用于运行听力设备的方法以及听力设备与流程
- 国知局
- 2024-08-02 13:55:47
本发明涉及一种用于运行听力设备的方法,尤其是涉及一种用于调节听力设备的ov处理单元的方法。此外,本发明涉及一种对应的听力设备。
背景技术:
1、听力设备用于供应听力受损的用户,因此用于补偿这种用户的对应的听力损失。为此,听力设备通常具有麦克风、信号处理单元和听筒。麦克风产生输入信号,将该输入信号馈送到信号处理单元。信号处理单元对输入信号进行修改,并且由此产生输出信号。为了补偿听力损失,例如根据用户的听力图,以与频率相关的放大因子对输入信号进行放大。最后借助听筒将输出信号输出给用户。以这种方式,将修改后的环境的声音信号输出给用户。输入信号和输出信号相应地是电信号。相反,环境的声音信号和由听筒输出的声音信号是声学信号。
2、如果用户自己说话,将在输入信号中重新得到他自己的声音,并且也对应地重新将他自己的声音与输出信号一起输出给用户。听力设备对用户自己的声音的这种再现是特别重要的,通常决定了用户对听力设备的接受程度。已经证明,许多用户对他们自己的声音的感知特别敏感。对应地,希望尽可能根据用户的想法和偏好,通过听力设备输出用户自己的声音。
技术实现思路
1、在这种背景下,本发明要解决的技术问题是,改善听力设备的运行,尤其是在听力设备的用户自己的声音的再现方面改善听力设备的运行。为此,要给出一种对应的方法以及一种对应的听力设备。
2、根据本发明,上述技术问题通过具有根据权利要求1的特征的方法以及通过具有根据权利要求12的特征的听力设备来解决。有利的设计方案、扩展方案和变形方案是下面的描述的主题。结合方法进行的描述同样也适用于听力设备。如果下面明示地或者暗示地描述方法的步骤,则通过听力设备具有控制单元,该控制单元被构造为用于执行这些步骤中的一个或多个,来得到听力设备的优选的设计方案。
3、该方法用于运行用户的听力设备。用户具有自己的声音。运行特别是在用户在日常常规使用听力设备期间并且在用户将听力设备佩戴在耳朵中或耳朵上期间进行。
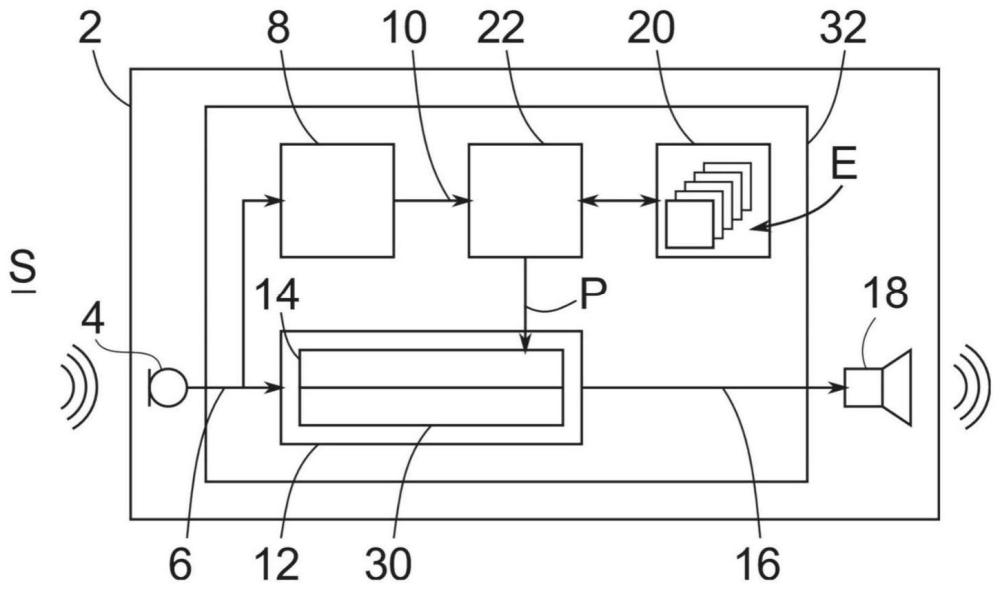
4、听力设备具有输入转换器,该输入转换器产生输入信号。输入转换器优选是麦克风。
5、此外,听力设备具有分析单元,该分析单元根据输入信号识别当前的场景、特别是自身声音场景。场景一般是给定时间、给定地点的(更准确地说是听力设备的)用户的声学环境,并且主要通过环境中的一个或多个噪声源(例如说话人、机器、自然环境等等)和对应的噪声(例如诸如语音或音乐的有用噪声、干扰噪声、自然环境噪声等等)以及通过环境的声学特性(例如具有/没有背景噪声、室内/室外、具有混响/没有混响等等)来表征。作为其结果,即作为识别当前的场景的结果,分析单元输出给出当前的场景的场景信号。在一个合适的设计方案中,分析单元包含分类器,将输入信号馈送到该分类器,然后该分类器对输入信号进行分析,例如进行谱分析,并且作为结果,即作为场景信号,输出场景类别,例如安静的环境中的语音、具有干扰噪声的语音、多个说话人、1对1对话、音乐、没有语音的安静的环境、没有语音的干扰噪声等等。
6、此外,听力设备具有信号处理单元,该信号处理单元具有ov处理单元。缩写ov一般意为“own voice”,即自己的声音或自身声音,由此是指听力设备的用户自己的声音。ov处理单元对应地是自身声音处理单元。利用信号处理单元将输入信号处理为输出信号。在此,利用ov处理单元根据多个ov参数对用户自己的声音进行处理。“多个”一般应当理解为“一个或多个”或者“至少一个”。例如,为此,事先从输入信号中分离或者甚至滤出自己的声音,然后进行处理,最后重新与输入信号合并,以形成输出信号。也可以总体上以恰好对属于自己的声音的部分进行处理的方式,对输入信号进行处理。现在,依据当前的场景(即依据分析单元的场景信号)调整ov参数,从而对自己的声音的处理是与场景相关的。ov参数影响特别是在音量、时间动态特性和/或频谱方面如何影响自己的声音,并且对应地给出例如衰减/放大、频率偏移、压缩、延迟等,该衰减/放大、频率偏移、压缩、延迟等然后利用ov处理单元针对性地针对自己的声音(例如以局限于相关的频率范围的方式)来实现。
