基于AI服务器冗余系统的数据源故障处理方法及系统与流程
- 国知局
- 2024-07-31 22:50:39
本发明属于ai数据源异常处理,尤其涉及基于ai服务器冗余系统的数据源故障处理方法及系统。
背景技术:
1、现有的ai服务器,其服务器的架构是基于cpu+npu的形态。现有技术对于ai服务器,当cpu系统异常,整机无法继续工作,npu数据源解析都会中止,导致数据源异常丢失,例如10000份数据语言,分成2500份给到四个npu模组解析,其中到4999份数据源解析时,cpu异常,其剩余未解析的数据源都会因为cpu异常,计算失效,无法通过cpu存储到nvme盘中,导致此部分数据源丢失。此时对于用户需要花费时间恢复数据以及ai服务器的维修,业务系统中断对用户都是不小的损失。
2、现有技术对于ai服务器,系统中存在多npu模组形态时,例如四个npu模组,当其中一个npu模组异常,例如1号npu模组异常,剩下2/3 npu模组的数据源计算都会等着1号npu模组计算完成,且1号npu模组由于异常,分给1号npu模组的数据源计算失败,现有技术则是通过断点续训,将1号npu模组隔离,同时此组数据源失效处理,后续npu持续对下一组分配的数据源继续进行计算,不影响整个大的数据模型解析,只是会存在数据告警,告知用户此组数据模型解析异常。后续对此组大数据模型重新计算,但此方式仍会造成未保存数据的丢失,且无法完全还原上一次计算点只是根据上次保存的数据继续训练,以及数据模型处理缓慢的问题。
3、因此,如何对现有的ai服务器的架构进行改进,解决现有的服务器架构存在的容易造成未保存数据的丢失,且无法完全还原上一次计算点只是根据上次保存的数据继续训练,以及数据模型处理缓慢的技术问题。
技术实现思路
1、本发明的目的在于提供基于ai服务器冗余系统的数据源故障处理方法及系统,用以解决现有的服务器架构存在的容易造成未保存数据的丢失,且无法完全还原上一次计算点只是根据上次保存的数据继续训练,以及数据模型处理缓慢的技术问题的技术问题。
2、为解决上述技术问题,本发明采用的技术方案如下:
3、第一方面,提供基于ai服务器冗余系统的数据源故障处理方法,包括以下步骤:
4、s1:启动服务器时对各cpu的状态参数进行检测,并基于状态参数确定各cpu运行的cpu当前优先级,将cpu当前优先级与cpu默认优先级进行对比,判断是否一致,若是,执行步骤s2;若否,以cpu当前优先级运行,再执行步骤s2,同时将cpu当前优先级设为默认优先级;
5、s2:cpu进行数据处理,并实时监测当前运行cpu的状态,判断其是否存在异常,若是,分析异常类型和处理的数据类型,根据异常类型和处理的数据类型匹配相应的cpu,并切换至匹配的cpu,根据匹配结果更新当前优先级;若否,继续执行cpu当前优先级;
6、s3:匹配的cpu将异常cpu存储在异常cpu的nvme盘中的计算数据源缓存到匹配的cpu的dimm内存条中,并从匹配的cpu的dimm内存条下发ai算法指令在匹配的cpu的npu模组上重新计算;
7、s4:实时监测匹配的cpu的npu模组中各npu的状态参数,并根据其状态参数确定匹配的cpu的npu模组中npu当前优先级,将npu当前优先级与npu默认优先级进行对比,判断是否一致,若是,执行步骤s5;若否,以npu当前优先级运行,再执行步骤s5,同时将npu当前优先级设置为默认优先级;
8、s5:npu模组进行数据处理,并实时监测当前运行的各npu状态,判断是否存在异常,若是,分析异常类型和处理的数据类型,根据异常类型和处理的数据类型匹配相应的npu,并根据匹配结果更新npu当前优先级;匹配的cpu将在dimm中静态缓存的ai计算数据源重新下发给到匹配的npu,匹配的npu多计算一份ai计算数据源,执行步骤s6;若否,继续执行npu当前优先级,再执行步骤s6;
