一种基于协调强化学习的城市路网集成控制方法
- 国知局
- 2024-08-02 14:47:15
本发明属于强化学习、深度学习和交通控制,具体涉及一种基于协调强化学习的城市路网集成控制方法。
背景技术:
1、传统的交通管理方法通常依赖于静态规则和预定义的控制策略,这在面对复杂多变的城市交通环境时显得力不从心。然而,随着人工智能技术的迅猛发展,强化学习作为一种自适应决策方法,已在交通控制领域展现出巨大的应用潜力。特别是在网联环境下,车辆与交通设施之间的信息交互变得更为高效,为基于深度强化学习的交通控制方法提供了可能。
2、交通信号控制和车辆诱导是两种能够优化交通效率、缓解城市拥堵的两个关键手段。虽然基于深度强化学习的自适应交通控制方法已经在解决复杂交通挑战方面取得了重大进展,但这些方法通常只关注宏观层面的全局优化,而没有充分考虑到个别车辆的微观层面上的具体需求。车速诱导是实现交通流精细动态控制的有效手段,但它往往会忽略实际交通信号控制需求,给驾驶过程带来不确定性。有研究表明,在宏观和微观层面协调交通信号控制和车速诱导,可显著改善交通流的优化和整个路网的交通效率。但当前基于强化学习的交通信号控制与车辆诱导集成优化研究尚显不足,两者之间的协同机理亟待深入探索。此外,公交信号优先控制作为提升交通效率的重要策略,在实际应用中仍面临诸多挑战。特别是在应对实时交通的动态变化时,由于现有算法受到数学假设的束缚,往往难以实现快速响应。
技术实现思路
1、针对现有方法中存在的缺陷和不足,本发明的目的在于提供一种基于协调强化学习的城市路网集成控制方法以对现有技术方案作出改进。
2、该方案实质上是一种网联环境下的车辆诱导与交通信号控制集成优化方法,旨在全面提升城市交通路网的整体通行效率。同时,针对公交信号优先需求,设计综合奖励机制,以驱动学习算法能够实时适应动态复杂的交通流环境。
3、本发明解决其技术问题具体采用的技术方案是:
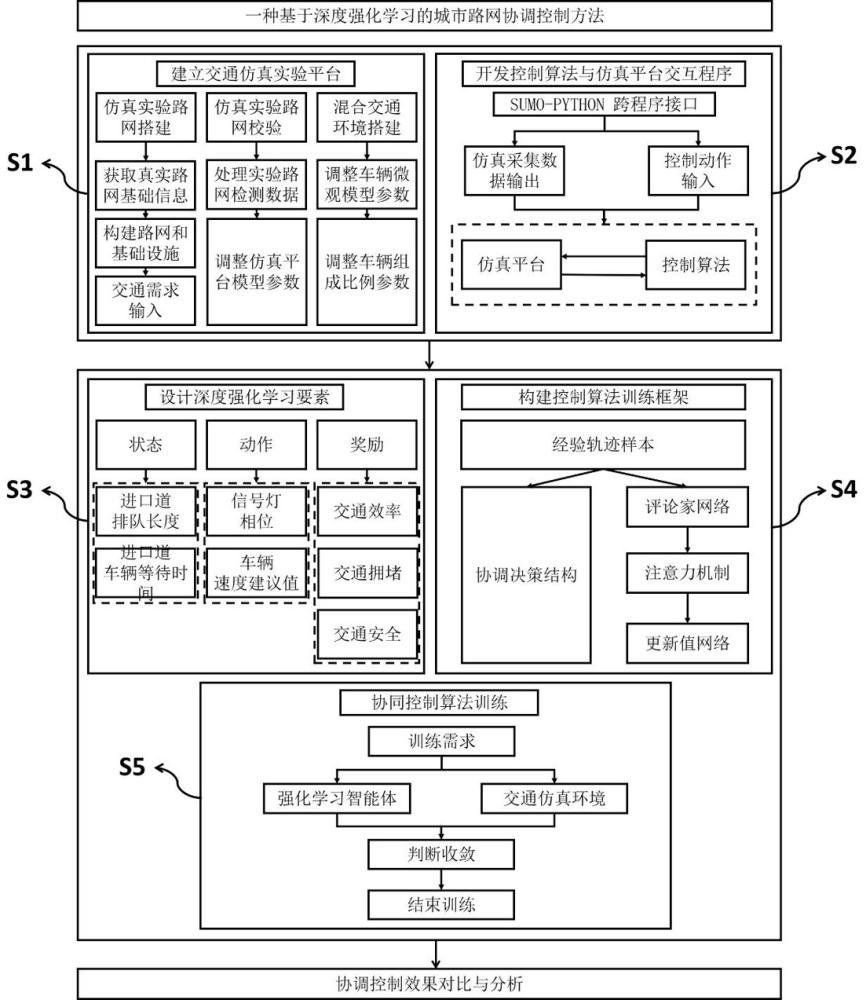
4、一种基于协调强化学习的城市路网集成控制方法,在交通仿真构建包含人类驾驶车辆和网联自动驾驶车辆的网联交通环境的基础上,构建由不同目标导向的双行动者网络组成的协调决策结构;通过采用集中式训练分散式执行学习范式,并结合注意力机制实现双行动者网络间的信息共享,以实现车辆诱导与交通信号控制的协调优化控制;并采用综合奖励机制,根据实际交通需求,为不同车辆动态分配奖励权重,以驱动多智能体之间的动态协调。
5、进一步地,所述交通仿真是利用交通仿真软件sumo基于实际路网及交通需求数据搭建仿真平台作为交互环境;基于合成仿真路网和真实路网分布特征绘制仿真路网,使用涵盖典型交通需求的城市道路流量数据,设置各类车辆微观交通参数,以使仿真路网反映路网真实运行状态。
6、进一步地,所述构建包含人类驾驶车辆和网联自动驾驶车辆的网联交通环境,具体包括设置交通灯或车辆为独立智能体,通过与环境及其他智能互动,并基于感知模块获取环境信息;在每个时间步,智能体从其局部观测中提取特征表示,并与全局状态空间中的信息进行聚合操作;使用深度神经网络结构聚合观测值特征,并引入长短时记忆递归神经网络机制以拓展状态感知范围。
