一种零样本对话状态追踪方法
- 国知局
- 2024-07-31 23:24:45
本发明属于文本生成领域,涉及从任务型对话数据中抽取对话状态(用户目标、用户需求)的若干技术方法,具体为一种基于预训练模型和混合语义专家的对话状态追踪方法。
背景技术:
1、对话状态追踪(dialogue state tracking,dst)在任务驱动的对话系统中扮演着举足轻重的角色。该任务的目标是理解用户的需求和目标,提取对话状态。对话状态指的是由多个槽-值对构成的集合。准确的对话状态追踪性能能够帮助下游模块,例如对话管理器。
2、但是收集和标注对话状态及其的困难和昂贵。随着单领域到多领域对话的出现,该问题变得更加尖锐。为了训练一个多领域到对话状态追踪模型,对话标注者必须为对话的每一轮和每个领域标注槽值对。为了使对话状态模型更具有健壮性,各种各样的模型从数据层面或模型层面来提升零样本性能。第一类方法是合成新的对话样本或者引入其他大规模的标注数据集。其中一些利用已有的本体信息和标注数据集来合成新的对话。另一部分工作利用多种标注数据集,例如问答数据集(question answer,qa)和对话摘要(dialogue summarization),来克服数据稀疏问题。这类使用其他任务数据集的方法也被称之为零样本跨任务的迁移方法。第二类方法是发展高效的模型或者框架来提升对话状态追踪模型的可扩展性,例如基于跨度的方法(span-based approach),拷贝增强的解码器(copy-augmented decoder)或者大规模的预训练语言模型(pre-trained languagemodel)。在对话状态追踪任务中,已经有人利用槽的描述信息作为提示(prompt)来生成槽值结果;还有人基于提示来建模在槽上三种依赖关系进一步提升了零样本的性能。尽管已有模型取得一定的成效,我们认为这些数据或模型层面的增强方法并没有探索零样本泛化的本质,主要是缺乏语义解耦的能力来映射未见样本到已见样本的区域。
3、为了直观地解释语义空间中的可见样本如何帮助未见样本,我们给出一个样例。假设有一个未见样本来自于“火车”领域,该样本为“我计划周日坐火车从北京到香港旅行”,“预定房间”的对话语义空间可以帮助预测未见槽“火车预定时间”;“预定出租车”的对话语义空间可以帮助预测“火车出发地”槽和“火车到达地”槽。也就是说,一个新的未见样本由于其复杂的组合可能很难直接推理,但是可以通过相关语义的映射来容易地预测。但是语义层面的解耦一直以来都具有挑战性和不稳定性,特别是对于那些需要准确语义划分的场景。
技术实现思路
1、针对现有技术中存在的问题,本发明的目的在于提供一种基于预训练模型和混合语义专家的零样本对话状态追踪方法。本发明提出了一个简单但高效的解决方案——划分、解决和合并来将未见样本映射到相应准确的语义专家。该思想通过明确地划分可见样本到不同的语义空间并且训练相应的专家,这样的数据层面的解耦提供了映射未见样本到相应语义专家的灵活性。最终来自多个混合专家的预测结果能够提升零样本的表现性能。在实验中,我们实现该方案在当下的预训练模型t5和适配器(adapter),并且验证了该方法的有效性和通用性。
2、本发明的技术方案为:
3、一种零样本对话状态追踪方法,其步骤包括:
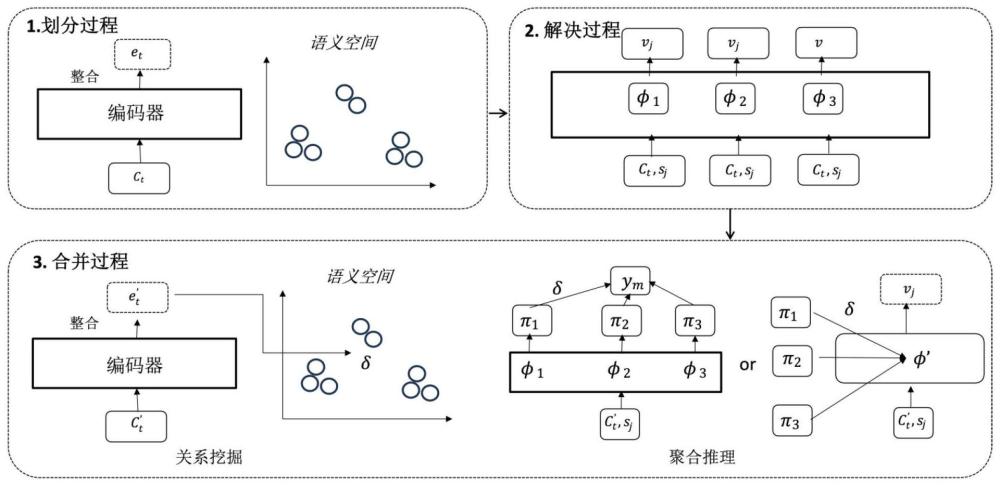
4、1)划分阶段:对于每一段对话状态标注的对话文本ct,利用预训练语言模型f将对话文本ct转换成对话文本向量et,然后利用聚类技术将各对话文本向量归类到其不同的子集中,得到k个子集;
5、2)解决阶段:将子集中的每一文本向量作为一个样本,分别利用所得每一子集训练语义独立的状态追踪模型,共得到k个训练后的状态追踪模型;
6、3)合并阶段:首先进行关系挖掘,将一个给定的对话文本c′t转换为语义向量e′t,计算每一子集的语义空间和对话文本c′t之间的关系δ;然后进行聚合推理,根据每一训练后的状态追踪模型及其对应的关系δ预测该对话文本c′t对应的对话状态。
7、进一步的,第k个子集对应的语义空间μk和对话文本c′t之间的关系其中,d代表距离函数,τ代表温度系数。
