演说的动态评估方法、装置、系统、电子设备及存储介质与流程
- 国知局
- 2024-06-21 11:58:24
所属的技术人员可以清楚地了解到,为方便的描述和简洁,上述描述的装置的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。进一步的,本技术实施例还提供了一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述实施例所述的演说的动态评估方法。进一步的,本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行程序,所述计算机可执行程序用于使计算机执行如上述实施例所述的演说的动态评估方法。本领域内的技术人员应明白,本技术的实施例还可提供包括计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。本技术是参照根据本技术实施例的方法、设备(系统)、装置和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。以上所述仅是本发明的优选实施方式,应当指出,对于本的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
背景技术:
1、随着经济与互联网技术的迅速发展,线上的直播销售、会议沟通以及线下的演说宣传等活动越来越多。而信息的快速海量传播蕴含着巨大的能量和信息价值,因此,对其进行信息分析或挖掘,具有重要的意义和价值。
2、针对海量的文本信息数据,目前常用的文本信息分析方法是:利用文本转换算法将音频或视频数据转换成文本信息;利用浅层的机器学习模型(如支持向量机(svm)或决策树)对音频或视频数据进行声音的语调进行评估;结合语调的评估结果来分析文本信息的内容。
3、但目前常用的方法有如下技术问题:演说及直播的环境多种多样,可能存在多种因素导致音视频的声量及语调发送变化,而单一的语调分析难以适配不同的应用场景,而且上述浅层学习模型对海量复杂数据评估分析的准确率较低,导致分析结果与实际的偏差较大。
技术实现思路
1、本发明提出一种演说的动态评估方法、装置、系统、电子设备及存储介质,所述方法可以解决一个及多个技术问题。
2、本发明实施例的第一方面提供了一种演说的动态评估方法,所述方法包括:
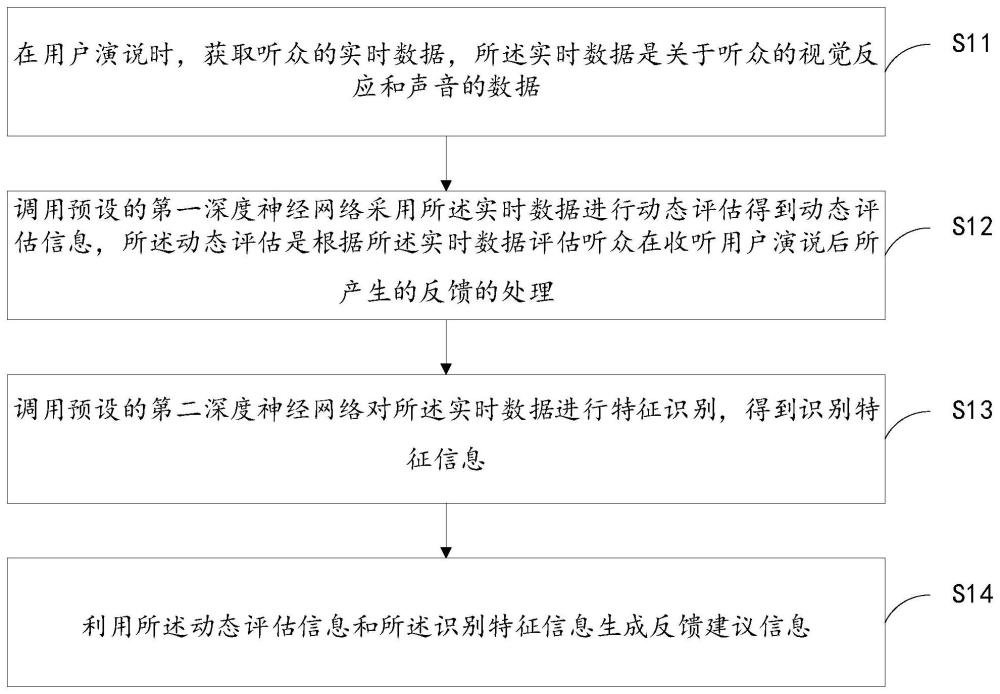
3、在用户演说时,获取听众的实时数据,所述实时数据是关于听众的视觉反应和声音的数据;
4、调用预设的第一深度神经网络采用所述实时数据进行动态评估得到动态评估信息,所述动态评估是根据所述实时数据评估听众在收听用户演说后所产生的反馈的处理。
5、在第一方面的一种可能的实现方式中,所述调用预设的第一深度神经网络包括:用于进行情感评估的评估神经网络和用于进行情感追踪的追踪神经网络;
6、所述调用预设的自适应深度神经网络采用所述实时数据进行动态评估得到动态评估信息,包括:
7、调用所述评估神经网络从所述实时数据提取特征数据,所述特征数据是听众的视觉数据、音频数据和用户的演说数据;
8、对所述特征数据进行加权融合形成融合特征数据后,调用所述评估神经网络对所述融合特征数据进行情感评估得到情感评估数据;
9、在融合所述情感评估数据和所述融合特征数据得到情感融合数据后,调用所述追踪神经网络对所述情感融合数据进行情绪识别得到动态评估信息。
10、在第一方面的一种可能的实现方式中,所述评估神经网络和所述追踪神经网络的训练流程,包括:
11、获取不同场景的多模态数据集,所述多模态数据集包括:视觉数据、音频数据、文本数据和口才维度标签数据;
12、采用所述多模态数据集分别训练自适应深度神经网络和长短期记忆网络,分别得到第一训练网络和第二训练网络;
13、对所述第一训练网络进行自适应测试后得到评估神经网络,以及,采用预设的时间序列数据集对所述第二训练网络完成优化后得到追踪神经网络,所述预设的时间序列数据集是利用口才维度特征进行标注的数据集。
14、在第一方面的一种可能的实现方式中,所述获取听众的实时数据,包括:
15、调用摄像头获取听众的视觉数据以及调用麦克风获取听众的音频数据;
16、分别对所述视觉数据进行视觉优化处理以及对所述音频数据进行音频优化处理得到优化数据后,对所述优化数据进行数据标准化处理,得到实时数据。
17、在第一方面的一种可能的实现方式中,所述视觉优化处理,包括:
18、对所述视觉数据进行剔除模糊图像、对比度调整和光照校正;
19、所述音频优化处理,包括:
20、对所述音频数据进行滤波和降噪处理。
21、在第一方面的一种可能的实现方式中,在所述调用预设的第一深度神经网络采用所述实时数据进行动态评估得到动态评估信息的步骤后,所述方法还包括:
22、调用预设的第二深度神经网络对所述实时数据进行特征识别,得到识别特征信息;
23、利用所述动态评估信息和所述识别特征信息生成反馈建议信息。
24、本发明实施例的第二方面提供了一种演说的动态评估装置,所述装置包括:
25、数据获取模块,用于在用户演说时,获取听众的实时数据,所述实时数据是关于听众的视觉反应和声音的数据;
26、动态评估模块,用于调用预设的第一深度神经网络采用所述实时数据进行动态评估得到动态评估信息,所述动态评估是根据所述实时数据评估听众在收听用户演说后所产生的反馈的处理。
27、在第二方面的一种可能的实现方式中,所述调用预设的第一深度神经网络包括:用于进行情感评估的评估神经网络和用于进行情感追踪的追踪神经网络;
28、所述调用预设的自适应深度神经网络采用所述实时数据进行动态评估得到动态评估信息,包括:
29、调用所述评估神经网络从所述实时数据提取特征数据,所述特征数据是听众的视觉数据、音频数据和用户的演说数据;
30、对所述特征数据进行加权融合形成融合特征数据后,调用所述评估神经网络对所述融合特征数据进行情感评估得到情感评估数据;
31、在融合所述情感评估数据和所述融合特征数据得到情感融合数据后,调用所述追踪神经网络对所述情感融合数据进行情绪识别得到动态评估信息。
32、在第二方面的一种可能的实现方式中,所述评估神经网络和所述追踪神经网络的训练流程,包括:
33、获取不同场景的多模态数据集,所述多模态数据集包括:视觉数据、音频数据、文本数据和口才维度标签数据;
34、采用所述多模态数据集分别训练自适应深度神经网络和长短期记忆网络,分别得到第一训练网络和第二训练网络;
35、对所述第一训练网络进行自适应测试后得到评估神经网络,以及,采用预设的时间序列数据集对所述第二训练网络完成优化后得到追踪神经网络,所述预设的时间序列数据集是利用口才维度特征进行标注的数据集。
36、在第二方面的一种可能的实现方式中,所述获取听众的实时数据,包括:
37、调用摄像头获取听众的视觉数据以及调用麦克风获取听众的音频数据;
38、分别对所述视觉数据进行视觉优化处理以及对所述音频数据进行音频优化处理得到优化数据后,对所述优化数据进行数据标准化处理,得到实时数据。
39、在第二方面的一种可能的实现方式中,所述视觉优化处理,包括:
40、对所述视觉数据进行剔除模糊图像、对比度调整和光照校正;
41、所述音频优化处理,包括:
42、对所述音频数据进行滤波和降噪处理。
43、在第二方面的一种可能的实现方式中,所述装置还包括:
44、特征识别模块,用于调用预设的第二深度神经网络对所述实时数据进行特征识别,得到识别特征信息;
45、反馈模块,用于利用所述动态评估信息和所述识别特征信息生成反馈建议信息。
46、本发明实施例的第三方面提供了一种演说的动态评估系统,所述系统包括:集成数据预处理模块、优化深度学习分析模块和反馈生成模块;
47、所述集成数据预处理模块,用于对听众进行数据采集、数据清洗和数据标准化;
48、所述优化深度学习分析模块,用于根据所述集成数据预处理模块处理的数据进行情感分析和情感追踪;
49、所述反馈生成模块,用于根据所述优化深度学习分析模块的分析和追踪结果生成演说建议。
50、相比于现有技术,本发明实施例提供的一种演说的动态评估方法、装置、系统、电子设备及存储介质,其有益效果在于:本发明可以在用户演说时,获取听众的实时数据,包括听众的视觉反应和声音的数据;再调用预设的第一深度神经网络采用实时数据进行动态评估得到动态评估信息,通过动态评估可以确定听众在收听用户演说后所产生的反馈,从而根据听众的反馈确定演说的效果,以实现评估的目的。一方面本发明是结合听众的视觉与声音进行综合评估,增加评估指标,以适配不同的演说场景,另一方面可以结合实时反应的数据,提升评估的精度和时效性,以降低评估的偏差。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24808.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表