使用神经网络的语音音频压缩的制作方法
- 国知局
- 2024-08-08 16:48:58
背景技术:
1、音频和视频文件是通过各种通信通道(包括互联网)传输、流式传输等的常见类型的媒体文件。高质量音频需要大存储容量和高带宽,特别是对于在线点播服务。音频编解码器可用于编码或压缩数字音频信号以降低音频文件的比特率,其目的是在保留质量的同时,以最小比特数目来表示高保真音频信号。压缩音频文件减少了存储音频文件所需的存储空间和传输所存储的音频文件所需的带宽。
技术实现思路
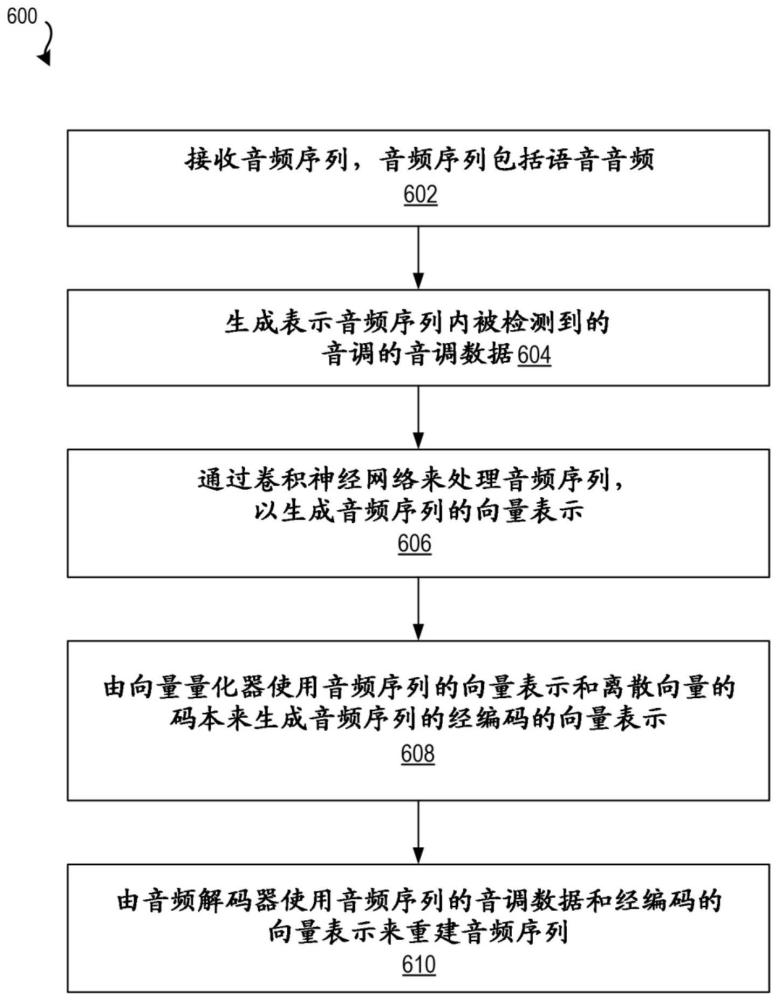
1、本文介绍的是允许音频处理系统训练音频编解码器以使用神经网络来对语音音频序列进行编码(压缩)和解码(重建)的技术。音频编解码器被训练为以低比特率(例如,对于22khz语音流是0.672kbps)压缩语音音频序列,同时保持高音频质量。
2、特别地,在一个或多个实施例中,作为训练过程的一部分,音频处理系统接收包括语音音频(例如,演示、演讲、独白等)的音频序列。使用音调检测算法,生成表示语音音频内检测到的演讲者音调的音调数据。语音音频还被传递通过音频编码器以生成语音音频的向量表示(例如,特征向量)。例如,语音音频可以由表示语音音频的数字特征的多个n维向量来表示。音频处理系统还使用向量量化器,以使用生成的特征向量和离散向量码本(codebook)来生成音频序列的经编码的向量表示。音频解码器然后可以使用音调数据和音频序列的经编码的向量表示来重建音频序列,以及可以基于确定原始音频序列与经重建的音频序列之间的损失来训练音频处理系统。
3、本公开的示例性实施例的附加特征和优点将在以下描述中阐述,并且部分地将从描述中显而易见,或者可以通过这些示例性实施例的实践而获知。
技术特征:1.一种计算机实现的方法,包括:
2.根据权利要求1所述的计算机实现的方法,其中通过所述卷积神经网络处理所述音频序列以生成所述音频序列的所述向量表示包括:
3.根据权利要求1所述的计算机实现的方法,其中通过所述卷积神经网络处理所述音频序列以生成所述音频序列的所述向量表示包括:
4.根据权利要求1所述的计算机实现的方法,还包括:
5.根据权利要求1所述的计算机实现的方法,其中使用所述音调数据和所述音频序列的所述经编码的向量表示来重建所述音频序列包括:
6.根据权利要求1所述的计算机实现的方法,其中生成表示所述音频序列内的所述检测到的音调的所述音调数据包括:
7.根据权利要求1所述的计算机实现的方法,其中使用所述音频序列的所述向量表示和所述离散向量码本来生成所述音频序列的所述经编码的向量表示包括:
8.根据权利要求1所述的计算机实现的方法,其中所述离散向量码本的每个向量表示音素。
9.一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储可执行指令,所述可执行指令在由处理设备执行时使所述处理设备执行操作,所述操作包括:
