一种基于情绪感知的语音情绪识别方法
- 国知局
- 2024-06-21 11:56:32
本发明属于人工智能计算领域,具体涉及一种基于情绪感知的语音情绪识别方法。
背景技术:
1、情绪识别在智能人机交互系统,特别是自动客户服务系统中起到非常重要的作用。比如,在自动客服系统中,系统需要即时识别用户对话中表露出来的情绪,以便针对情绪采取相应的措施,如当用户感到愤怒时及时进行安抚,这对提升用户体验和应用效率非常重要。如今,智能人机交互系统走向语音化,对语音的情绪识别显得尤为重要。
2、目前,对于文本模态和音频模特的特征大多采用预训练模型进行提取,然而在语音情绪识别任务领域中,这些预训练模型在预训练阶段并未进行过交互,因此其所提取出的特征存在一定的偏差问题。此外,直接套用传统的预训练方法来对语音情绪领域数据进行预训练也存在着一些不足的问题,主要原因在于语音情绪领域的数据中往往会存在大量的情绪词,这些情绪词信息则可以帮助模型更好的捕获语句的情绪信息,而传统预训练方法则是忽略了对这些情绪词的挖掘。
3、现有的语音情绪识别方法主要是通过机器识别将语音数据先转换为文本,再对文本采用基于文本的情绪识别方法进行情绪识别。然而这种识别方法将语音数据转换为文本,基于文本进行情绪识别,仅利用了语音数据中文本信息所反映的情绪信息,损失了语音数据中的非文本情绪信息,使得情绪识别效果差。
技术实现思路
1、为解决以上现有技术存在的问题,本发明提出了一种基于情绪感知的语音情绪识别方法,该方法包括:获取待识别的语音数据,将待识别的语音数据输入到训练后的语音情绪识别模型中,得到语音情绪识别结果;
2、对语音情绪识别模型进行训练包括:获取预训练数据集和微调数据集,预训练数据集中包括原始音频序列和原始音频对应的原始文本;采用基于情绪词掩码策略对原始文本序列进行遮蔽,得到遮蔽后的文本序列;将遮蔽后的文本序列和原始音频序列输入到语音情绪识别模型中进行预训练;将微调数据集中的数据输入到预训练后的语音情绪识别模型中进行微调,得到最终的训练好的语音情绪识别模型。
3、本发明的有益效果:
4、本发明利用情绪感知交互层中的相对位置嵌入层、相对位置类型嵌入层为文本编码特征赋予了情绪词的相对位置信息和相对位置类型信息;利用情绪感知交互层中的情绪交互层和情绪融合层把情绪词信息注入到文本全局信息来进行感知增强;利用基于情感词的掩码预训练策略,动态调整句子之间情绪词和非情绪词的mask概率,使得预训练期间模型更侧重于对语句当中情绪词的理解;利用对比学习层使得不同情绪样本对之间的在空间中的嵌入距离更具区分性,即缩小相同情绪样本对之间的嵌入距离,适度地缩小相似情绪样本对之间的嵌入距离,最后扩大不同情绪样本对之间的嵌入距离,通过这种方式进一步提升了文本和音频模特的全局特征表示。
技术特征:1.一种基于情绪感知的语音情绪识别方法,其特征在于,包括:获取待识别的语音数据,将待识别的语音数据输入到训练后的语音情绪识别模型中,得到语音情绪识别结果;
