一种基于相似度匹配的汽车CAN总线报文解析方法
- 国知局
- 2024-08-02 13:57:21
本发明属于电子,具体涉及一种基于相似度匹配的汽车can总线报文解析方法。
背景技术:
1、can总线是德国bosch公司在20世纪80年代初为解决现代汽车中众多的控制与测试仪器之间的数据交换而开发的一种串行数据通信协议;它是一种多主总线,通信介质可以是双绞线、同轴电缆或光导纤维,通信速率可达1mb/s;由于其具有通信速度快、可靠性高和性能价格比好等突出优点,是国际上应用最广泛的现场总线之一;目前汽车行业竞品车之间的对标已经从传统的对结构、零部件、功能等外在的分析,转变为对性能、策略、电子电气等方面的分析;大众、特斯拉已经引领了汽车电气架构从分布式、模块化向集中式、融合式发展;新能源汽车电气化程度更高,电控系统复杂,can总线成为系统信息交互的载体;因而通过采集、分析总线信号,分析车辆的性能、功能特性及电气系统已经成为目前竞品分析的主要趋势;为了更好地观测、分析竞品车及部件的实时运行状况,除了要让操作人员熟悉can报文数据的变化规律和dbc文档的格式规范,也应重视在未知dbc文档情况下对汽车can总线报文中车辆信号的解析工作,从而有效地对竞品车辆的性能和功能特效进行分析,助力我国自主化汽车的技术研发。
技术实现思路
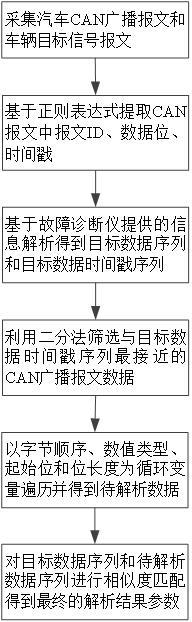
1、为解决上述问题,本发明公开了一种基于相似度匹配的汽车can总线报文解析方法,利用正则表达式提取报文中的报文id、数据位和时间戳,根据汽车故障诊断仪提供的目标信号报文解析参数将目标信号报文数据解析为目标数据,并利用二分法在can广播报文中筛选与目标信号报文时间戳最接近的can广播报文数据,基于皮尔逊系数对待解析数据和目标数据进行相似度匹配,能够提高can报文解析的效率,有效的保证未知竞品车型dbc文档时对竞品车型关键信号的解析。
2、为达到上述目的,本发明的技术方案如下:
3、一种基于相似度匹配的汽车can总线报文解析方法,包括如下步骤:
4、(1)利用can卡、汽车故障诊断仪同步采集一段时间内的汽车can广播报文和车辆目标信号报文数据;
5、(2)利用正则表达式分别提取出每条can报文中的报文id、十六进制数据位、时间戳;
6、(3)根据汽车故障诊断仪提供的车辆目标信号报文解析参数,解析车辆目标信号报文获得车辆目标信号的十进制目标数据序列以及对应的目标数据时间戳序列;
7、(4)根据报文id遍历can广播报文,基于二分法从遍历的can广播报文中筛选出与上述目标数据时间戳序列最接近的can广播报文数据;
8、(5)基于穷举思想以字节顺序(motorola/intel)、数值类型(signed/unsigned)、起始位和位长度参数作为循环变量进行遍历,利用循环变量将上述筛选后的can广播报文数据转化为十进制数据,并记为待解析数据;
9、(6)基于皮尔逊系数对上述的待解析数据序列和目标数据序列进行相似度匹配,穷举结果中相似度最高时对应的解析参数即为车辆目标信号的can报文解析结果参数。
10、进一步的,所述步骤(1)的具体步骤如下:
11、首先开启can卡采集汽车can广播报文,然后立即开启汽车故障诊断仪并对目标信号进行测试,can卡同时会采集到故障诊断仪测试信号的响应报文。
12、进一步的,所述步骤(2)的具体步骤为:
13、can卡采集的can广播报文和故障诊断仪测试信号的响应报文保存在同一can报文文件中并共用同一时间基准,为后续进行解析需要按照正则表达式提取出can报文文件中每条can报文的报文id、十六进制数据位、时间戳,所使用的正则表达式如下所示:
14、"^\\s+(\\d+.\\d+)\\s+\\d\\s+(\\w+)\\s+\\w+\\s+\\w+\\s+(\\d)\\s([\\w+\\s]+)\\s+\\w+\\.*"
15、其中(\\d+.\\d+)为时间戳部分,(\\w+)为报文id部分,([\\w+\\s]+)为十六进制数据位部分。
16、进一步的,所述步骤(3)的具体步骤为:
17、汽车故障诊断仪会提供测试信号的响应can报文的解析参数(报文id、字节顺序、数值类型、起始位、位长度、系数因子、偏移量),首先根据can报文id从步骤(2)所得的数据中选取到所有响应can报文对应的数据,并将十六进制报文数据转化为二进制报文数据,再利用起始位、位长度、字节顺序(motorola/intel)从二进制报文数据中截取出该车辆目标信号对应的有效部分作为有效二进制数据,进而结合数值类型(signed/unsigned)将有效二进制数据转化为有效十进制数据,最终利用公式将有效十进制数据转化为车辆目标信号真实数据,公式如下:
18、targetlist=factortarget*targetlistdecimal+offsettarget
19、其中targetlist为车辆目标信号真实数据,targetlistdecimal为有效十进制数据,factortarget、offsettarget分别为车辆目标信号解析参数中的系数因子和偏移量,同时将targetlist对应的报文时间戳记为targettimelist。
20、进一步的,所述步骤(4)的具体步骤如下:
21、(4.1)遍历can广播报文的报文id,根据报文id从步骤(2)所得的数据中取出十六进制广播报文数据currentdatalist以及对应的时间戳currenttimelist。
22、(4.2)判断can广播报文数据时间戳序列currenttimelist和车辆目标信号真实数据时间戳序列targettimelist的重叠区间,再分别截取出时间戳重叠区间对应的can广播报文数据currentdatalist和车辆目标信号真实数据targetlist。
23、(4.3)时间戳重叠区间中,将目标信号真实数据时间戳记为targettimelistnew,再以targettimelistnew序列的元素个数为基准,在can广播报文数据时间戳列表currenttimelist中利用二分法查找与targettimelistnew各个元素时间间隔最小的currenttimelist元素并保存为currenttimelistnew,从而形成targettimelistnew序列元素和currenttimelistnew序列元素的一对一映射关系。将与currenttimelistnew一一对应的can广播报文数据记为currentdatalistnew,将与targettimelistnew一一对应的车辆目标信号真实数据记为targetlistnew。
24、后续can报文解析的can广播报文序列即为currentdatalistnew,对应的时间戳序列即为currenttimelistnew,车辆目标信号数据序列即为targetlistnew,对应的时间戳序列即为targettimelistnew。
25、进一步的,所述步骤(5)的具体步骤为:
26、(5.1)步骤(4)筛选后的can广播报文数据序列currentdatalistnew中的元素为多字节的十六进制数据(一般为8字节),因此首先将字节顺序、数值类型的所有组合类型作为循环变量(intel+signed、intel+unsigned、motorola+signed、motorola+unsigned)。
27、(5.2)进而穷举所有可能的起始位startbit、位长度length组合,其中由于字节顺序intel、motorola分别对应小端模式和大端模式,大端模式下高字节存低地址,低字节存高地址;小端模式下高字节存高地址,低字节存低地址。而根据can报文的传送规则,单个字节内高低位的顺序从左到右是由高到低。因此当循环变量字节顺序为motorola时需要进行起始位的转换,转换公式如下:
28、startbitlast=(startbit/8)*8+7-startbit%8
29、其中startbit为循环变量中的起始位,startbitlast为最终can报文解析结果参数中的起始位。字节顺序为intel时startbitlast即为startbit。