10.根据权利要求9所述的非暂态计算机可读存储介质,其中为了通过所述卷积神经网络处理所述音频序列以生成所述音频序列的所述向量表示,所述指令还使所述处理设备执行包括以下的操作:
11.根据权利要求9所述的非暂态计算机可读存储介质,其中为了通过所述卷积神经网络处理所述音频序列以生成所述音频序列的所述向量表示,所述指令还使所述处理设备执行包括以下的操作:
12.根据权利要求9所述的非暂态计算机可读存储介质,其中所述指令还使所述处理设备执行包括以下的操作:
13.根据权利要求9所述的非暂态计算机可读存储介质,其中为了使用所述音调数据和所述音频序列的所述经编码的向量表示来重建所述音频序列,所述指令还使所述处理设备执行包括以下的操作:
14.根据权利要求9所述的非暂态计算机可读存储介质,其中为了生成表示所述音频序列内的所述检测到的音调的所述音调数据,所述指令还使所述处理设备执行包括以下的操作:
15.根据权利要求9所述的非暂态计算机可读存储介质,其中为了使用所述音频序列的所述向量表示和所述离散向量码本来生成所述音频序列的所述经编码的向量表示,所述指令还使所述处理设备执行包括以下的操作:
16.根据权利要求9所述的非暂态计算机可读存储介质,其中所述离散向量码本的每个向量表示音素。
17.一种系统,包括:
18.根据权利要求17所述的系统,其中为了通过所述卷积神经网络处理所述音频序列以生成所述音频序列的所述向量表示,所述处理设备还执行包括以下的操作:
19.根据权利要求17所述的系统,其中为了使用所述音调数据和所述音频序列的所述经编码的向量表示来重建所述音频序列,所述处理设备还执行包括以下的操作:
20.根据权利要求17所述的系统,其中为了生成表示所述音频序列内的所述检测到的音调的所述音调数据,所述处理设备还执行包括以下的操作:
技术总结本公开涉及使用神经网络的语音音频压缩。实施例被公开以用于训练音频处理系统以使用神经网络来执行高质量语音音频编码和解码。特别地,在一个或多个实施例中,所公开的系统和方法包括:接收音频序列,音频序列包括语音音频,生成表示音频序列内的检测到的音调的音调数据,将音频序列传递通过音频编码器以生成音频序列的向量表示,由向量量化器使用音频序列的向量表示和离散向量码本来生成音频序列的经编码的向量表示,以及由音频解码器使用音调数据和音频序列的经编码的向量表示来重建音频序列。技术研发人员:T·博罗斯,S·D·杜米特雷斯库,A·科塔埃,J·戴维森,A·C·卡利斯特鲁,I·D·巴尔布受保护的技术使用者:奥多比公司技术研发日:技术公布日:2024/8/5本文地址:https://www.jishuxx.com/zhuanli/20240808/270545.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表