基于大规模预训练模型的工控协议模糊测试用例生成方法与流程
- 国知局
- 2024-08-02 14:33:09
本发明涉及模糊测试领域,具体涉及基于大规模预训练模型的工控协议模糊测试用例生成方法。
背景技术:
1、本节中的陈述仅提供与本公开相关的背景信息,并且可能不构成现有技术。
2、模糊测试主要通过生成随机化、特异化的测试用例作为程序输入,通过对程序输入进行不断的变异,在此过程中监测程序的异常,从而发掘程序中的脆弱点,可形式化的描述为f(s,t,m)={e | e为模糊测试过程中产生和记录的异常},其中s代表初始输入的集合,t代表测试目标,m代表对s的变异方法的集合,其核心思想是将自动化或者半自动化生成的数据输入到一个程序中,同时监视程序的运行状态,如果程序出现崩溃、断言、超时等错误,则对其进行记录,从而发现程序的非预期行为,进而判断程序是否出现错误,常用于软件测试与漏洞挖掘领域。
3、在模糊测试的过程中,测试用例的生成效率将严重影响模糊测试的效率,这里的效率不单单指速度,因为现有模糊测试采用各类优化算法已经使得用例生成速度大大提高,这里的效率指的是用例能够触发的程序路径的数量,可称之为覆盖率,用例生成速度即使再快,如果只是在重复路径上反复测试,效率也是极为低下的。因此,基于模糊测试的用例生成方法,模糊测试大体可以划分为两类,一是基于生成的模糊测试(generation-basedfuzzing),一是基于变异的模糊测试(mutation-based fuzzing)。
4、在工业协议的集成测试验证与漏洞挖掘领域,模糊测试是经常使用的一种方法,针对工业协议的集成测试验证,是基于事先知晓工业协议构造、定义、状态、结构等系列先验知识,是一种“白盒化”的模糊测试;而在工业协议漏洞挖掘领域,使用者往往面临的是纯黑盒条件,不知道工业协议设计过程中的构造、定义、状态、结构等细节,并且也无法获知协议实现过程中的数据结构、算法、编程语言等信息,甚至于目标的崩溃调试信息都难以获取,这种现状,给黑盒条件下的工业协议模糊测试造成了极大的困难。
技术实现思路
1、本发明主要解决的技术问题包含以下三个:
2、(1)黑盒条件下海量工控协议数据格式与状态转译知识的获取
3、进行大模型的预训练/训练,需要大量的数据支撑,如果没有足够的数据格式与协议状态的先验知识,会导致无法训练出准确的机器模型,从而导致基于该模型生成的数据无法符合工控协议范式,进一步使得模糊测试的效率降低。因此,黑盒条件下获取海量工控协议数据格式与状态知识,是首先需要解决的问题。
4、(2)工控协议数据报文字段特征表征与抽取
5、在获取海量协议格式与状态知识后,如果合理的对这些数据报文中的各个字段进行表征,如何合理的抽取字段特征并进行相关标注,这是第二个需要解决的问题,标注准确度这会直接影响模型训练的效果。
6、(3)泛化性协议知识大模型构建与训练
7、选定模型的种类,配置参数的多少,如何有针对性的构建工控协议训练数据集、选择合理模型训练方法,将其训练为针对任何协议甚至未知工控协议都有效的,具备较强泛化能力的工控协议知识模型,是需要解决的第三个难题。
