一种基于多视图聚类的检索增强生成方法和系统
- 国知局
- 2024-07-31 22:56:12
本技术涉及人工智能,特别是涉及一种基于多视图聚类的检索增强生成方法和系统。
背景技术:
1、大型语言模型的局限性:传统的大型语言模型(如bert、gpt-3等)通常在大规模数据集上进行预训练,以掌握语言的通用知识。然而,这些模型可能会生成与事实不符的“幻觉”(hallucinations),并且对新信息的响应能力有限。
2、rag(retrieval-augmented generation,检索增强生成)技术是一种结合了信息检索(retrieval)和生成(generation)的先进方法,旨在提高大型语言模型(largelanguage models,llms)的性能。rag的核心思想是通过检索阶段获取相关信息,并将其用于辅助生成阶段,产生更准确、更丰富的文本输出。传统rag方案在分散段落,系统吞吐量,大候选集等方面都具有一定的局限性,研究者们正在探索如何更高效地整合检索和生成过程,以及如何改进检索器和生成器之间的交互。其中检索部分是rag技术极为重要的一环,其决定了整个rag系统的能力上限,只有准确且高效的检索方式才能保证高质量的输出,然而,通用的rag检索方法难以平衡检索效率和检索精度间的关系。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够在保证检索效率的前提下进一步提高检索精度的基于多视图聚类的检索增强生成方法和系统。
2、一种基于多视图聚类的检索增强生成方法,所述方法包括:
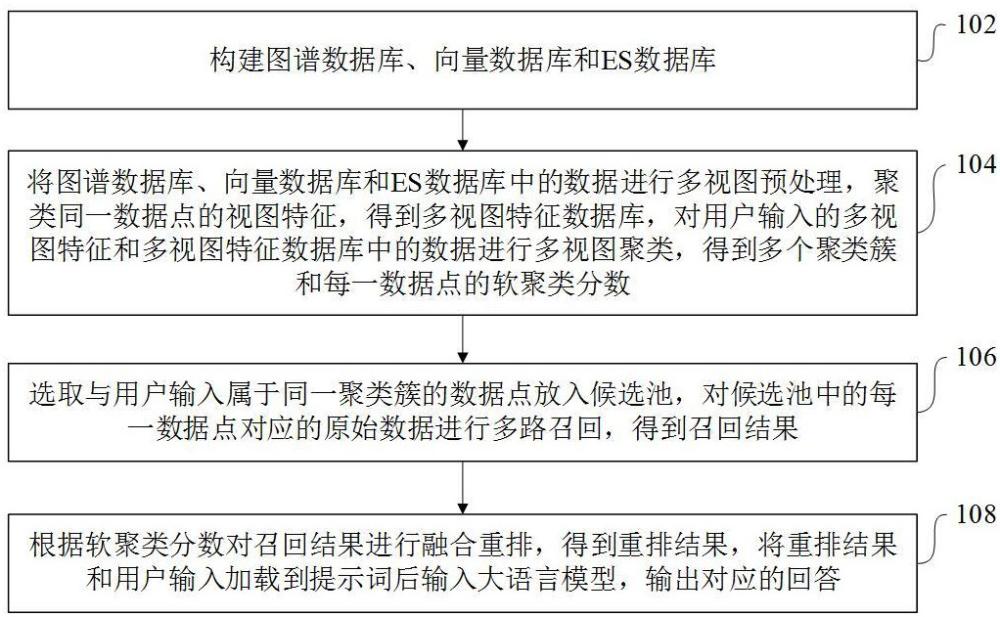
3、构建图谱数据库、向量数据库和es数据库;所述图谱数据库包括多个知识图谱对应的图结构;所述向量数据库包括多个文本信息对应的向量编码;所述es数据库包括多个文本信息;
4、将所述图谱数据库、向量数据库和es数据库中的数据进行多视图预处理,聚类同一数据点的视图特征,得到多视图特征数据库,对用户输入的多视图特征和多视图特征数据库中的数据进行多视图聚类,得到多个聚类簇和每一数据点的软聚类分数;
5、选取与用户输入属于同一聚类簇的数据点放入候选池,对候选池中的每一数据点对应的原始数据进行多路召回,得到召回结果;
6、根据软聚类分数对召回结果进行融合重排,得到重排结果,将重排结果和用户输入加载到提示词后输入大语言模型,输出对应的回答。
7、在其中一个实施例中,还包括:若所述候选池中数据点的数量小于第一阈值,则根据用户输入的多视图特征在所述多视图特征数据库中进行多路召回,得到召回结果;若所述候选池中数据点的数量大于或等于第一阈值,则选取候选池中软聚类分数靠前的4n个数据点,对4n个数据点对应的原始数据进行多路召回,得到召回结果。
8、在其中一个实施例中,还包括:根据每一数据点的图结构和向量编码分别在所述图谱数据库和向量数据库中进行交错拉链式的稀疏检索和稠密检索,对检索结果进行去重和整合得到对应的综合检索结果;根据每一数据点的文本信息在所述es数据库中进行关键字检索,得到关键字检索结果;根据所述综合检索结果和所述关键字检索结果得到2n个召回结果。
9、在其中一个实施例中,还包括:采用bge-reranker排序模型对召回结果进行重排,得到每个数据点的重排分数;根据重排分数和软聚类分数进行软投票,得到重排结果。
10、在其中一个实施例中,还包括:分别对用户输入的多视图特征和多视图特征数据库中各个数据点的多视图特征进行多视图正交化重构,得到对应的重构特征;分别对各重构特征进行硬聚类和软聚类,得到多个聚类簇和每一数据点的软聚类分数。
11、在其中一个实施例中,还包括:获取知识图谱,将知识图谱表征为图结构放入图谱数据库;获取文本信息,将文本信息表征为向量编码放入向量数据库,并将文本信息放入es数据库。