7、进一步地,针对交通信号灯智能体的观测空间包含交叉口状况、车辆分布和当前交通灯信号:
8、
9、其中,wt,i[l]表示进口车道l的等待时间;qt,i[l]表示进口车道l的排队长度;veh[l]代表进口车道l的车辆总数;tvt,i[l]表示公交车的速度情况;ph aset,i为当前交通信号的相位设置
10、针对车辆速度诱导智能体设置相应的观测空间由控制范围内的车辆速度分布情况构成:
11、
12、speedt,i[l]={speedt,i,m},m∈mi[l] (3)
13、m是车辆的索引符号,位于智能体i进口车道l上的车辆集合为mi[l];
14、全局观测空间包含控制区域内交叉口和车辆的交通信息,以便各个智能体能够全面了解交通网络的状态:
15、
16、进一步地,在多智能体强化学习的城市路网协调策略中,建立一个将车辆速度诱导与交通信号灯控制相结合的协调框架;智能体通过选择适当的交通灯相位信号优化交叉口内的交通流,进而制定出备选相位信号方案
17、
18、上式各行分别表示南北向直左、东西向直行、东西向左转、东向直左和西向直左;集成动作空间还包括车辆诱导的推荐速度值,将cav加速度设置为车辆诱导控制动作;在策略执行过程中,智能体将接收行动者网络所输出的车辆速度诱导推荐值和交通灯相位信号
19、进一步地,所述综合奖励机制考虑多个评价指标,至少包括:总等待时间ωt+δt[l]、队列长度qt+δt[l]和平均车速且区分公交车rt,i,transit和其它车辆rt,i,oth ers并赋予它们不同的奖励权重,引入可学习的权重参数δ;根据交通状况和目标需求动态地调整公交车和其他车辆的奖励权重;
20、
21、
22、
23、进一步地,基于双行动者网络的所述协调决策结构,由两个独立的行动者网络组成,一个用于车辆速度诱导,另一个用于交通信号灯控制;两个网络的控制动作输出和优化目标不同;交叉口状态和车辆信息被感知并输入至车速诱导行动者网络πθ,s,输出车辆诱导加速度建议值;交通信号灯行动者网络πθ,t也将交叉口实时状态和车辆信息作为输入,基于相同的神经网络结构拟合特征,最终输出自适应交通信号灯控制方案。
24、进一步地,通过集中式训练分散式执行学习范式,集成车辆速度诱导和交通信号灯协调控制;在训练阶段,所有的智能体通过注意力机制共享全局信息,通过协作学习来优化控制策略;在执行阶段,每个智能体根据局部状态和独立的控制策略进行操作,以实现实时的交通控制。
25、进一步地,智能体从环境中获取能够表征路网实际状况的观测值oi,t,并利用结合lsmt机制的状态处理模块集成状态空间;建立由车速诱导行动者网络πθi,s和交通信号灯行动者网络πθi,t构成的协调决策结构,以确定最佳的交通控制策略:车速诱导行为者网络和交通信号灯行动者网络同时接收到状态si,t后,输出车速推荐值和交通灯相位信号进而,车速诱导智能体通过调整车辆的速度实现精细化控制;交通信号灯智能体执行相位方案优化交通流分布;执行动作后环境发生变化并获得新的观测状态si,t+1;接着,采用面向公交信号优先的综合评价奖励计算每个智能体的奖励值ri,t+1,并根据交通需求实时动态分配道路优先通行权;