9、s6:将计算完成后的数据模型解析发给匹配的cpu,匹配的cpu再将解析后的ai计算数据源缓存在dimm内存条中,再保存数据于nvme盘;
10、s7:对异常cpu以及异常npu进行维护,完成ai服务器的故障处理。
11、优选的,步骤s1包括以下具体过程:
12、s11:启动服务器,并实时采集服务器的各cpu的性能参数,所述性能参数包括主频、总线频率、二级缓存、核心数和线程数;
13、s12:基于采集的各cpu的性能参数以及相应的预设的各参数权重为各cpu的性能进行评分;
14、s13:根据各cpu的性能评分结果设置cpu当前优先级,评分越高,对应的优先级越高;
15、s14:将cpu当前优先级与cpu默认优先级进行对比,判断是否一致,若是,执行步骤s2;若否,以cpu当前优先级运行,再执行步骤s2,同时将cpu当前优先级设为默认优先级;
16、其中,步骤s12的评分过程为,先对每项性能参数进行打分,例如其中某项性能参数m,处于理论最佳状态值时为满分为10分,用10乘以采集的性能参数相比于理论最佳状态值的百分比得到对应的性能参数的分数a;其他的性能参数的得分分别为b、c、d、e,a、b、c、d、e对应的权重为a、b、c、d、e,a+b+c+d+e=100%;
17、最终的cpu的得分x=aa+bb+cc+dd+ee。
18、优选的,步骤s2包括以下具体过程:
19、s21:根据s1中的优先级启动相应的cpu进行数据处理,并实时采集当前运行cpu的状态参数;
20、s22:基于当前运行cpu的状态参数与预设的正常状态参数进行比较,判断其是否存在异常,若是,执行步骤s23,若否,继续执行cpu当前优先级;
21、s23:执行分析异常类型和处理的数据类型,根据异常类型和处理的数据类型匹配相应的cpu,并切换至匹配的cpu,根据匹配结果更新当前优先级。
22、优选的,在步骤s2中,对ai服务器的cpu系统中的当前运行cpu进行实时监测的方式为,未执行数据处理的cpu对执行数据处理的cpu进行主动查询,同时数据处理的cpu也会对未执行数据处理的cpu进行主动查询;
23、对npu模组进行实时监测的方式为:执行数据处理的cpu对与之连接的各npu进行主动监测,未执行数据处理的cpu也对与之连接的各npu进行主动监测。
24、优选的,步骤s2中根据异常类型和处理的数据类型匹配相应的cpu为当前服务器的冗余cpu或者其他服务器的冗余cpu。
25、优选的,步骤s4中包括以下具体过程:
26、s41:实时监测匹配的cpu的npu模组中各npu的状态参数,所述npu的状态参数包括算力、频率、功耗;
27、s42:基于采集各npu的状态参数以及相应的预设的各参数权重为各npu的性能进行评分,并根据评分结果设置匹配的cpu的npu模组中npu当前优先级,其中的各npu的评分过程与cpu的评分过程相同;
28、s43:将npu当前优先级与npu默认优先级进行对比,判断是否一致,若是,执行步骤s5;若否,以npu当前优先级运行,再执行步骤s5,同时将npu当前优先级设置为默认优先级。
29、优选的,在进行数据源故障处理的过程中数据流的执行步骤如下:
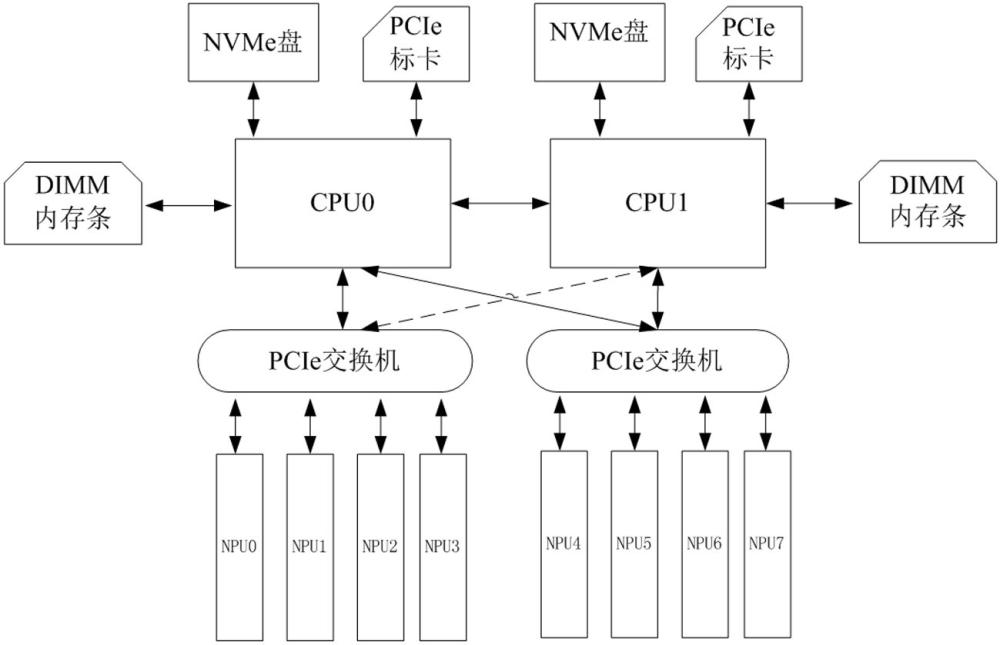
30、s1-1:应用程序任务开始,cpu运行ai程序,初始化ai任务npu资源,加载模型与网络结构到npu;
31、s2-2:数据读取部分开始读取将要做ai任务的数据,并读取硬盘数据到cpu的内存中;
32、s3-3:数据预处理部分对数据做预处理,并且cpu 分发预处理数据到所有npu;
