一种基于特征空间粒子推断的数据集蒸馏方法及系统
- 国知局
- 2024-07-31 22:47:07
本发明涉及深度学习和图像数据集压缩,特别涉及一种基于特征空间粒子推断的数据集蒸馏方法及系统。
背景技术:
1、在过去的十几年里,深度神经网络凭借强大的、使其能够直接处理庞大数据集并绕过复杂手动提取特征步骤的计算资源,在计算机视觉、信息检索和自然语言处理等机器学习任务中表现出了令人印象深刻的性能。然而,突破性的深度模型都依赖于在大规模数据集上进行训练,处理大规模数据要进行采集、存储、传输和预处理等一系列工作,需要付出大量的存储、传输和处理资源的代价。此外,对海量数据集的训练通常需要巨大的计算成本,有时需要数千个gpu小时才能达到令人满意的性能,这会限制超参数优化、神经架构搜索等依赖于在数据集上及进行多次训练的算法的应用。同时,由于现实世界中的信息和数据集是爆炸式增长的,每天都会产生海量数据,这对深度神经网络的模型性能和训练效率都会构成重大威胁,一方面,仅对新出现的数据进行训练很容易出现灾难性遗忘问题,这会严重损害性能;另一方面,存储所有历史数据即使不是完全不可行,也是非常麻烦的,有限的计算资源也难以支撑如此大规模数据的高效训练。
2、解决上述高精度深度神经网络的需求与当前有限的计算和存储资源之间存在的矛盾,一种自然的想法是简化数据集,以小规模数据保留大规模数据集中对目标任务有用的信息,这样可以在保证下游深度神经网络模型性能的同时减轻存储负担。针对这一目标,有研究学者提出了数据集蒸馏这一非常有应用前景的方法,目的是导出包含合成样本的小得多的数据集,基于该数据集,经过训练的模型产生的性能与在原始数据集上训练的模型相当。
3、现有的数据集蒸馏方法可以分为性能匹配、参数匹配和分布匹配三大类,本发明提出了一种分布匹配数据集蒸馏方法,旨在结合粒子变分推断技术用合成样本特征分布拟合原始数据样本特征分布
4、基于性能匹配的方法是约束分别在合成数据集和真实数据集上训练得到的模型性能相匹配,这是最接近数据集压缩根本目标的方法,但通常涉及双层优化问题,需要在每次外层迭代中更新多步网络权重并展开其递归计算图,因此也是优化最困难的方法。其中基于元学习的方法是在内层优化中通过梯度下降的方法用合成数据集更新可微模型的权重,并缓存递归计算图,在外层优化中用真实数据集验证内层优化训练的模型,并将验证损失通过展开的计算图反向传播到上,因此涉及的优化过程较多,计算图展开困难且存在误差,所以优化困难。
5、基于参数匹配的方法与性能匹配的方法不同,其目的是使由合成数据集训练的模型在参数空间中逼近由真实数据集训练的模型,即。虽然参数匹配的方法规避了性能匹配中双层优化的问题,但是会涉及到深度网络模型权重的多次训练更新,优化过程耗时长,增加了数据集蒸馏的计算成本。其中单步参数匹配方法需要在每步优化时分别用和更新一步网络权重,并约束两个网络对于参数所得梯度保持一致,需要耗时的网络更新;多步参数匹配方法需要预先存储多个在上的网络权重更新轨迹,在每步优化时约束在上训练的网络权重更新轨迹与之匹配,需要大量gpu内存来进行额外的磁盘存储和专家模型训练。因此,参数匹配的方法虽然可以到的很不错的蒸馏效果,但是会增加蒸馏过程中的计算和存储成本。
6、基于分布匹配的方法本质上是学习合成样本,使合成样本在特征空间中的分布与真实样本的分布相似,通常使用最大平均差异(mmd)的经验估计作为评估特征空间中分布距离的度量。相比于性能匹配和参数匹配,分布匹配的方法不涉及模型的双层优化问题和耗时的网络权重更新过程,显著降低了数据集蒸馏过程相关的计算成本,优化目标简单,容易实现。但是当前分布匹配的方法是假设特征分布为高斯分布,仅对齐特征分布的一阶矩,即将合成样本的特征嵌入拉向真实数据特征嵌入的中心,这样可能会导致学习到的合成样本的特征分布坍缩至真实数据特征分布的中心区域,难以有效覆盖原始分布,极大地限制了合成数据集样本特征的多样性。