7、最后,听力设备具有输出转换器,并且利用该输出转换器将输出信号输出给用户,因此也再现处理后的自己的声音。优选输出转换器是听筒。输入信号和输出信号特别是相应地是电信号。
8、本发明的核心思想是,对用户自己的声音进行与场景相关的处理(也即:修改)。为此,对应地首先在第一步骤中识别当前的场景,然后在第二步骤中选择ov参数的对应的设置并且进行调整,使得ov处理单元在不同的场景中对自己的声音进行不同的处理,即依据尤其是与场景相关地调整的ov参数对自己的声音进行不同的处理。对于多个场景中的每一个,在当前的场景对应于对应的场景时,存储对应的设置,该对应的设置然后被激活。其结果是,在不同的场景中也将用户自己的声音不同地输出给用户,即,特别是每一次尽可能最佳地将用户自己的声音匹配于相应的场景。
9、本发明特别是基于如下观察,即,对于不同的场景,即在不同的环境和不同的交流情形中,对自己的声音的再现的要求,例如在强度、频谱和/或时间动态特性方面,是不同的。许多用户特别敏感地对自己的声音的再现作出反应,不是最佳的再现经常导致听力设备被拒绝。原则上有利的是,至少针对单个特定的场景确定针对自己的声音的再现的设置,并且每当与整个场景无关地识别出自己的声音时,调整针对自己的声音的再现的设置。该单个特定的场景通常是“安静的环境中的自己的声音”,即在整个环境总体上是安静的期间(即“处于安静中”,例如被隔离在没有其它噪声源的空间中,或者自己的声音之外的所有噪声具有最大40db的水平),并且在另外也没有其他人员说话期间,用户说话。在这种情形下,自己的声音对于用户来说最大地突出,因此确定针对这种场景的ov参数是特别适宜的。然而,用户的音量、频谱和/或时间动态特性依据用户是在安静的环境中说话、还是作为一个群体中的几个人之一说话,不仅在生理上、而且在心理上(依据用户的个性、交流类型、对自己的声音的自我感知等)不同。这具有不同的原因。在进化过程中观察到,人们通常希望避免自己的声音掩盖另一种潜在的有趣的、危险的声音,一般地说相关的声音。附加地,人们尤其是对其他人如何感知自己的声音很敏感,并且人们将依据说话情形,一般地说依据当前的场景,来改变其声音(音量、频谱、时间动态特性等等)。例如,与仅与单个人员交流的场景相比,在同时与多个人员交流的场景中,自己的声音将不同(例如更大)。如上面所描述的在具有安静的环境的场景中确定的单个设置对应地对于有时显著不同的其它场景将不是最佳的,尤其是在包含还存在其它陌生的声音的交流情形的场景中。在此,该问题通过ov处理单元的与场景相关的设置来解决,因为由此针对多个不同的场景提供自己的相应地最佳的设置,然后在存在相应的场景时也激活、即使用这些设置。
10、适宜听力设备具有存储器,在该存储器中存储ov参数的多个设置,即针对一个由分析单元能够识别出的场景存储一个设置。适宜在匹配会话a(“fitting session(适配会话)”)的过程中,例如在听力设备声学专家或者其他专业人员处,特别是预先确定设置并且将其存储在存储器中。但是原则上也可以在听力设备运行时进行确定和存储,或者例如也可以在听力设备的更新过程中进行事后存储。