26、所有智能体同时采集轨迹样本,并将其存储在重放缓冲区中;在进入评论家网络之前,利用注意力机制整合全局状态信息进行集中训练;评论家网络近似一个包含全局信息的价值函数vi使智能体与其它智能体互动学习合作策略;在分散式执行过程中,智能体利用集中式训练学习到的全局信息,基于可观测的局部状态和独立的控制策略实施动作;
27、为车辆速度诱导行动者网络和交通信号灯行动者网络的损失函数分别如下:
28、
29、
30、其中,sp为单个车辆速度诱导智能体,sp为车辆速度诱导智能体集合,为|b|训练样本量;at,sp与at,ts表示为优势函数,即a=q(s,a)-v(s),q(s,a)是状态-动作值函数,v(s)是状态值函数;
31、车辆速度诱导智能体和交通信号灯智能体的评论家网络分别建模为:
32、
33、
34、其中,通过在评论家网络中的集成注意力机制建立信息交互机制。
35、综合评价奖励机制用于平衡不同任务在不同交通需求条件下的重要程度。
36、进一步地,在训练过程中,首先初始化双行动者网络θi,s和θi,t,以及评论家网络的参数ωi,并设置相关的超参数,包括空间折减因子γ、训练迭代步长t、训练样本量|b|、学习率ηω和ηθ;在每个训练迭代过程中,首先初始化状态空间s0,从环境中收集观测值,并利用lstm机制将观测值进行融合形成状态空间si,t;然后,根据当前状态si,t选择相应动作,包括车速推荐值ai,t,s和交通灯信号ai,t,t,并执行这些动作以改变环境状态;在环境发生变化后,根据综合评价奖励机制计算每个智能体的奖励值ri,t并获得新的状态si,t+1;智能体在训练过程中同时对轨迹进行采样并将其存储在重放缓冲区b中;基于注意力机制聚合路网状态,输出共享信息后的状态表征hi,t;进而,利用梯度下降法更新行动者网络和评论家网络的参数以优化控制策略;最后,当达到终止条件即训练迭代次数m达到时,结束训练并输出最终的控制策略。
37、相比于现有技术,本发明及其优选方案至少包括以下突出优势:
38、(1)提出一种面向网联环境的多智能体强化学习方法,构建了一个由不同目标导向的双行动者网络组成的协调决策架构。通过采用集中式训练分散式执行学习范式,并结合注意力机制实现双行动者网络间的信息共享,从而实现车辆诱导与交通信号控制的协调优化控制。
39、(2)为克服传统rl算法在复杂交通环境中实现公交信号优先控制的局限性,设计一种综合奖励机制。该机制根据实际交通需求,为不同车辆动态分配奖励权重,从而有效驱动多智能体之间的动态协调。
本文地址:https://www.jishuxx.com/zhuanli/20240801/243901.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表