7、因此,如何提供一种能够使学习到的合成样本的特征既具有原始数据集特征代表性又具有一定多样性的数据集蒸馏方法及系统是本领域技术人员亟待解决的技术问题。
技术实现思路
1、本发明针对上述研究现状和存在的问题,提供了一种基于特征空间粒子推断的数据集蒸馏方法及系统,实现了基于特征空间粒子推断的数据集蒸馏,使得学习到的合成样本的特征既具有原始数据集特征的代表性又具有一定的多样性,可以为下游任务模型的训练提供充分的有效信息。
2、本发明提供的一种基于特征空间粒子推断的数据集蒸馏方法,包括如下步骤:
3、s1:获取包含监督信息的原始图像数据集,所述原始图像数据集中包含不同类别的图像;
4、s2:按照预设聚类方法,对原始图像数据集进行分类别聚类;
5、s3:将相同类别、相同聚类簇的原始图像样本进行统一尺寸缩放后,拼接为与原始图像样本等同尺寸大小的图像,得到初始化的合成数据集;
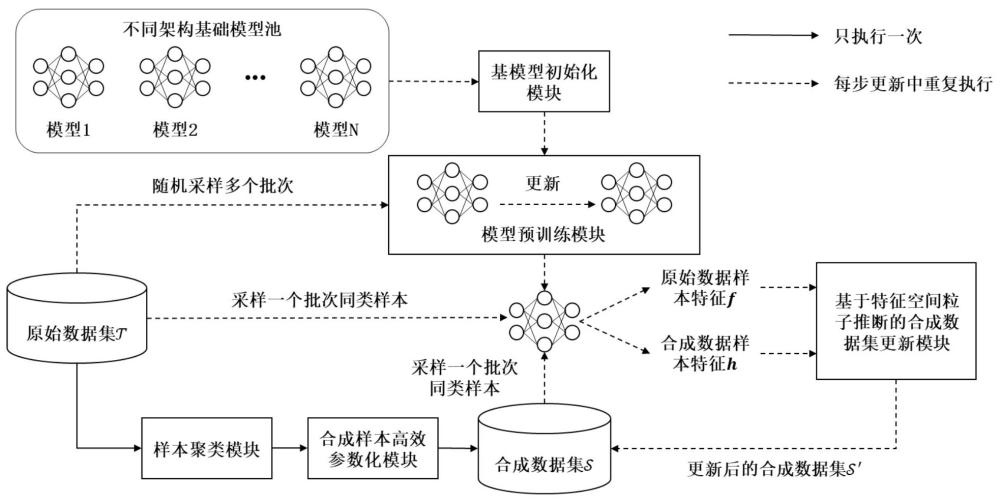
6、s4:对合成数据集进行迭代优化,在每次迭代过程中在基础模型池中对基模型进行随机选择,并对当前迭代次数下选择的基模型利用所述原始图像数据集进行更新训练,得到预训练的基模型;其中,所述基础模型池包含不同架构的神经网络;
7、s5:利用预训练的基模型分别提取原始图像数据集中每个类别的原始图像数据特征和合成数据集中对应类别的合成样本特征;
8、s6:估计所述原始图像数据特征的特征分布,并结合特征空间粒子推断方法对所述合成样本特征进行特征分布匹配,得到更新后的合成数据集;
9、s7:重复执行s4-s6,直至迭代结束,得到更新完成的合成数据集;所述合成数据集用于训练外部网络模型。
10、优选的,所述s2包括:利用预训练的图像分类模型提取原始图像数据集的数据特征,并基于特征对每个类别的原始图像数据样本进行聚类。
11、优选的,所述s3包括:
12、s31:设置缩放因子,每类合成样本按高和宽包括个分解区域;
13、s32:选择个相同类别、相同聚类簇的原始图像样本,高和宽放缩倍后填入对应分解区域,得到初始化的合成数据集。
14、优选的,s4包括:
15、根据预设置的基模型重构频率及总迭代次数,每当迭代次数达到重构频率,从基础模型池中随机选择一种基模型,并随机初始化其网络权重;
16、设置基模型预训练更新次数,在当前迭代中,基模型初始化后,利用原始图像数据集训练更新基模型网络权重,并利用所述外部网络模型的任务目标损失指导基础模型学习,得到预训练的基模型。
17、优选的,所述s5包括:
18、在原始图像数据集中,分别从每个类别中随机采样获得原始图像数据样本;
19、将合成数据集中对应类别的合成样本按照s3的拼接方式,将每块拼接区域上采样恢复至与原始图像样本相同的尺寸,得到恢复后的合成样本;
20、将原始图像数据样本和上采样后的合成数据样本输入到所述预训练的基模型,分别得到对应的原始图像数据特征和合成数据样本特征。
21、优选的,所述s6包括:
22、将原始图像数据特征按照高斯分布特性估计其均值向量和协方差矩阵;
23、合成样本特征作为特征粒子,利用所述均值向量和协方差矩阵,基于特征空间粒子推断方法得到合成样本特征粒子的更新方向;
24、再根据合成样本特征与合成样本之间的关系,利用雅可比矩阵将特征粒子更新方向投影到样本空间,得到合成样本的更新方向;
25、利用合成样本的更新方向迭代执行合成样本的更新步骤。
26、本发明还提供了一种根据所述的一种基于特征空间粒子推断的数据集蒸馏方法的数据集蒸馏系统,包括:
27、数据集获取模块,用于获取包含监督信息的原始图像数据集,所述原始图像数据集中包含不同类别的图像;
28、样本聚类模块,用于按照预设聚类方法,对原始图像数据集进行分类别聚类;
29、合成样本参数化模块,用于将相同类别、相同聚类簇的原始图像样本进行统一尺寸缩放后,拼接为与原始图像样本等同尺寸大小的图像,得到初始化的合成数据集;
30、基模型初始化模块,用于在合成数据集的每次迭代优化过程中,在基础模型池中对基模型进行随机选择;其中,所述基础模型池包含不同架构的神经网络;