11、优选分析单元相对于彼此区分存在自己的声音的至少两个场景,因此对于ov参数,存在、特别是存储并且能够调整至少两个不同的设置。在此,相应地不涉及依据自己的声音的存在的单纯的打开和关闭,而是涉及相应地具有自己的声音的场景的区分,但是还涉及不同的特性,也就是说,涉及在不同的自身声音场景(或者也称为自身声音情形)中对自己的声音的不同的处理。设置一般仅仅与如下的场景相关,在这些场景中,用户自己说话,因此存在自己的声音,即,在所谓的ov场景中。对于其它场景、即没有自己的声音的场景、即非ov场景,不需要针对ov参数的设置,因为在这些场景中,适合ov处理单元是去激活的,并且至少不对自己的声音进行处理。对应地,原则上存在多个并且能够调整的设置中的每一个与存在自己的声音的一个场景相关联。
12、优选场景中的第一场景是基本场景,对于该基本场景,存在并且能够调整针对ov参数的基本设置,并且场景中的第二场景是衍生场景,对于该衍生场景,存在并且能够调整针对ov参数的衍生设置。在此,衍生设置是从基本设置衍生的。因此,基本设置r形成进一步的设置的创建或定义的原型和起点,该进一步的设置于是对应地从基本设置衍生出。为了进行衍生,由衍生场景和基本场景之间的差异推导出变换函数,利用该变换函数对基本设置进行修改,以获得衍生设置。
13、在一个合适的设计方案中,借助交互模型从基本设置推导出衍生设置,该交互模型对听力受损的用户与其环境的交互进行建模(“hearing impaired speaker-environment interaction(听力受损的说话人-环境交互)”)。听力受损的用户尤其是不一定是这里另外描述的听力设备的具体用户,而是特别是听力受损的用户的一般原型。交互模型特别是对在两个不同的场景之间进行切换时自己的声音的变化进行建模,并且基于例如在初步试验或者研究中已经确定的对应的知识。例如,在toyomura等人的研究“speechlevels:do we talk at the same level as we wish others to and assume they do?(说话水平:我们说话的水平是否与我们希望和假设他人说话的水平相同?)”,acoust.sci.&tech.41,6(2020)中表明,人们将依据对话情形调整其自己的声音的音量。由于交互模型,不需要通过实际追踪不同的场景来确定不同的设置,而确定针对单个场景的设置(针对基本场景的基本设置),然后从其出发借助交互模型计算一个或多个进一步的设置,就足够了。这在这里描述的方法之外进行,或者作为这里描述的方法的一部分。
14、交互模型的其它细节首先是次要的。在一个特别简单的合适的设计方案中,相应地,通过将基本设置与可变作用强度(strength of effect,作用的强度)匹配,来由基本设置得到衍生设置。作用强度例如是0和1之间的因子,将基本设置与该因子相乘。利用交互模型来确定作用强度的值,然后交互模型依据场景输出作用强度的值,例如方式是,将场景的音量水平用作交互模型的输入参数。例如,交互模型针对具有干扰噪声的语音输出作用强度0,而针对没有语音的安静的环境输出作用强度1。过渡是离散的或者是连续的。多维交互模型也是有利的。在一个合适的设计方案中,作用强度一方面取决于场景的干扰噪声水平,另一方面取决于场景的说话人的数量。将没有说话人的安静的环境假设为基本场景,基本设置于是属于该基本场景。随着说话人的数量的增加,提高作用强度,同时随着干扰噪声水平的增加,降低作用强度。通过利用作用强度修改基本设置,于是针对对应地不同的场景产生衍生设置。
15、适宜基本场景通过在安静的环境中仅存在自己的声音(如上面所描述的)来表征。换句话说:用户自己说话,但是不存在其它噪声,尤其是也没有其它声音。因此,基本场景基本上是尽可能仅存在自己的声音的场景。
