不一致的单词数量,得到替换值xm;
17、将上述得到的参数代入公式,进行计算得到误况值jm;其中a1、a2以及a3分别为新增值xz、删减值xy以及替换值xm的影响权重因子;
18、计算转化后文本与匹配对应文本之间的levenshtein距离,得到两者之间的差度值jw;具体步骤为:
19、初始化:创建一个(k+1)*(h+1)的矩阵,其中k表示匹配对应文本的长度,h表示转化文本格式的长度;矩阵的行表示匹配对应文本的字符,列表示转化文本格式的字符;
20、填充:将第一行从0到h填充0到h的数;将第一列从0到k填充0到k的数;
21、计算编辑距离:利用动态规划的方法对创建的矩阵进行填充;对于创建矩阵中的每一个位置(t,b),代表匹配对应文本的前t个字符与转化文本的前b个字符之间的编辑距离,基于以下不同情况进行计算:
22、若匹配对应文本的第t个字符与转化文本的第b个字符相同,则该位置的值等于矩阵中上一个位置的值;
23、若匹配对应文本的第t个字符与转化文本的第b个字符不同,则该位置的值等于矩阵中上一个位置的值加1,上一行相邻位置的值加1,上一列相邻位置的值加1中的最小值;
24、得到levenshtein距离:最终创建矩阵右下角的值即为匹配对应文本和转化文本之间的levenshtein距离,代表它们之间的差度值jw;
25、将上述参数中的占比值jg、误况值jm以及差度值jw代入公式,进行计算得到当前语音指令的接收差值jsc;其中f1、f2以及f3分别表示匹配对应文本所允许的最大占比值、最大误况值以及最大差度值;va1、va2以及va3分别为占比值jg、误况值jm以及差度值jw的影响权重因子;
26、将计算得到的接收差值jsc与对应的接收阈值进行比对,若大于对应的接收阈值,则判定当前语音指令接收准确性低,并通过系统发出响应“语音指令识别失败,请再说一遍”,同时唤醒手势触发单元内设置的手势识别功能;
27、若在匹配失败后,运维人员同时比出手势指令和新的语音指令,则分别对两组指令进行分析,并将该两组指令的分析结果进行匹配,若匹配失败,则以手势指令的分析结果为主。
28、手势触发单元通过内置的手势识别功能被唤醒后,提取上述的语音指令相关数据并进行处理,并通过在运维环境内设置的多组摄像装置对定位的运维人员进行捕捉,并对运维人员比出的手势进行实时采集并识别,在识别成功后,基于当前手势指令对应的运维指令执行相应的操作;具体为:
29、利用声源定位技术确定当前语音指令发出的大概位置,并基于该定位结果,锁定距离该定位结果距离最近的运维人员,控制运维环境内的多组摄像装置朝向定位的该运维人员,对该运维人员比出的手势进行识别并分析,具体为:
30、通过多组摄像装置采集该运维人员在手势识别功能唤醒后做出手势的图像信息,选取该运维人员身体朝向所对应摄像装置采集的图像信息,作为分析图像;
31、对该图像进行预处理后进行分割,提取该图像信息中运维人员的手部区域,并对提取后的手部区域进行角度的旋转以及比例的缩放,使其与预设的多组手势图像一致;
32、将调整过后的手部区域图像与多组预设的手势图像进行比对,计算两者之间的重合面积,得到各组面积重合值;选取最大面积重合值所对应的预设手势图像作为概率执行指令;并计算该最大面积重合值与该手部区域图像总面积之间的比值,得到重合比pc;
33、根据得到的重合面积,确定两组图像中重叠的区域,并将该区域从调整过后的手部区域图像中去除,计算去除过后剩余的区域面积,将剩余区域面积与预设的剩余阈值进行比对,基于比对的结果得到不同的权重系数(权重系数一为1.08,权重系数二为1.15),若小于预设的剩余阈值,则自动匹配权重系数一,反之则匹配权重系数二;计算剩余区域面积与该手部区域图像总面积之间的比值,并与对应的权重系数之间相乘计算,得到剩比值pr;
34、将手部区域图像和对应预设手势图像分别标记为r和t,计算两组图像的均值,即各自图像中所有像素值的平均值并标记为r1和t1;利用方差公式分别计算两组图像的方差值,并标记为r2和t2;
35、计算两组图像之间的互相关系数ncc,即通过ncc = \frac{\sum_{x,y}(r(x,y)-r1)*(t(x,y)-t1)}{\sqrt{\sum_{x,y}(r(x,y)-ri)r2}*\sqrt{\sum_{x,y}(t(x,y)-t1)t2}};
36、ncc的值范围在-1到1之间,1表示完全匹配,-1表示完全不匹配,0表示无线性相关性;ncc的值可以用来衡量两幅图像之间的相似度,更接近1表示两幅图像更相似;
37、将上述参数中的重合比pc、剩比值pr以及互相关系数ncc代入公式,进行计算得到手比准值sbz;其中nva、nvb以及nvc分别表示概率执行指令所对应的最低允许重合比、最大允许剩比值以及及格互相关系数;ty1、ty2以及ty3分别为重合比pc、剩比值pr以及互相关系数ncc的影响权重因子;
38、将计算得到的手比准值sbz与对应的手比阈值进行比对,若大于对应的手比阈值,则判定识别成功,直接执行该手势对应指令;若小于对应的手比阈值,则判定识别不成功,同时取消选取的概率执行指令,重新计算各组预设的手势图像与该手部区域图像的手比准值,并与对应的手比阈值进行比对,若没有出现大于手比阈值的,则判定该次对运维人员的手势识别失败;若出现大于手比阈值的,且数量为多组,则选取数值最大作为识别成功指令,此时系统响应此识别成功指令的具体内容,并询问是否执行,即“识别指令为xxx,是否执行”。
39、与现有技术相比,本发明的有益效果是:
40、本发明通过接收运维人员发出的语音指令并进行初步比对和匹配,在匹配成功后进一步对语音指令的接收误差进行分析,利用语音识别技术将当前接收到的语音指令转换为文本格式,并将转换后的文本格式与多个相关语音指令对应文本进行匹配,得到当前转换文本格式对应匹配程度最高的对应文本,基于两者文本之间的分析结果并进行综合,得到当前语音指令的接收差值,从而反映当前接收语音指令与匹配对应文本之间的差异程度,将计算得到的接收差值与对应的接收阈值进行比对,基于比对的结果,执行下一步的响应,避免语音指令被错误的执行,提高了语音指令接收和判定的准确性;
41、本发明基于语音指令比对和匹配结果,对应唤醒手势触发单元内设置的手势识别功能,并提取上述的语音指令相关数据并进行处理,并通过在运维环境内设置的多组摄像装置对定位的运维人员进行捕捉,并对运维人员比出的手势进行实时采集并识别,提高了手势图像采集的准确性;并对当前运维人员手势图像中的重合比、剩比值以及互相关系数综合分析,得到手比准值,基于手比准值的比对结果,执行下一步的操作,从而可以实现语音交互系统与电网运维现场中摄像装置的互联,提高了系统的智能化程度。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24399.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表