30、(5.3)使用循环变量字节顺序(intel/motorola)将currentdatalistnew序列中的十六进制数据转化为二进制数据,再使用循环变量起始位startbit、位长度length、数值类型(unsigned/signed)将二进制数据转化为十进制数据。当使用数值类型unsigned、signed结合起始位、位长度进行进制转换时,无符号数值类型unsigned和有符号数值类型signed的区别在于有符号数的最高位是符号位,为1时代表负数,为0时代表正数,而无符号数值类型没有符号位。
31、最终将can广播报文数据序列currentdatalistnew转化为十进制数据后的数据记为待解析数据序列currentdatalistdecimal,解析结果参数中的起始位即为startbitlast,位长度即为length,字节顺序和数值类型即为当前循环遍历中所使用的字节顺序和数值类型。
32、进一步的,所述步骤(6)的具体步骤为:
33、(6.1)利用皮尔逊系数公式计算待解析数据序列currentdatalistdecimal和目标数据序列targetlistnew的相似度,公式如下:
34、
35、其中x代表待解析数据序列currentdatalistdecimal,y代表目标数据序列targetlistnew,ρx,y为两序列间的相关系数,ρx,y的取值范围在±1之间,当ρx,y接近±1时表明观察的两个序列数据线性相关较强,当ρx,y接近0时表明观察的两个序列数据无线性相关,ρx,y为正时两个序列数据为正相关,ρx,y为负时两个序列数据为负相关。
36、(6.2)通过公式计算目标数据序列targetlistnew和待解析数据序列currentdatalistdecimal之间的系数因子及偏移量,计算公式如下:
37、
38、offset=e(y)-factor*e(x)
39、其中x代表待解析数据序列currentdatalistdecimal,y代表目标数据序列targetlistnew,factor为两序列间的系数因子,offset为两序列间的偏移量。
40、当遍历完所有可能的循环变量后,选取相关系数ρx,y最大时的解析参数作为最终的can总线报文解析参数,即报文id、字节顺序(motorola/intel)、数值类型(signed/unsigned)、起始位startbitlast、位长度length、系数因子factor和偏移量offset,从而实现在can广播报文中对于汽车目标信号的解析。
41、本发明的有益效果是:
42、1、本发明提出的can报文解析方法采用二分法从can广播报文中筛选出与目标信号报文时间戳最接近的广播报文数据,能够实现对can广播报文中冗余报文数据的筛除,从而大大提高can报文解析的效率。
43、2、本发明提出的can报文解析方法采用皮尔逊相关性系数对待解析can广播报文数据和车辆目标信号数据进行相似度匹配,能够快速计算can信号和诊断信号的相似度,同时不论是简单还是复杂动态的信号,该方法具有普遍适用性,能够有力的保证对于竞品车型can信号的解析。
44、3、本发明的重要发明点在于,本发明提出了一种基于相似度匹配的汽车can总线报文解析方法,能够根据can卡、汽车故障诊断仪同步采集的汽车can广播报文和车辆目标信号报文,利用正则表达式提取报文中的报文id、数据位和时间戳,根据汽车故障诊断仪提供的目标信号报文解析参数将目标信号报文数据解析为目标数据,采用二分法筛选与目标信号报文时间戳最接近的can广播报文数据,能够有效提高can报文解析的整体效率,基于穷举思想以字节顺序、数值类型、起始位、位长度作为循环变量,根据当前循环变量将筛选后的can广播报文数据解析为待解析数据,再采用皮尔逊系数对待解析数据和目标数据进行相似度匹配,保证了对竞品车型不论是简单还是复杂动态信号的解析。
本文地址:https://www.jishuxx.com/zhuanli/20240801/241228.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表