2.根据权利要求1所述的一种基于情绪感知的语音情绪识别方法,其特征在于,采用基于情绪词掩码策略对原始文本序列进行遮蔽包括:获取原始文本序列t={x1,x2...,xn},计算文本序列中情绪词xi被mask的概率,计算文本序列中非情绪词被mask的概率;根据情绪词与非情绪词被mask的概率对原始文本序列进行遮蔽,得到遮蔽后的文本序列
3.根据权利要求2所述的一种基于情绪感知的语音情绪识别方法,其特征在于,文本序列中情绪词xi被mask的概率为:
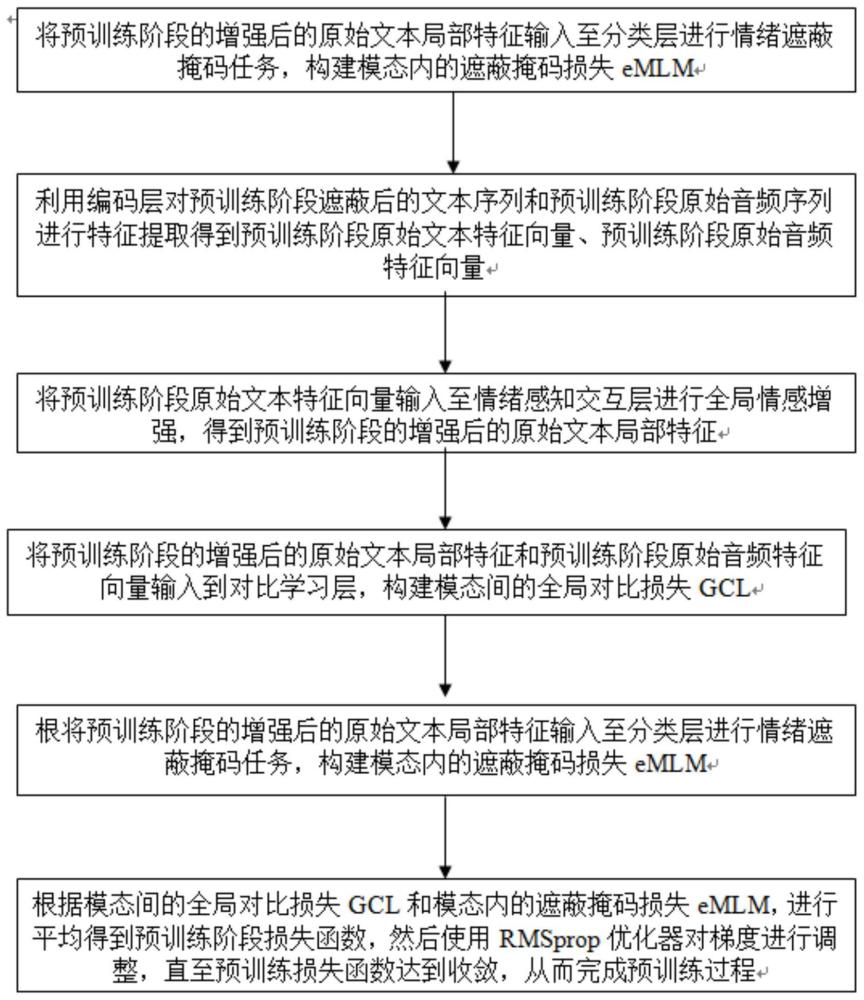
4.根据权利要求1所述的一种基于情绪感知的语音情绪识别方法,其特征在于,将遮蔽后的文本序列和原始音频序列输入到语音情绪识别模型中进行预训练包括:语音情绪识别模型包括编码层、情绪感知交互层、对比学习层以及分类层;将遮蔽后的文本序列和原始音频输入到编码层中进行特征提取,得到原始文本特征向量和原始音频特征向量;将原始文本特征向量输入至情绪感知交互层进行全局情感增强,得到增强后的原始文本局部特征;将增强后的原始文本局部特征和原始音频特征向量输入到对比学习层中,构建模态间的全局对比损失gcl;将增强后的原始文本局部特征输入至分类层进行情绪遮蔽掩码任务学习,并构建模态内的遮蔽掩码损失emlm;根据模态间的全局对比损失gcl和模态内的遮蔽掩码损失emlm构建模型预训练阶段损失函数,并采用rmsprop优化器对梯度进行调整,直至预训练损失函数达到收敛,从而完成预训练过程。
5.根据权利要求4所述的一种基于情绪感知的语音情绪识别方法,其特征在于,编码层对遮蔽后的文本序列和原始音频进行特征提取包括:采用speechbert预训练模型对原始语音的原始文本进行编码,得到原始文本特征向量;将原始音频中静音部分进行剪切,采用滤波器对音频中非人声的噪音部分进行消除,利用librosa库提取原始音频序列,并进行16khz采样后输入到wav2vec2.0模型中,得到编码后的音频特征向量a=[e1,e2...,em],其中m为音频序列长度。
6.根据权利要求4所述的一种基于情绪感知的语音情绪识别方法,其特征在于,情绪感知交互层包括相对位置嵌入层、相对位置类型嵌入层、情绪交互层和情绪融合层;根据编码后的文本特征向量获取情绪词ei的所有同义词编码向量si=[cls1,cls2...clsk];计算非情绪词ej相对于情绪词ei的相对位置信息;计算非情绪词ej相对于情绪词ei的相对位置类型信息;对相对位置信息和相对位置类型进行编码,得到对应的相对位置编码信息θrel_pos(i,j)和相对位置类型编码信息ωrel_type(i,j);将相对位置编码信息和相对位置类型编码信息融入进编码后的文本特征向量,得到增强位置信息后的文本局部特征向量;采用交叉注意力机制对增强位置信息后的文本局部特征向量以及情绪词进行交叉计算,得到融合同义词的特征向量取每个情绪词ei所属的情绪类别相应的权重,采用加权平均方法来确定融合同义词特征向量的全局特征表示;将所有情绪词的同义词融合特征向量的全局特征表示进行平均池化,再融入编码后文本特征向量e=[cls,e1,e2...,en]的全局cls特征中,得到全局情绪增强后的原始文本特征向量
