一种多模态跨语言检测方法及装置
- 国知局
- 2024-07-31 23:12:56
本技术涉及计算机,尤其涉及一种多模态跨语言检测方法及装置。
背景技术:
1、逐年增加的学术不端案例正在侵蚀科研环境的诚信基础。而一稿多发是指一个作者使用相同数据、核心观点或结论发表两篇或多篇论文而没有相互引用的行为。一稿多发会重复计算研究结果,从而使作者不公正获利,该行为严重严重破坏科研公平公正的风气。
2、目前针对论文检测的研究方法大多聚焦于单一文本模态,忽略了论文中的表格和公式等其他模态信息。同时对于文本模态,非法作者常会利用不同语言间句法结构和用词方式不同的特点进行跨语言一稿多发,以此逃避论文检测系统。
3、因此,基于多模态融合技术,研发多模态跨语言检测方法可以有效减少一稿多发行为,维护学术诚信。
技术实现思路
1、本技术旨在至少在一定程度上解决相关技术中的技术问题之一。
2、为此,本技术的第一个目的在于提出一种多模态跨语言检测方法,实现了对不同语言论文数据的相似度的准确检测。
3、本技术的第二个目的在于提出一种多模态跨语言检测装置。
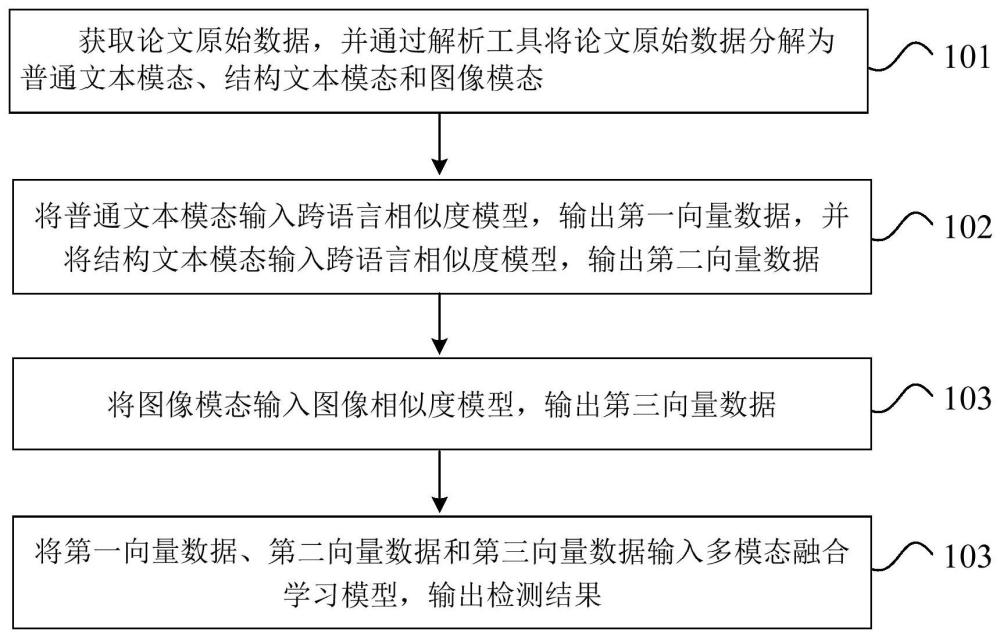
4、为达上述目的,本技术第一方面实施例提出了一种多模态跨语言检测方法,包括:获取论文原始数据,并通过解析工具将论文原始数据分解为普通文本模态、结构文本模态和图像模态;将普通文本模态输入跨语言相似度模型,输出第一向量数据,并将结构文本模态输入跨语言相似度模型,输出第二向量数据;将图像模态输入图像相似度模型,输出第三向量数据;将第一向量数据、第二向量数据和第三向量数据输入多模态融合学习模型,输出检测结果。
5、本技术实施例的多模态跨语言检测方法,利用深度学习中的目标检测技术,抽取了普通图像,表格和公式,利用识别pdf字体与字号的抽取了论文中的正文、大标题和章节标题,利用正则表达式抽取了pdf中的关键词和摘要,使解析数据更全面;利用知识蒸馏技术使单语言语义相似度模型sbert获得跨语言能力,同时利用微调技术使该跨语言语义相似度模型具有理解学术专有名词的能力,有效提升模型的跨语言检测能力;利用晚融合的方式,采用高斯朴素贝叶斯模型作为多模态融合学习模型,将文本相似度,图像相似度与结构相似度相结合完成一稿多发检测,实现了对多种模态的融合检测。
6、可选地,在本技术的一个实施例中,通过解析工具将论文原始数据分解为普通文本模态、结构文本模态和图像模态,包括:
7、以文字的字体与字号为依据抽取论文原始数据中的正文和标题,并利用正则表达式抽取论文原始数据中的关键词和摘要,将抽取的正文作为普通文本模态,将抽取的标题、关键词和摘要作为结构文本模态,其中,标题包括论文大标题和章节标题;
8、使用目标检测模型抽取论文原始数据中的图像、表格和公式,得到初始图像模态,并对初始图像模态进行修正,得到图像模态。
9、可选地,在本技术的一个实施例中,对初始图像模态进行修正,得到图像模态,包括:
10、确定初始图像模态中每个图像的图像中心坐标和识别类型,其中,识别类型包括图像、表格和公式;
11、通过文本检测方法,获取论文原始数据中与识别类型相关的文字块,并确定文字块的中心坐标和关键字类型,其中,关键字类型包括表格类型、图像类型和普通文本类型,公式识别类型与普通文本类型相对应;
12、基于每个图像的图像中心坐标与文字块的中心坐标计算欧式距离,确定与每个图像距离最小的若干个文本块;
13、判断每个图像的识别类型是否在对应的若干个文本块的关键字类型中,若在,保持图像的识别类型,若不在,将图像的识别类型修改为距离最近的文字块的关键字类型。
14、可选地,在本技术的一个实施例中,构建跨语言相似度模型,包括:
15、将单语言语义相似度模型sbert作为教师模型,将多语言模型xlm-r作为学生模型,通过多语言平行语料进行知识蒸馏,得到知识蒸馏后的模型;
16、通过增量训练的方式微调知识蒸馏后的模型,在微调时使用多语言学术平行语料作为训练数据,得到跨语言相似度模型。
17、可选地,在本技术的一个实施例中,在知识蒸馏时,设定教师模型ht,学生模型hs,给定多语言平行语料为{(s1,t1),(s2,t2),…,(sn,tn)},对应的训练损失函数表示为:
18、
19、其中,sn、tn表示不同语言的语料。
20、可选地,在本技术的一个实施例中,将普通文本模态输入跨语言相似度模型之前,还包括:
21、对普通文本模态以句子为单位进行分割,得到处理后的普通文本模态;
22、将处理后的普通文本模态输入跨语言相似度模型,输出第一向量数据,包括:
23、将处理后的普通文本模态向量化,生成语义矩阵;
24、利用余弦相似度、对语义矩阵中的每个语义向量,在待匹配文章的语义矩阵中进行召回匹配,生成每个待匹配文章的相似语义矩阵;
25、基于语义矩阵和每个待匹配文章的相似语义矩阵确定普通文本模态与每个待匹配文章的语义相似度。
26、可选地,在本技术的一个实施例中,对于语义矩阵s1中每一个语义向量a都有对应的待匹配文章语义矩阵s2中的相似语义向量b,
27、
28、其中,x表示语义矩阵s2中一个语义向量;
29、基于语义矩阵s1中每一个语义向量a与对应的待匹配文章语义矩阵s2中的相似语义向量b构成相似语义矩阵s3,s1={a1,a2,…,an},s3={b1,b2,…,bn},普通文本模态与待匹配文章的语义相似度表示为:
30、
31、其中,ai为语义矩阵s1中的第i个元素,bi为与ai对应的相似语义矩阵s3中的第i个元素。
32、可选地,在本技术的一个实施例中,将第一向量数据、第二向量数据和第三向量数据输入多模态融合学习模型,输出检测结果,包括:
33、利用晚融合的方式,采用高斯朴素贝叶斯模型作为多模态融合学习模型,将文本相似度、图像相似度与结构相似度融合,得到检测结果。
34、可选地,在本技术的一个实施例中,训练多模态融合学习模型,包括:
35、获取训练数据集;
36、使用训练数据集对多模态融合学习模型进行训练,在训练时采用权重更新参数,提升数据集中正样本对模型更新的权重,降低数据集中负样本对模型更新的权重,其中,权重公式表示为:
37、
38、其中,α为正样本更新时的权重,β为负样本更新时的权重,n为样本总数,n1为正样本数量,n2为负样本数量。
39、为达上述目的,本技术第二方面实施例提出了一种多模态跨语言检测装置,包括论文解析模块、跨语言文本相似度计算模块、图像相似度计算模块、相似度融合模块,其中,
40、论文解析模块,用于获取论文原始数据,并通过解析工具将论文原始数据分解为普通文本模态、结构文本模态和图像模态;
41、跨语言文本相似度计算模块,用于将普通文本模态输入跨语言相似度模型,输出第一向量数据,并将结构文本模态输入跨语言相似度模型,输出第二向量数据;
42、图像相似度计算模块,用于将图像模态输入图像相似度模型,输出第三向量数据;
43、相似度融合模块,用于将第一向量数据、第二向量数据和第三向量数据输入多模态融合学习模型,输出检测结果。
44、本技术附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实践了解到。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196462.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。