33、s4-4:ai算法任务开始,程序通过cann中间接口向所有npu分配ai运算任务;
34、s5-5:cpu侧 ai主进程等待所有npu的ai任务运算完成,拷贝所有结果回cpu侧内存做数据整合,整合数据返回cpu侧;
35、s6-6:cpu侧 ai主进程的网络模型对ai模型做参数更新;
36、s7-7:cpu 程序保存当前ai模型权重文件。
37、优选的,在步骤s5-5中进行数据整合使用all reduce分布式集合通讯数据整合算法。
38、第二方面,提供基于ai服务器冗余系统的数据源故障处理系统,包括cpu0、cpu1、npu模组、dimm内存条、nvme盘、pcie标卡和pcie交换机,所述cpu0与cpu1通信连接,所述npu模组和pcie交换机均设有两组,其中一组npu模组通过一组pcie交换机与所述cpu0连接,另一组npu模组通过另一组pcie交换机与cpu1连接;
39、所述cpu0和cpu1为双cpu冗余备份系统,用于ai服务器的系统管理和ai数据源获取计算数据源,分配给npu模组数据源多点形式;
40、所述npu模组用于ai数据源计算;
41、所述dimm内存条用于ai数据源静态缓存和内存缓存;
42、所述nvme盘用于存储ai服务器操作系统以及对ai计算数据源和计算解析后的数据存储;
43、所述pcie标卡为标准pcie网卡或计算卡;
44、所述pcie交换机:用于cpu0、cpu1与npu模组交互的pcie扩展使用,cpu0、cpu1通过pcie交换机桥接相应的npu模组,作为计算数据源处理通路。
45、本发明的有益效果包括:
46、本发明提供的基于ai服务器冗余系统的数据源故障处理方法及系统,启动服务器时对其cpu系统中各cpu的状态参数进行检测,并以最佳优先级执行;实时监测当前运行cpu的状态,判断其是否异常,并切换至匹配的cpu,根据匹配结果更新当前优先级;匹配的cpu的dimm内存条下发算法指令在匹配的cpu的npu模组上重新计算;实时监测npu的状态参数,执行最佳优先级;实时监测当前运行的各npu状态,判断是否异常,执行最佳优先级;cpu将数据源下发给到匹配的npu多计算一份, cpu再将解析后的数据源保存数据于nvme盘。
47、第一,基于ai服务器涉及cpu+npu架构,cpu通过dimm内存条实现cpu备份冗余,当其中一个cpu异常,cpu与npu交互的数据模型业务仍能继续工作,短期不去影响客户当前业务使用,同时cpu异常告警告知用户,用户在下一次业务模型计算推理前对此服务器维修或者业务关闭下电,保障数据源不会随意丢失。
48、第二,通过在cpu设置优先级并在数据处理中执行最佳优先级,保证服务器的进行数据处理时的状态最佳,并能根据数据类型匹配合适的cpu,npu模组的设置优先级同理。
49、第三,系统中存在多npu模组形态时,通过软件系统搭载cpu+npu模组,当其中一个npu异常时,异常npu的数据计算中止,对应的cpu自动切换到另外一个npu,同时从nvme盘中提取上一个npu分配的数据源,下发到其他npu异常分配数据进行重计算以及分配数据计算,后续npu模组待上一个npu模组计算完成后持续对分配数据计算,最后回传结果给与之连接的cpu做结果整合和处理工作,同时cpu对异常npu模组隔离处理,后续大数据重新分配给其他正常模组继续进行业务计算,待下次系统重启或服务器上下电判断npu模组异常问题点进行修复。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194949.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表