基于情感极性注意力机制的文本情感分析方法、设备及介质
- 国知局
- 2024-07-31 23:05:34
本发明涉及自然语言处理,尤其是涉及基于情感极性注意力机制的文本情感分析方法、设备及介质。
背景技术:
1、微博、微信、facebook、twitter等社交媒体的不断普及,网络已经是当下年轻人获得信息的主要来源,同时也是表达观点的重要平台。随着信息规模的急剧增大,仅仅依靠传统的、人工处理的方法实现文本分类、情感分析等任务已经变得不再可行,这促使研究者们不得不探索新的技术和方法。文本情感分析(也称意见挖掘)是自然语言处理领域中最重要的研究方向之一。文本情感分析采用自然语言处理、文本挖掘等技术来识别和提取说话者或作者对某些话题的主观意见或看法。
2、文本情感分析的一般步骤是根据文本中已知的带有情感倾向的词汇对文本进行分类,其目的是判断该文本表述的观点是积极的、消极的、还是中性的情绪。文本情感分析的方法主要包括基于情感词典的方法、基于机器学习的方法和基于深度学习的方法。随着深度学习技术的提出与发展,为文本情感分析等相关领域的研究提供了新的契机。借助于深度学习在特征提取与融合方面的优势,可将词汇和文本直接表征为词向量(或称词嵌入)和文本向量(或称文本嵌入),并基于神经网络构造的分类器实现文本情感分类的目的。但是在文本情感分析过程中不同的人对同一个词的感受是不同的,将反应情感的词汇表征为一些独立、无关的向量时会失去其内在联系,导致部分信息丢失而无法准确地反应情感词汇具体情感程度的深浅和准确性。
3、在中国专利文献上公开的“一种文本情感分析方法”,其公开号为cn114564585a,公开日期为2022-05-31,包括:s1:将文本句子中的词语转为词向量;s2:将词向量映射为情感特征向量;s3:将词向量和情感特征向量拼接为每个词的情感特征词向量,整个句子中多个情感特征词向量一起作为输入特征矩阵;s4:将输入特征矩阵输入卷积神经网络进行训练,获取第一抽象情感特征;s5:将输入特征矩阵输入双向长短期记忆网络进行训练,获取第二抽象情感特征;s6:将第一抽象情感特征和第二抽象情感特征进行融合拼接,再输入全连接神经网络,最后通过softmax层输出句子的情感分类;但是该技术同样是用独立、无关的向量来表征反应情感的词汇,使得在具体情感分析时存在信息丢失而影响结果的准确性。
技术实现思路
1、本发明是为了克服现有技术中将反应情感类的词汇表征为独立、无关的向量时存在信息丢失,从而导致文本情感分析的准确性不足的问题,提供了一种基于情感极性注意力机制的文本情感分析方法、设备及介质。
2、为了实现上述目的,本发明采用以下技术方案:
3、一种基于情感极性注意力机制的文本情感分析方法,包括:
4、将待分析的目标文本中的词汇转化为对应的词表征向量,并转化为词表征矩阵;
5、将词典中对应于情感极性词汇的定义描述文本转化为文本表征向量,并转化为第一文本表征矩阵和第二文本表征矩阵;
6、融合词表征矩阵、第一文本表征矩阵和第二文本表征矩阵,将目标文本中词汇的词表征向量表示为情感极性词汇叠加形式下的表征向量;
7、根据情感极性词汇叠加形式下的表征向量进行文本情感分类。
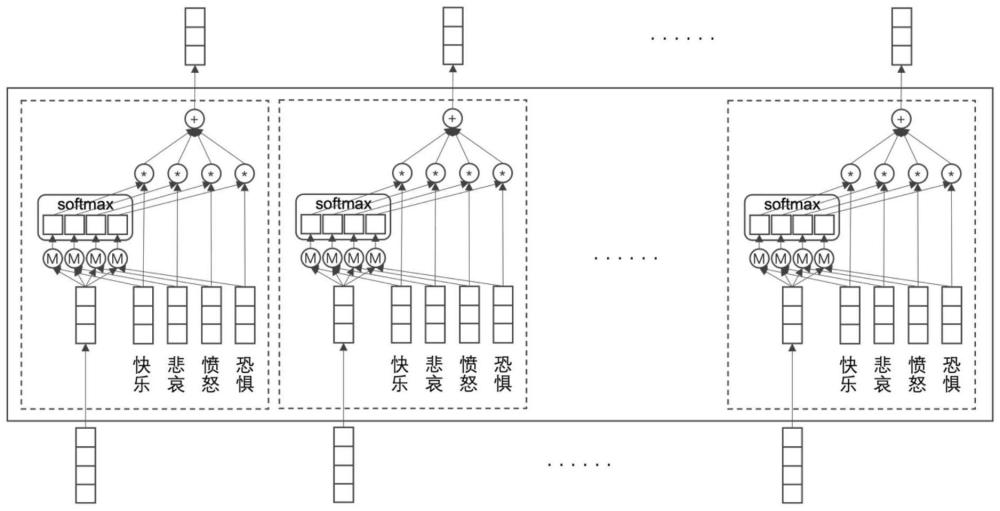
8、本发明中由于文本情感分析对词汇是敏感的,即词汇对最终结果的影响占比较大,而注意力机制可以很好的关注到文本中重要的词汇,且不受文本长度的影响;由注意力机制导出的深度学习语言模型,如gpt、bert等,可以很好的学习到基于上下文信息的词向量表征,即该词向量是一个具有上下文语义的词嵌入,但对于文本情感分析任务而言这还是不够的;在人们的认知中,几乎所有的情感类词汇都是处于一个叠加状态,且不同的人对同样一个词的认知是不一样的。当我们将其表示成几个无关的向量时将失去它们内在的联系,即它们都是在描述处于好与坏之间的程度,对于文本情感分析问题而言,假如是一个二分类的问题,即积极与消极,一些能够反应情感的词汇并不应该简单的表示成为一些独立的、无关的词向量,而是应该表征为一个处在积极与消极状态之间的叠加状态,且不同的词表示出不同程度的叠加;这样的表征对于文本情感分析而言是有意义的,可以深刻揭示每个情感类词汇内在的联系和它们表达程度的不同,从而更准确地进行文本情感分类。
9、作为优选,所述情感极性词汇叠加形式下的表征向量的表示过程包括:
10、将词表征矩阵与第一文本表征矩阵做矩阵乘法运算;对于计算后的矩阵进行同一纬度上的归一化操作;将归一化后的矩阵再与第二文本表征矩阵做矩阵乘法运算。
11、作为优选,所述词表征矩阵的获得过程包括:
12、对待分析的目标文本wtext进行编码,获得目标文本中词汇的词表征向量vtext;
13、对词表征向量通过线性层进行线性变换,得到词表征向量的集合作为词表征矩阵。
14、作为优选,所述第一文本表征矩阵和第二文本表征矩阵的获取过程包括:
15、对词典中对应于情感极性词汇的定义描述文本wdefinition进行编码,获得情感极性词汇的文本表征向量vdefinition;
16、对文本表征向量采用第一线性变换,得到文本表征向量的第一集合作为第一文本表征矩阵;对文本表征向量采用第二线性变换,得到文本表征向量的第二集合作为第二文本表征矩阵。
17、作为优选,对于待分析的目标文本:
18、wtext=[w1,w2,…,wi,…]
19、采用表征学习模型或预训练语言模型对目标文本实施编码,获取词表征向量:
20、vtext=w-vector(wtext)=[v1,v2,…,vi,…]
21、对词表征向量vtext实施线性变换:
22、q≡v′text=linear(vtext)=[v′1,v′2,…,v′i,…]
23、其中wi指构成目标文本的词汇,vi指对应的词表征向量,下标i为词汇索引,w-vector(·)函数指用于获得词表征向量的模型,linear(·)函数指线性层,v′i指线性变换后的目标文本中的词表征向量。
24、作为优选,对于定义描述文本:
25、wdefinition=[w1,w2,…,wi,…]
26、采用表征学习模型或预训练语言模型对目标文本实施编码,获取文本表征向量vdefinition作为情感极性词汇的表征向量vemotional_polarity:
27、vemotional_polarity≡vdefinition=t-vector(wdefinition)
28、分别进行第一线性变换和第二线性变换:
29、k≡v′emotional_polarity=linear1(vemotional_polarity)
30、v≡v′emotional_polarity=linear2(vemotional_polarity)
31、其中wi指构成定义描述文本的词汇,t-vector(·)函数为用于获得文本表征向量的模型,下标i为词汇索引,linear1(·)和linear2(·)分别为第一线性变换和第二线性变换的线性层。
32、作为优选,所述情感极性词汇叠加形式下的表征向量为:
33、
34、其中softmax(·)为归一化指数函数;dk指第k维的维度;q为词表征矩阵;k为第一文本表征矩阵;v为第二文本表征矩阵。
35、作为优选,所述进行文本情感分类的过程包括:
36、基于获得的目标文本词汇在情感极性词汇叠加形式下的词表征向量进行文本情感分类:
37、result=classifier(m″)
38、其中classifier(·)函数指使用的分类器,result指目标文本的情感分类结果。
39、一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如本技术基于情感极性注意力机制的文本情感分析方法的步骤。
40、一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如本技术基于情感极性注意力机制的文本情感分析方法的步骤。
41、本发明具有如下有益效果:基于情感极性修改注意力机制模型以构建一种适用于表征叠加状态的新模型,以提高、改善文本情感分析的准确性;受心理学习中情感复合理论的启发,将待实施文本情感分析的目标文本中的词汇表征为情感极性词汇的叠加状态,以实现对目标文本中情感类词汇的准确描述,其中实现情感极性词汇叠加表征的方法是模仿注意力机制模型完成的;与现在技术相比,本发明能够显著改善目标文本中情感类词汇的表征准确性,并对文本情感分析任务的识别准确性有着积极的作用;为评估基于情感极性注意力机制的文本情感分析方法的有效性,在标准的文本情感分析数据集上实施验证,实验结果表明该方法有利于改善情感类词汇的准确性,并能够提高文本情感分析模型的表现。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195911.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。