一种虚拟人音视频剪辑方法、装置、设备及可读存储介质与流程
- 国知局
- 2024-08-02 14:35:14
本申请涉及虚拟人,特别涉及一种虚拟人音视频剪辑方法,还涉及一种虚拟人音视频剪辑装置、电子设备、计算机可读存储介质以及计算机程序产品。
背景技术:
1、视频切片剪辑技术是指将原有的长视频,如关于虚拟人的音视频,筛选出其中的重要、精华部分,切分成若干长度相对较短、内容更精炼的短视频,以有效提高获取视频中信息的效率。
2、目前,视频切片剪辑技术主要为基于人工的视频切片剪辑,即由人工浏览视频后,人工筛选视频中的精华片段,再使用专门的视频剪辑软件将筛选出的片段进行剪辑拼接等处理。然而,人工剪辑首先需要看完整个视频,选择出的片段存在主观性,针对不同的受众人群,可能会遗漏精华片段,或者选择出的片段并不够精华;并且,人工挑选出片段后进行剪辑拼接等操作,会耗费大量时间。
3、因此,如何对虚拟人的音视频数据进行更为高效且准确的剪辑处理,以获得包含有重要信息的音视频切片是本领域技术人员亟待解决的问题。
技术实现思路
1、本申请的目的是提供一种虚拟人音视频剪辑方法,该虚拟人音视频剪辑方法可以对虚拟人的音视频数据进行更为高效且准确的剪辑处理,以便获得包含有重要信息的音视频切片;本申请的另一目的是提供一种虚拟人音视频剪辑装置、电子设备、计算机可读存储介质以及计算机程序产品,均具有上述有益效果。
2、第一方面,本申请公开了一种虚拟人音视频剪辑方法,包括:
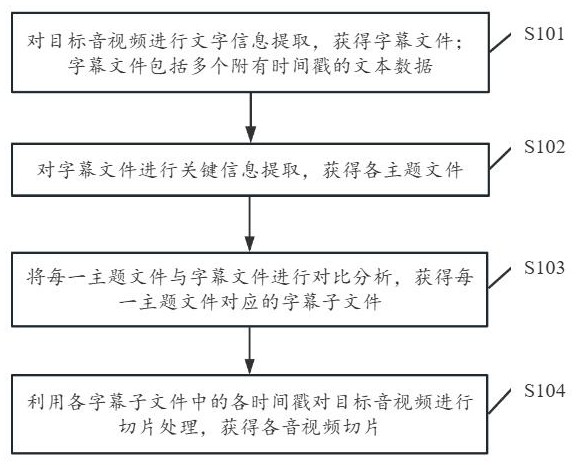
3、对目标音视频进行文字信息提取,获得字幕文件;其中,所述字幕文件包括多个附有时间戳的文本数据;
4、对所述字幕文件进行关键信息提取,获得各主题文件;
5、将每一所述主题文件与所述字幕文件进行对比分析,获得每一所述主题文件对应的字幕子文件;
6、利用各所述字幕子文件中的各时间戳对所述目标音视频进行切片处理,获得各音视频切片。
7、可选地,将每一所述主题文件与所述字幕文件进行对比分析,获得每一所述主题文件对应的字幕子文件,包括:
8、对于每一主题文件,提取得到所述主题文件的第一文本特征;
9、提取得到所述字幕文件的第二文本特征;
10、在所有所述第二文本特征中筛选出与所述第一文本特征的匹配度超出预设阈值的目标文本特征;
11、根据所述目标文本特征在所述字幕文件中提取得到所述主题文件对应的字幕子文件。
12、可选地,利用各所述字幕子文件中的各时间戳对所述目标音视频进行切片处理,获得各音视频切片之后,还包括:
13、对所述音视频切片进行目标识别,获得目标对象;
14、对所述目标对象增设预设特效,以可视化输出带有所述预设特效的音视频切片。
15、可选地,对所述音视频切片进行目标识别,获得目标对象,包括:
16、对所述音视频切片进行人脸检测,获得初始人脸目标;
17、对各所述初始人脸目标进行行为识别,获得存在目标行为的人脸目标;
18、相应地,对所述目标对象增设预设特效,以可视化输出带有所述预设特效的音视频切片,包括:
19、对所述人脸目标增设所述预设特效,以可视化输出带有所述预设特效的音视频切片。
20、可选地,对各所述初始人脸目标进行行为识别,获得存在目标行为的人脸目标,包括:
21、利用光流法对各所述初始人脸目标进行行为识别,获得存在所述目标行为的人脸目标。
22、可选地,利用各所述字幕子文件中的各时间戳对所述目标音视频进行切片处理,获得各音视频切片之后,还包括:
23、对所述音视频切片进行文字信息提取,获得文字数据;
24、将所述文字数据与所述音视频切片进行时间戳对应,以可视化输出带有字幕的音视频切片。
25、可选地,对所述字幕文件进行关键信息提取,获得各主题文件,包括:
26、将所述字幕文件输入至大语言模型,以利用所述大语言模型对所述字幕文件进行关键信息提取,获得各所述主题文件。
27、第二方面,本申请还公开了一种虚拟人音视频剪辑装置,包括:
28、第一提取模块,用于对目标音视频进行文字信息提取,获得字幕文件;其中,所述字幕文件包括多个附有时间戳的文本数据;
29、第二提取模块,用于对所述字幕文件进行关键信息提取,获得各主题文件;
30、对比分析模块,用于将每一所述主题文件与所述字幕文件进行对比分析,获得每一所述主题文件对应的字幕子文件;
31、切片处理模块,用于利用各所述字幕子文件中的各时间戳对所述目标音视频进行切片处理,获得各音视频切片。