7.根据权利要求4所述的一种基于情绪感知的语音情绪识别方法,其特征在于,对增强后的原始文本局部特征和原始音频特征向量进行对比学习包括:将全局情绪增强后的原始文本特征向量中的全局文本特征向量作为文本模态的全局特征向量;编码后的音频特征向量a=[e1,e2...,em]的平均池化特征audiocls=meanpooling(a)作为音频模态的全局特征向量,构建模态间的全局对比损失gcl。
8.根据权利要求7所述的一种基于情绪感知的语音情绪识别方法,其特征在于,全局对比损失gcl的表达式为:
9.根据权利要求4所述的一种基于情绪感知的语音情绪识别方法,其特征在于,模态内的遮蔽掩码损失emlm为:
10.根据权利要求1所述的一种基于情绪感知的语音情绪识别方法,其特征在于,对预训练后的语音情绪识别模型中进行微调包括:将预训练后的语音情绪识别模型权重作为微调的初始权重;将微调数据集中的数据输入到编码层进行特征提取,得到微调阶段原始文本特征向量、微调阶段原始音频特征向量;将微调阶段原始文本特征向量输入至情绪感知交互层进行全局情感增强,得到微调阶段的增强后的原始文本局部特征;将微调阶段的增强后的原始文本局部特征和微调阶段原始音频特征向量输入至分类层,根据预测结果和样本集中原始音频对应的情绪类构建情绪识别任务损失函数ser;根据情绪识别任务损失函数ser使用rmsprop优化器对梯度进行调整,直至绪识别任务损失函数达到收敛,从而完成微调过程。
技术总结本发明属于人工智能计算领域,具体涉及一种基于情绪感知的语音情绪识别方法,包括:获取预训练数据集和微调数据集,预训练数据集中包括原始音频序列和原始音频对应的原始文本;采用基于情绪词掩码策略对原始文本序列进行遮蔽,得到遮蔽后的文本序列;将遮蔽后的文本序列和原始音频序列输入到语音情绪识别模型中进行预训练;将微调数据集中的数据输入到预训练后的语音情绪识别模型中进行微调,得到最终的训练好的语音情绪识别模型;本发明利用情绪感知交互层中的相对位置嵌入层、相对位置类型嵌入层为文本编码特征赋予了情绪词的相对位置信息和相对位置类型信息。技术研发人员:王进,向严,范浩然,袁鑫浩,刘彬受保护的技术使用者:重庆邮电大学技术研发日:技术公布日:2024/6/5本文地址:https://www.jishuxx.com/zhuanli/20240618/24620.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表