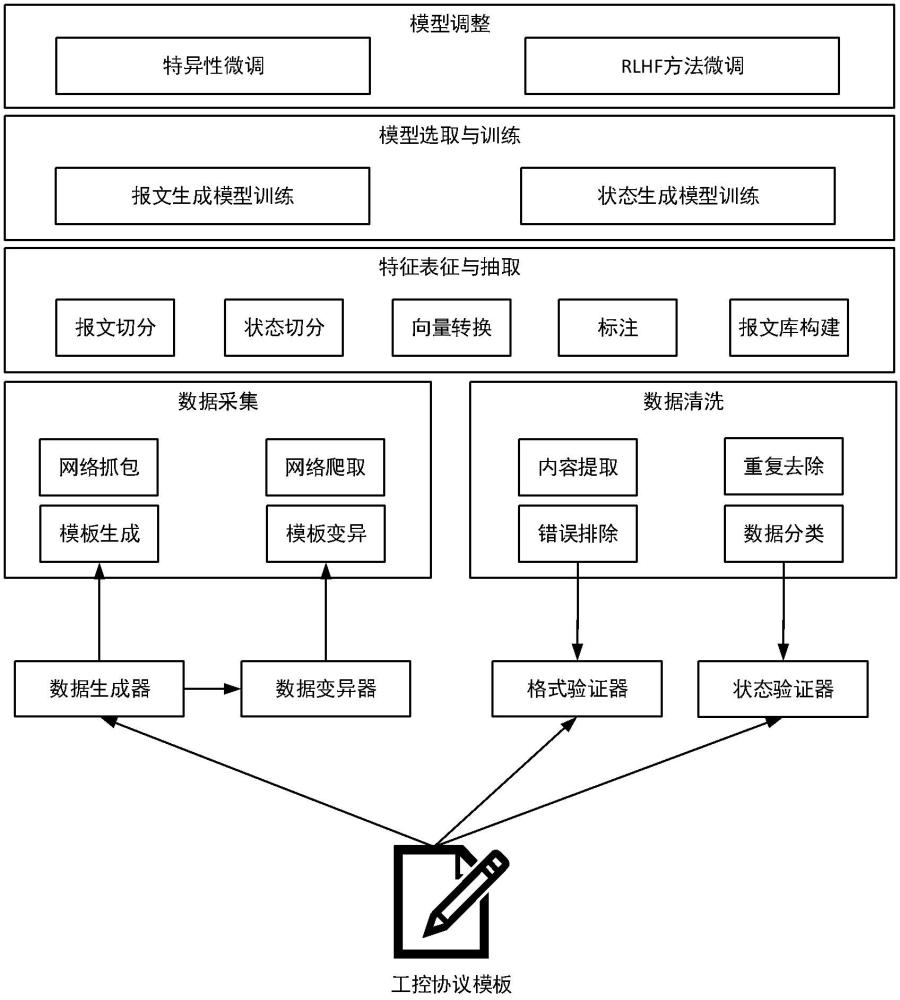
8、本发明针对上述问题,提供了基于大规模预训练模型的工控协议模糊测试用例生成方法,如图1所示,基于smart fuzz技术,定义协议模板定义,编写脚本实现协议模板的解析、数据生成和变异,用于完成数据采集、数据清洗、特征表征与抽取、模型训练及模型调整的相关工作,整体工作流程分为两个部分,一是构建与调整模型的过程,如图2所示,二是使用模型过程,如图3所示,从而解决了上述问题。
9、本发明的技术方案如下:
10、基于大规模预训练模型的工控协议模糊测试用例生成方法,包括:
11、步骤s1:数据采集;获取大模型训练所需要的协议数据包集合;
12、步骤s2:数据清洗;对步骤s1获取的协议数据包集合进行清洗,得到符合工控协议内容、便于下一步处理的数据集;
13、步骤s3:数据特征表征与抽取;对协议数据包报文内容进行切分,构建协议报文切片与协议状态转移路径与上下文关系,对其进行编码,并完成数据标注,同时根据协议状态定义和协议数据报文切片情况构建解码库,并生成训练集;
14、步骤s4:模型选取与训练;选取llama模型作为基础大模型,并通过训练集进行模型训练,分别得到报文分词模型和报文状态模型;
15、步骤s5:输入数据报类型,通过报文分词模型和报文状态模型,分别生成状态路径和状态路径节点对应数据报文。
16、进一步地,所述步骤s1,包括:4种数据采集方法,分别为:网络抓包、网络爬取、模板生成、模板变异;其中,在黑盒条件下,只能使用网络抓包与网络爬取方法,而白盒条件下4种方法均可以使用。
17、进一步地,所述网络抓包,包括:使用抓包工具,抓取协议数据包,即各类工控协议;
18、所述网络爬取,包括:编写爬虫脚本,获取网站上的工控协议pcap包,进行下载收集汇总;
19、所述模板生成,包括:依照工控协议格式,编写成协议模板,确定协议关键字段名称、长度,编写脚本依照协议模板对协议中关键字段的内容进行生成,得到协议数据包;
20、所述模版变异,包括:针对模板生成的工控协议数据包,对其关键字段进行变异操作,生成变异后的协议数据包。
21、进一步地,所述步骤s2,包括:
22、步骤s21:内容提取;从协议数据包集合中,去掉无意义的包头,包括:以太网包头、ip层包头、udp\tcp包头;
23、步骤s22:重复去重;将包头去除之后,针对工控协议包的内容进行去重,去除其中重复的数据包内容;
24、步骤s23:错误排除;编写自动化脚本,将数据包内容、格式、字段与协议模板进行对边,排除明显不合理的数据,这一步骤只在针对白盒条件下的工业协议数据有效,在黑盒条件下,这一步骤直接跳过;
25、步骤s24:数据分类;编写自动化脚本,针对白盒条件下的工业协议,根据协议模板中的协议数据包分类规则,对协议数据内容进行识别,利用分箱法对协议数据包进行分类;针对黑盒条件下的工业协议,则需要使用聚类算法对协议进行初步分类。
26、进一步地,所述步骤s22,包括:
27、步骤s221:建立2个指针q、p,q指向一组协议数据包的第一个数据包,p指向第二个数据包;
28、步骤s222:对比q和p指向的数据包,除时间以外的内容是否相同;