32、第三方面,本申请还公开了一种电子设备,包括:
33、存储器,用于存储计算机程序;
34、处理器,用于执行所述计算机程序时实现如上所述的任一种虚拟人音视频剪辑方法的步骤。
35、第四方面,本申请还公开了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的任一种虚拟人音视频剪辑方法的步骤。
36、第五方面,本发明还公开了一种计算机程序产品,包括计算机程序/指令,所述计算机程序/指令被处理器执行时实现如上所述的任一种虚拟人音视频剪辑方法的步骤。
37、本申请提供了一种虚拟人音视频剪辑方法,包括:对目标音视频进行文字信息提取,获得字幕文件;其中,所述字幕文件包括多个附有时间戳的文本数据;对所述字幕文件进行关键信息提取,获得各主题文件;将每一所述主题文件与所述字幕文件进行对比分析,获得每一所述主题文件对应的字幕子文件;利用各所述字幕子文件中的各时间戳对所述目标音视频进行切片处理,获得各音视频切片。
38、应用本申请所提供的技术方案,通过对目标音视频(该目标音视频可以为虚拟人的音视频)进行文字信息提取,获得其对应的包含有时间戳信息的字幕文件,显然,该字幕文件对应于目标音视频中的音频数据,其次通过对字幕文件进行关键信息提取,得到多个较为重要、精华的主题文件,然后通过主题文件与字幕文件的对比分析,得到每一个主题文件对应的字幕子文件,由于字幕文件中的各个文字数据均附带有时间戳,因此,各个字幕子文件中的各个文字数据必然也都附带有时间戳,而各个字幕子文件与主题文件相对应,因此,利用各个字幕子文件中的时间戳对原始的目标音视频进行切片处理,即可获得各个主题文件对应的音视频切片,也即得到较为重要、精华的短音视频,从而实现目标音视频的剪辑处理。由此可见,本技术方案先通过字幕文件自动筛选出精华字幕,再通过精华字幕的时间戳反定位到需要裁切的音视频片段,实现了更为高效且准确的音视频数据剪辑处理,更加方便获取包含有重要信息的音视频切片。
39、本申请所提供的一种虚拟人音视频剪辑装置、电子设备、计算机可读存储介质以及计算机程序产品,同样具有上述技术效果,本申请在此不再赘述。
技术特征:1.一种虚拟人音视频剪辑方法,其特征在于,包括:
2.根据权利要求1所述的虚拟人音视频剪辑方法,其特征在于,将每一所述主题文件与所述字幕文件进行对比分析,获得每一所述主题文件对应的字幕子文件,包括:
3.根据权利要求1所述的虚拟人音视频剪辑方法,其特征在于,利用各所述字幕子文件中的各时间戳对所述目标音视频进行切片处理,获得各音视频切片之后,还包括:
4.根据权利要求3所述的虚拟人音视频剪辑方法,其特征在于,对所述音视频切片进行目标识别,获得目标对象,包括:
5.根据权利要求4所述的虚拟人音视频剪辑方法,其特征在于,对各所述初始人脸目标进行行为识别,获得存在目标行为的人脸目标,包括:
6.根据权利要求1至5任一项所述的虚拟人音视频剪辑方法,其特征在于,利用各所述字幕子文件中的各时间戳对所述目标音视频进行切片处理,获得各音视频切片之后,还包括:
7.根据权利要求1所述的虚拟人音视频剪辑方法,其特征在于,对所述字幕文件进行关键信息提取,获得各主题文件,包括:
8.一种虚拟人音视频剪辑装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述的虚拟人音视频剪辑方法的步骤。
技术总结本申请公开了一种虚拟人音视频剪辑方法、装置、设备及可读存储介质,方法包括:对目标音视频进行文字信息提取,获得字幕文件;其中,所述字幕文件包括多个附有时间戳的文本数据;对所述字幕文件进行关键信息提取,获得各主题文件;将每一所述主题文件与所述字幕文件进行对比分析,获得每一所述主题文件对应的字幕子文件;利用各所述字幕子文件中的各时间戳对所述目标音视频进行切片处理,获得各音视频切片。应用本申请所提供的技术方案,可以对虚拟人的音视频数据进行更为高效且准确的剪辑处理,以便获得包含有重要信息的音视频切片。技术研发人员:林扬胜,郑启君受保护的技术使用者:浙江核新同花顺网络信息股份有限公司技术研发日:技术公布日:2024/7/25本文地址:https://www.jishuxx.com/zhuanli/20240801/243266.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表