一种语音识别的方法、设备以及存储介质与流程
- 国知局
- 2024-06-21 11:55:26
本技术实施例涉及人工智能,具体涉及一种语音识别的方法、设备以及存储介质。
背景技术:
1、基于语音识别(automatic speech recognition,asr)的人机交互技术,是人工智能(artificial intelligence,ai)领域中非常重要的一项技术,被广泛地应用于各种语音识别设备中,如:手机、平板电脑等,以提高目标对象与语音识别设备之间的人机交互效率。在基于共享屏幕进行内容共享的会议场景下,常常需要会议讲演对象向参会对象展示与演说主体相关的材料,包括但不限于幻灯片等文档。
2、然而,对于在共享会议场景下进行语音识别的传统方案,往往是获取会议讲演对象的语音,进而利用语音识别系统对该语音进行识别,以此得到多组可能与该语音相匹配的备选文本。然后,再通过提取共享内容中的文本内容信息、以及图片中的文本描述信息,并利用该文本内容信息和文本描述信息对这匹配出的多组备选文本进行择优选取和纠正处理。换句话说,传统的方案中是加以文本内容信息和文本描述信息从多组备选文本中选取合适的识别结果,本质上是一种对识别结果进行纠错的方案,从而使得语音的识别结果无法贴近实际需求,导致识别结果的准确性较差。
技术实现思路
1、本技术实施例提供了一种语音识别的方法、设备以及存储介质,能够充分考虑了共享会议中的待识别语音、共享文本以及共享图片等多维模态信息,进而准确地识别出待识别语音的识别结果,使得识别结果能够精确地表达出该待识别语音所要表达的内容,提高识别的准确性。
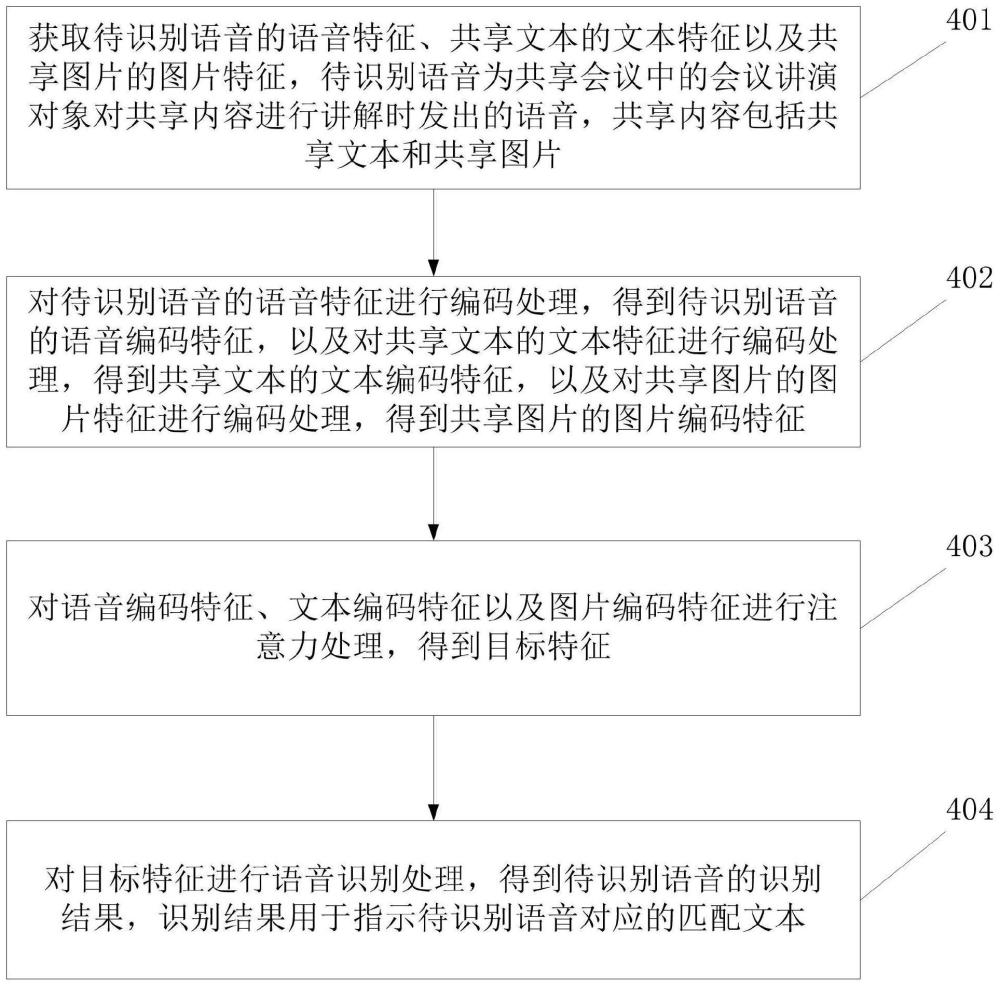
2、第一方面,本技术实施例提供了一种语音识别的方法。该方法包括:获取待识别语音的语音特征、共享文本的文本特征以及共享图片的图片特征,待识别语音为共享会议中的会议讲演对象对共享内容进行讲解时发出的语音,共享内容包括共享文本和共享图片;对待识别语音的语音特征进行编码处理,得到待识别语音的语音编码特征,以及对共享文本的文本特征进行编码处理,得到共享文本的文本编码特征,以及对共享图片的图片特征进行编码处理,得到共享图片的图片编码特征;对语音编码特征、文本编码特征以及图片编码特征进行注意力处理,得到目标特征;对目标特征进行语音识别处理,得到待识别语音的识别结果,识别结果用于指示待识别语音对应的匹配文本。
3、第二方面,本技术实施例提供了一种语音识别设备。该语音识别设备包括获取单元和处理单元。其中,获取单元,用于获取待识别语音的语音特征、共享文本的文本特征以及共享图片的图片特征,待识别语音为共享会议中的会议讲演对象对共享内容进行讲解时的语音,共享内容包括共享文本和共享图片。处理单元,用于:对待识别语音的语音特征进行编码处理,得到待识别语音的语音编码特征,以及对共享文本的文本特征进行编码处理,得到共享文本的文本编码特征,以及对共享图片的图片特征进行编码处理,得到共享图片的图片编码特征;对语音编码特征、文本编码特征以及图片编码特征进行注意力处理,得到目标特征;对目标特征进行语音识别处理,得到待识别语音的识别结果,识别结果用于指示待识别语音对应的匹配文本。
4、在一些可选的实施方式中,处理单元用于:对语音编码特征进行注意力处理,以得到待识别语音的第一注意力特征;对语音编码特征和文本编码特征进行注意力处理,得到待识别语音的第二注意力特征;对语音编码特征和图片编码特征进行注意力处理,得到待识别语音的第三注意力特征;将第一注意力特征、第二注意力特征以及第三注意力特征进行融合处理,得到目标特征。
5、在另一些可选的实施方式中,处理单元用于:通过编码器中的第i层编码层,对第i-1层编码层输出的语音编码特征进行自注意力处理,得到第i层编码层的语音编码特征,其中,1<i≤l,l为自然数,l为编码器的编码层的总层数;通过编码器中的第i层编码层,对第i层编码层的语音编码特征以及第i-1层编码层输出的文本编码特征进行自注意力处理,得到第i层编码层的融合特征向量;通过编码器中的第i层编码层,将第i层编码层的融合特征向量与第i层编码层的语音编码特征进行自注意力处理,得到待识别语音的第二注意力特征。