8、进一步的,通过平均第k个子集中的所有文本向量得到对应的语义空间μk。
9、进一步的,采用参数级别的聚合推理,预测该对话文本c′t对应的对话状态,其方法为:利用第k个子集对应的语义空间μk和对话文本c′t之间的关系δ(c′t,μk)和利用第k个子集训练后的状态追踪模型参数初始化一个新的对话状态追踪模型,然将所得k个新的对话状态追踪模型求和得到模型然后利用模型φ’预测该对话文本c′t对应的对话状态。
10、进一步的,采用字符级别的聚合推理,预测该对话文本c′t对应的对话状态,其方法为:首先利用第k个子集训练后的状态追踪模型预测该对话文本c′t对应的对话状态πk,然后利用第k个子集对应的语义空间μk和对话文本c′t之间的关系δ(c′t,μk)和对应的对话状态πk预测该对话文本c′t最终的对话状态中每一字符的预测结果ym为该对话文本c′t中第m个字符的预测结果。
11、进一步的,使用预训练语言模型t5作为状态追踪模型。
12、进一步的,所述预训练语言模型f为预训练语言模型t5或者bert。
13、一种服务器,其特征在于,包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行上述方法中各步骤的指令。
14、一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述方法的步骤。
15、本发明的优点如下:
16、本发明将模型在multiwoz上的性能与几个重要的基准进行比较。实验结果表明,本发明的模型在多个领域的零样本迁移任务上都达到了较好的效果。具体结果见下表1。
17、表1不同模型在零样本上的实验结果
18、 model attraction hotel restaurant taxi train average trade 19.87 13.70 11.52 60.58 22.37 25.67 ma-dst 22.46 16.28 13.56 59.27 22.76 26.87 t5-dst 35.51 22.48 25.04 65.93 37.82 37.36 transferqa 31.25 22.72 26.28 61.87 36.72 35.77 ours(param) 41.28 26.15 31.05 66.64 38.72 40.76 ours(token) 41.35 22.72 33.76 66.90 43.81 42.71
19、为了理解每一个阶段的作用,本发明还进行了消融实验,证明了各个阶段的有效性。首先研究了不同的聚类算法,包括kmeans、birch、agglomerative和gmm在旅馆领域上的效果。根据实现结果,发现所有的聚类效果都比直接使用t5模型,不使用聚类的方法好,因此也证明了本发明框架的有效性和稳定性;此外,通过对比发现gmm算法实现了最佳的结果,但是kmeans算法在字符级别的结果也很不错。因此本发明认为更高效的聚类算法能带来更好的性能提升。
20、本发明通过另外实验观察了划分个数数的影响。通过在旅馆领域上的实验了具有不同k值的模型。发现联合目标的准确性表现首先随着k的值而增加,然后在t5基础上减少。结果表明,对于t5小,子集的最优数目为2,对于t5基本型号。注意到本发明的模型取决于数据分布和数据分区,这意味着零样本性能可能而不是随着k的增加而线性增加。
21、本发明还实验观察了不同的映射方法。将看不见的样本映射到现有子集和获取映射权重是合并过程的核心。除了通过从训练的聚类模型推断采用权重外,本发明还尝试了其他两个权重:1)argmax:为具有最大映射概率的子集分配1,为其他子集分配0;2)average:为所有子集分配均匀概率。实验结果表面,直接利用推理权重显示出最佳参数级和令牌级集成推理的性能。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197406.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表