31、模型预训练模块,用于对当前迭代次数下选择的基模型利用所述原始图像数据集进行更新训练,得到预训练的基模型;
32、基于特征空间粒子推断的合成数据集更新模块,用于利用预训练的基模型分别提取原始图像数据集中每个类别的原始图像数据特征和合成数据集中对应类别的合成样本特征;估计所述原始图像数据特征的特征分布,并结合特征空间粒子推断方法对所述合成样本特征进行特征分布匹配,得到更新后的合成数据集。
33、优选的,所述基模型初始化模块包括:基模型选择单元;其中,
34、基模型选择单元,用于根据预设置的基模型重构频率及总迭代次数,每当迭代次数达到重构频率时,从基础模型池中随机选择一种基模型,并随机初始化其网络权重。
35、优选的,所述模型预训练模块包括:更新参数设置单元和模型更新单元;其中,
36、更新参数设置单元,用于设置基模型预训练更新次数;
37、模型更新单元,用于在当前迭代中,基模型初始化后,利用原始图像数据集训练更新基模型网络权重,并利用所述外部网络模型的任务目标损失指导基础模型学习,得到预训练的基模型。
38、优选的,所述基于特征空间粒子推断的合成数据集更新模块包括:原始图像数据特征分布计算单元和合成样本特征分布匹配单元;其中,
39、原始图像数据特征分布计算单元,用于将原始图像数据特征按照高斯分布特性估计其均值向量和协方差矩阵;
40、合成样本特征分布匹配单元,用于合成样本特征作为特征粒子,利用所述均值向量和协方差矩阵,基于特征空间粒子推断方法得到合成样本特征粒子的更新方向;再根据合成样本特征与合成样本之间的关系,利用雅可比矩阵将特征粒子更新方向投影到样本空间,得到合成样本的更新方向;利用合成样本的更新方向迭代执行合成样本的更新步骤。
41、相较现有技术具有以下有益效果:
42、本发明相较于性能匹配和参数匹配的数据集蒸馏方法,基于分布匹配的数据集蒸馏方法蒸馏过程中计算成本低,并且优化目标简单,因此本发明提出了一种新的基于分布匹配的数据集蒸馏方法。
43、本发明结合了样本聚类的方法选择原始数据集中具有代表性的样本作为合成数据集的初始样本;采用样本聚类的方法,将原始数据集中每一类样本聚类为预先设置的ipc个聚类簇,可以从每个聚类簇中分别采样原始样本进行合成数据集的初始化。对比随机采样的方法,先聚类再采样的方式可以为合成数据集提供原始数据集中均匀的样本分布信息,保证合成数据集具有良好的起始点。
44、本发明结合了高效样本参数化技巧在与现有方法相同的存储约束下可以构建更多的合成样本。通过放缩原始样本和将合成样本分区的方式,使得在相同存储约束下,初始合成数据集能够保留更多的原始数据信息,并且在后续利用时可以通过上采样的方式构造更多的合成样本,充分利用的合成数据集的存储空间。
45、本发明采用基于粒子推断的方法,将每个合成样本的特征看作是一个粒子,整个合成数据集的特征嵌入视为一组粒子,利用粒子间的相互作用,推动粒子移向目原始数据特征分布的高概率区域,并使粒子间具有排斥作用,保证了合成数据特征在具有代表性的同时具有一定的多样性,缓解了现有分布匹配数据集蒸馏方法存在的仅对齐特征分布之间一阶矩,容易出现学习到的合成数据的特征坍缩至真实数据特征分布中心区域,导致其缺乏多样性的问题。利用斯坦变分梯度下降的方法,使用确定性来优化粒子,使其逼近原始数据集的特征分布,在保证合成样本的特征具有代表性的同时也具有多样性,可以为下游任务模型的训练提供充分的有效信息。
46、本发明最终实现了一种具有良好初始点、高效的、基于特征空间粒子推断的数据集蒸馏方法,并且算法结构简洁、更高效地利用了存储空间,具有可移植性,可以轻易地应用于不同图像分类数据集。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194577.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表