6、在另一些可选的实施方式中,处理单元用于:基于第i层编码层输出的融合特征向量与预设第一权重矩阵,确定注意力机制中的查询矩阵;基于第i层编码层输出的语音编码特征与预设第二权重矩阵,确定第二注意力模型中的键矩阵,以及基于第i层编码层输出的语音编码特征与预设第三权重矩阵,确定注意力机制中的转置矩阵;基于查询矩阵、键矩阵以及转置矩阵,确定待识别语音的第二注意力特征。
7、在另一些可选的实施方式中,处理单元用于:基于查询矩阵和键矩阵,计算第i层编码层输出的融合特征向量与每个第i层编码层输出的语音编码特征之间的相似度;基于每个相似度与转置矩阵进行加权求和处理,以确定待识别语音的第二注意力特征。
8、在另一些可选的实施方式中,处理单元用于:将目标特征输入至语音识别模型,得到待识别语音中每个词的预测分类概率;基于每个词的预测分类概率确定待识别语音的识别结果。
9、在另一些可选的实施方式中,获取单元用于:获取待识别语音。处理单元用于:将待识别语音输入语音特征提取模型,得到待识别语音的语音特征,其中,语音特征提取模型是以语音样本为训练数据进行训练处理后得到的机器学习模型。
10、在另一些可选的实施方式中,获取单元用于:获取屏幕共享图片,屏幕共享图片用于反映共享内容。处理单元用于:对屏幕共享图片进行图片分割处理,得到第一图片和第二图片,第一图片用于反映述共享文本,第二图片为共享图片;将第一图片输入至文本特征提取模型,得到共享文本的文本特征;将第二图片输入至图片特征提取模型,得到共享图片的图片特征。
11、本技术实施例第三方面提供了一种语音识别设备,包括:存储器、输入/输出(i/o)接口和存储器。存储器用于存储程序指令。处理器用于执行存储器中的程序指令,以执行上述第一方面的实施方式对应的语音识别的方法。
12、本技术实施例第四方面提供了一种计算机可读存储介质,计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行以执行上述第一方面的实施方式对应的方法。
13、本技术实施例第五方面提供了一种包含指令的计算机程序产品,当其在计算机或者处理器上运行时,使得计算机或者处理器执行上述以执行上述第一方面的实施方式对应的方法。
14、从以上技术方案可以看出,本技术实施例具有以下优点:
15、本技术实施例中,由于待识别语音为共享会议中的会议讲演对象对共享内容进行讲解时的语音,共享内容包括共享文本和共享图片,那么在获取到识别语音的语音特征、共享文本的文本特征以及共享图片的图片特征之后,能够对待识别语音的语音特征进行编码处理,得到待识别语音的语音编码特征,以及对共享文本的文本特征进行编码处理,得到共享文本的文本编码特征,以及对共享图片的图片特征进行编码处理,得到共享图片的图片编码特征。这样,再对语音编码特征、文本编码特征以及图片编码特征进行注意力处理,得到目标特征,进而再对目标特征进行语音识别处理,从而得到待识别语音的识别结果,识别结果用于指示待识别语音对应的匹配文本。通过上述方式,不仅充分考虑了共享会议中的待识别语音、共享文本以及共享图片等多维模态信息,而且能够对语音编码特征、文本编码特征以及图片编码特征进行注意力处理,使得后续的语音识别模型能够关注到关键的语音、共享文本以及共享图片,从而摒弃掉无用的信息,使得后续对目标特征进行语音识别处理,能够准确地识别出该待识别语音的识别结果,使得该识别结果能够精确地表达出该待识别语音所要表达的内容,提高识别的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24488.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表