12、在其中一个实施例中,还包括:采用词袋模型处理文本信息得到文本关键字特征,采用文本编码嵌入模型处理向量编码得到上下文语义嵌入特征,采用实体抽取模型处理知识图谱得到文本三元组链接特征。
13、一种基于多视图聚类的检索增强生成系统,所述系统包括数据库模块、多视图聚类模块、检索增强模块以及生成模型模块;
14、所述数据库模块包括图谱数据库、向量数据库和es数据库;所述图谱数据库包括多个知识图谱对应的图结构;所述向量数据库包括多个文本信息对应的向量编码;所述es数据库包括多个文本信息;
15、所述多视图聚类模块用于将所述图谱数据库、向量数据库和es数据库中的数据进行多视图预处理,聚类同一数据点的视图特征,得到多视图特征数据库,对用户输入的多视图特征和多视图特征数据库中的数据进行多视图聚类,得到多个聚类簇和每一数据点的软聚类分数;
16、所述检索增强模块用于选取与用户输入属于同一聚类簇的数据点放入候选池,对候选池中的每一数据点对应的原始数据进行多路召回,得到召回结果;
17、所述生成模型模块用于根据软聚类分数对召回结果进行融合重排,得到重排结果,将重排结果和用户输入加载到提示词后输入大语言模型,输出对应的回答。
18、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
19、构建图谱数据库、向量数据库和es数据库;所述图谱数据库包括多个知识图谱对应的图结构;所述向量数据库包括多个文本信息对应的向量编码;所述es数据库包括多个文本信息;
20、将所述图谱数据库、向量数据库和es数据库中的数据进行多视图预处理,聚类同一数据点的视图特征,得到多视图特征数据库,对用户输入的多视图特征和多视图特征数据库中的数据进行多视图聚类,得到多个聚类簇和每一数据点的软聚类分数;
21、选取与用户输入属于同一聚类簇的数据点放入候选池,对候选池中的每一数据点对应的原始数据进行多路召回,得到召回结果;
22、根据软聚类分数对召回结果进行融合重排,得到重排结果,将重排结果和用户输入加载到提示词后输入大语言模型,输出对应的回答。
23、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
24、构建图谱数据库、向量数据库和es数据库;所述图谱数据库包括多个知识图谱对应的图结构;所述向量数据库包括多个文本信息对应的向量编码;所述es数据库包括多个文本信息;
25、将所述图谱数据库、向量数据库和es数据库中的数据进行多视图预处理,聚类同一数据点的视图特征,得到多视图特征数据库,对用户输入的多视图特征和多视图特征数据库中的数据进行多视图聚类,得到多个聚类簇和每一数据点的软聚类分数;
26、选取与用户输入属于同一聚类簇的数据点放入候选池,对候选池中的每一数据点对应的原始数据进行多路召回,得到召回结果;
27、根据软聚类分数对召回结果进行融合重排,得到重排结果,将重排结果和用户输入加载到提示词后输入大语言模型,输出对应的回答。
28、上述基于多视图聚类的检索增强生成方法和系统,通过对图谱数据库、向量数据库和es数据库中的数据进行多视图预处理,聚类同一数据点的视图特征,得到多视图特征数据库,对用户输入的多视图特征和多视图特征数据库中的数据进行多视图聚类,得到多个聚类簇和每一数据点的软聚类分数;选取与用户输入属于同一聚类簇的数据点放入候选池,对候选池中的每一数据点对应的原始数据进行多路召回,得到召回结果,根据软聚类分数对召回结果进行融合重排,得到重排结果,将重排结果和用户输入加载到提示词后输入大语言模型,输出对应的回答。本发明实施例,能够在保证检索效率的前提下进一步提高检索精度,实现高效的文档检索。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195401.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。