29、步骤s223:如果相同,则删除p指向的数据包,并将p向后移一位;
30、步骤s224:如果不相同,则将q像后移一位,将p也像后移一位,回到步骤s222;
31、步骤s225:当p为空时,结束循环。
32、进一步地,所述步骤s3,包括:
33、步骤s31:报文切分;白盒条件下的报文切分是依据协议定义,对协议单个报文进行解析,解析得到报文的结构、字段、检查点信息之后,对报文进行切割,将不同长度、不同类型的报文切分成不同长度、具备一定上下文关系的语法序列,其切分依据来源是协议模板;黑盒条件下,通过报文序列逆向分析的方法,通过规则匹配、最长字符串匹配、聚类方法对协议的种类、格式、语义进行推断,并且基于该类推断对协议报文进行粗略的划分;
34、步骤s32:状态切分;依据协议模板中对协议状态转移过程的定义,白盒条件下,依据协议定义,对协议的状态图进行遍历,从中依次生成协议状态转移路径的过程;
35、步骤s33:报文库构建;所述报文库构建,包含:报文切片库的构建和报文状态库的构建;所述报文库构建需要对报文切片序列、报文状态序列进行分词处理;
36、步骤s34:向量转换;对分词处理后的结果进行编码,将其转化为一个向量的形式;
37、步骤s35:标注;对向量转换后的数据进行标注,确定数据有效性问题。
38、进一步地,所述步骤s32中的遍历采用的方法,包括:基于深度优先遍历的状态路径生成方法或基于广度优先遍历的协议状态路径生成方法。
39、进一步地,所述步骤s33中分词处理采用的方法,包括:基于word的分词方法、基于最小元素的分词方法或基于subword的分词方法;
40、所述步骤s35中标注采用的方法,包括:基于数据验证的标注、基于输入程序行为的标注或人工选择的数据标注。
41、进一步地,所述步骤s4中的模型训练,包括:
42、步骤s41:词库扩展;将报文库加入词表进行扩展;
43、步骤s42:embeding层重新训练;对embeding层进行重新训练,使其能够适应新的要求;
44、步骤s43:基于sft监督的协议语料微调;首先对大模型进行无监督/半监督预训练,之后,利用步骤s3中采用的标注方法来生成伪标签,将其与人工标注的真实标记数据一起用于有监督/无监督的微调;此处进行微调时,采用lora方法,调整部分参数,减少计算规模,分别训练报文分词模型、报文状态模型,将模型导出使用即可。
45、进一步地,所述步骤s5,还包括:模型调整;
46、所述模型调整,包括:基于奖励模型条件下的模型调整、rlhf条件下的模型调整。
47、与现有的技术相比本发明的有益效果是:
48、本发明创新性的将大规模预训练模型技术与模糊测试技术相结合,解决了传统基于变异的工控协议模糊测试用例生成方法中,生成样本特异性差、语法理解能力低、推理能力差、泛化能力弱的问题,能够较快的生成具备语法推理能力的特异性模糊测试用例样本,大幅提高了模糊测试的效率。
本文地址:https://www.jishuxx.com/zhuanli/20240801/243126.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。