多云资源调度方法、装置、存储介质及程序产品与流程
- 国知局
- 2024-07-31 22:37:59
本申请涉及云计算,具体涉及一种多云资源调度方法、装置、存储介质及程序产品。
背景技术:
1、云计算是一种基于网络的计算模型,它允许用户通过互联网访问和共享计算资源(包括服务器、存储、数据库、网络、软件等),而无需拥有或维护自己的物理硬件和软件基础设施。这一模型的灵活性、可伸缩性通常不仅使用单一云服务提供商,而是选择采用多云架构。这种架构允许工作负载分布在多个不同的云平台上,包括公有云、私有云和混合云环境。多云架构为企业提供了更大的灵活性和选择权,使他们能够根据具体需求和用例来利用不同云平台的资源和服务。在多云环境中,资源调度至关重要。这是因为多云架构可能涉及到不同云平台之间的资源分配,包括虚拟、有效的、存储、网络等。有效的资源调度可以帮助企业实现多个关键目标,包括提高资源利用率、降低成本、确保应用程序性能、保证合规性和安全性,以及适应不断变化的工作负载需求。
2、在多云环境中,资源调度是关键,它影响效率、负载均衡和性能。传统方法如遗传算法、模拟退火虽可优化资源,但在动态、复杂的多云场景中表现不佳,搜索效率低,计算复杂度高。基于规则的调整策略适用于静态、简单场景,但在自适应决策和负载均衡上有局限。基于机器学习预测模型虽可预测未来负载,助于资源分配,但可能无法应对复杂的多变环境,预测结果可能会受到数据噪音和突发事件的影响,导致预测结果不准确,且不一定适合自适应环境。容器编排工具简化资源管理,但其策略预设,智能性低。
技术实现思路
1、本申请的至少一个实施例提供了一种多云资源调度方法、装置、存储介质及程序产品,用于解决现有技术中资源调度自适应能力差的问题。
2、为了解决上述技术问题,本申请是这样实现的:
3、第一方面,本申请实施例提供了一种多云资源调度方法,包括:
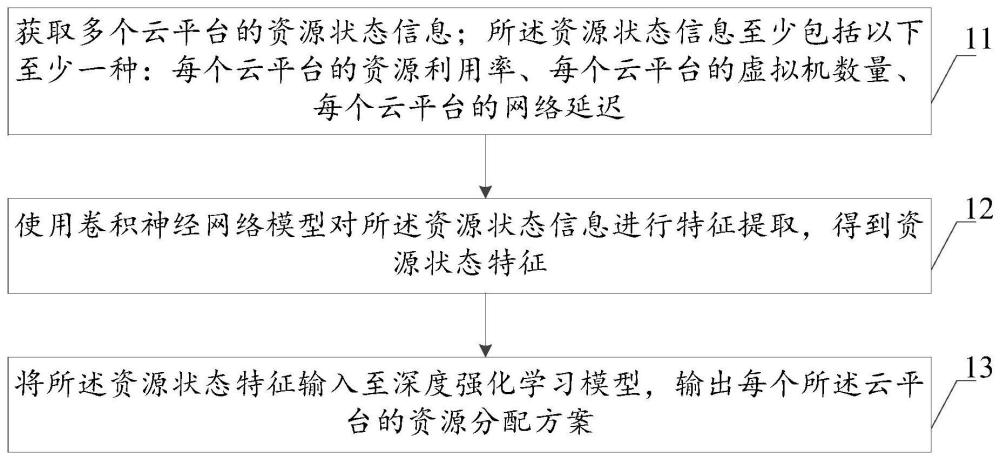
4、获取多个云平台的资源状态信息;所述资源状态信息至少包括以下至少一种:每个云平台的资源利用率、每个云平台的虚拟机数量、每个云平台的网络延迟;
5、使用卷积神经网络模型对所述资源状态信息进行特征提取,得到资源状态特征;
6、将所述资源状态特征输入至深度强化学习模型,输出每个所述云平台的资源分配方案。
7、可选地,使用卷积神经网络模型对所述资源状态信息进行特征提取,得到资源状态特征,包括:
8、对所述资源状态信息中的所述资源利用率和所述虚拟机数量进行数据组合,构成一个图像矩阵;所述图像矩阵的行或列表示不同时间点或检测周期;所述图像矩阵的值表示所述资源利用率或所述虚拟机数量;
9、将所述图像矩阵输入至所述卷积神经网络模型,通过所述卷积神经网络的卷积和池化操作,得到一个预设维度的向量表示,并利用所述卷积神经网络对所述向量表示执行全局平均池化处理,得到所述资源状态特征。
10、可选地,将所述资源状态特征输入至深度强化学习模型,输出每个所述云平台的资源分配方案,包括:
11、将所述资源状态特征输入至深度强化学习模型,输出每个所述云平台的动作概率分布信息;
12、根据所述动作概率分布信息,选择对应的动作,确定每个所述云平台的资源分配方案。
13、可选地,将所述资源状态特征输入至深度强化学习模型,输出每个所述云平台的资源分配方案后,还包括:
14、根据所述资源分配方案,对相关云平台执行对应的动作;
15、在执行所述动作后,获取每个云平台反馈的下一个时间步的第一状态信息和用于指示决策优化的奖励信号;
16、根据所述第一状态信息和所述奖励信号,对所述深度强化学习模型进行更新,得到更新后的目标模型。
17、可选地,获取用于指示决策优化的奖励信号,包括:
18、获取所述云平台的优化目标;
19、根据所述优化目标,确定用于优化的正向奖励函数和用于惩罚的负向奖励函数,其中,所述正向奖励函数与所述优化目标的优化方向正相关,所述负向奖励函数与所述优化目标的优化方向负相关;
20、根据所述正向奖励函数和所述负向奖励函数,确定所述奖励信号。
21、可选地,根据所述第一状态信息和所述奖励信号,对所述深度强化学习模型进行更新,得到更新后的目标模型,包括:
22、根据所述奖励信号,对所述深度强化学习模型中行动者actor网络进行更新,确定更新后的actor网络;
23、根据所述第一状态信息,对所述深度强化学习模型中评价critic网络的权重进行更新,确定更新所述critic网络;
24、根据更新后的actor网络和更新后的critic网络,得到更新后的目标模型。
25、可选地,所述深度强化学习模型中actor网络和critic网络共用输入层和隐藏层的参数;
26、通过所述actor网络的输出层结合归一化指数激活函数,确定所述actor网络输出的每个动作所对应的概率总和为1。
27、第二方面,本申请实施例提供了一种多云资源调度装置,包括:
28、第一获取模块,用于获取多个云平台的资源状态信息;所述资源状态信息至少包括以下至少一种:每个云平台的资源利用率、每个云平台的虚拟机数量、每个云平台的网络延迟;
29、第一处理模块,用于使用卷积神经网络模型对所述资源状态信息进行特征提取,得到资源状态特征;
30、第二处理模块,用于将所述资源状态特征输入至深度强化学习模型,输出每个所述云平台的资源分配方案。
31、第三方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的方法的步骤。
32、第四方面,本申请实施例提供了一种计算机程序产品,包括计算机指令,所述计算机指令被处理器执行时实现如上所述的方法的步骤。
33、与现有技术相比,本申请实施例提供的多云资源调度方法、装置、存储介质及程序产品,从多个云平台收集资源状态:收集每个云平台的资源利用率、虚拟机数量、网络延迟中至少一种资源状态信息,使用卷积神经网络模型对资源状态信息进行特征提取,得到资源状态特征;将资源状态特征输入至深度强化学习模型,输出每个所述云平台的资源分配方案,本申请利用卷积神经网络模型和深度强化学习模型来实现多云资源的智能调度,提高调度的实时性和动态性。
技术特征:1.一种多云资源调度方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,使用卷积神经网络模型对所述资源状态信息进行特征提取,得到资源状态特征,包括:
3.根据权利要求1所述的方法,其特征在于,将所述资源状态特征输入至深度强化学习模型,输出每个所述云平台的资源分配方案,包括:
4.根据权利要求1所述的方法,其特征在于,将所述资源状态特征输入至深度强化学习模型,输出每个所述云平台的资源分配方案后,还包括:
5.根据权利要求4所述的方法,其特征在于,获取用于指示决策优化的奖励信号,包括:
6.根据权利要求4所述的方法,其特征在于,根据所述第一状态信息和所述奖励信号,对所述深度强化学习模型进行更新,得到更新后的目标模型,包括:
7.根据权利要求1所述的方法,其特征在于,所述深度强化学习模型中actor网络和critic网络共用输入层和隐藏层的参数;
8.一种多云资源调度装置,其特征在于,包括:
9.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述的方法的步骤。
10.一种计算机程序产品,其特征在于,包括计算机指令,所述计算机指令被处理器执行时实现如权利要求1至7中任一项所述的方法的步骤。
技术总结本申请提供一种多云资源调度方法、装置、存储介质及程序产品。该方法包括:获取多个云平台的资源状态信息;所述资源状态信息至少包括以下至少一种:每个云平台的资源利用率、每个云平台的虚拟机数量、每个云平台的网络延迟;使用卷积神经网络模型对所述资源状态信息进行特征提取,得到资源状态特征;将所述资源状态特征输入至深度强化学习模型,输出每个所述云平台的资源分配方案。本申请通过卷积神经网络模型和深度强化学习模型来实现多云资源的智能调度,提高调度的实时性和动态性。技术研发人员:戴嫚嫚受保护的技术使用者:中移(苏州)软件技术有限公司技术研发日:技术公布日:2024/7/25本文地址:https://www.jishuxx.com/zhuanli/20240730/193906.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表