16、在一个合适的设计方案中,事先在匹配会话(“适配会话”,也参见上面的描述)中单独针对用户,即依据用户个人的特征、例如年龄、性别、个性等,确定了基本设置。例如在听力设备声学专家或其他专业人员处或者至少在听力设备声学专家或其他专业人员的指导下进行匹配会话。也可以由用户自己进行匹配会话,例如通过专业人员借助电话或者借助智能电话以软件引导的方式等等进行指令。重要的是,单独针对用户确定基本设置,从而所有衍生设置也至少初步是单独的。
17、在一个适宜的设计方案中,利用自动设置单元调整ov参数,该设置单元从分析单元接收给出当前的场景的场景信号并且输出ov参数。对应地,设置单元一方面与分析单元、另一方面与信号处理单元连接。设置单元特别地是听力设备的一部分。设置单元特别是也访问存储器,并且依据场景信号自动从存储器中取出相应的相关的设置,然后同样自动控制ov处理单元,从而根据该设置调整ov参数。
18、如上面已经指出的,这里描述的方法最初仅与ov场景相关,即与存在自己的声音的场景相关,因为用户自己说话。在所有其余场景中,一般不需要ov处理单元,因此适宜将ov处理单元去激活。对应地,在此,分析单元适合识别是否存在自己的声音,并且仅当分析单元识别出存在自己的声音时,激活ov处理单元。然后,在这种情况下,与场景相关地调整ov处理单元,即控制对自己的声音的处理。听力设备的运行因此基本上具有两个层面:在第一层面,识别在当前的场景中是否存在自己的声音。如果在当前的场景中存在自己的声音,则激活ov处理单元,并且对自己的声音进行处理,否则将ov处理单元去激活。然后,在第二层面,调整为恰好以何种方式对自己的声音进行处理。这于是与场景相关地进行,从而依据当前的场景最佳地对自己的声音进行处理,因此最终也最佳地、特别是以单独匹配的方式再现自己的声音,即输出给用户。
19、具体如何识别当前的场景本身首先是次要的。更重要的特别地是,区分不同的ov场景。在一个合适的设计方案中,分析单元识别当前的场景,方式是,分析单元根据输入信号确定当前的场景的如下参数中的一个或多个:环境类别、说话人的数量、一个或多个说话人的位置、背景噪声类型、干扰噪声水平、(用户的)运动。因此,特别是对当前的场景进行分类,即将当前的场景与多个类别中的一个相关联。具有自己的声音的场景的合适的类别特别地是:安静的环境中、与多于两个的(陌生)说话人的对话中、1对1对话(用户和单个陌生说话人)中的自己的声音等等。
20、优选信号处理单元具有场景处理单元,利用该场景处理单元,依据当前的场景,除了自己的声音之外,将输入信号处理为输出信号。在场景处理单元中,相应地也直接依据场景信号对输入信号进行处理,而不仅仅间接地通过ov处理单元对输入信号进行处理,该ov处理单元事先从场景信号推导出ov参数。除了对自己的声音的处理之外,相应地也对环境中的其余噪声进行处理。由此,特别是实现听力设备的原来的功能,即,供应特别是听力受损的用户,因此补偿用户的对应的听力损失。为了补偿听力损失,借助场景处理单元,例如根据用户的听力图,将输入信号乘以与频率相关的放大因子。以这种方式,将环境的声音信号以考虑听力图进行了修改的方式输出给用户。上面在引言中进行的描述特别是也适用于这里描述的根据本发明的听力设备。听力设备特别地是单耳听力设备或者双耳听力设备。
21、根据本发明的听力设备具有控制单元,该控制单元被构造为用于执行前面描述的方法。上面提到的单元(分析单元、信号处理单元、ov处理单元、场景处理单元、设置单元)中的一个或多个或者存储器或者其组合优选是听力设备的控制单元的一部分。
本文地址:https://www.jishuxx.com/zhuanli/20240801/241127.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表