泛文本信息分块方法、装置、电子设备及存储介质与流程
- 国知局
- 2024-08-30 15:06:39
本发明涉及自然语言处理,尤其涉及一种泛文本信息分块方法、装置、电子设备及存储介质。
背景技术:
1、在基于检索增强生成(retrieval augmented generation,rag)的大模型优化实践中,要对用户拥有的知识文本文档进行解析和特征工程的处理。用户的原始知识库格式各种各样,其中文本通常需要经过仔细的清洗与处理,才适合传入向量检索库中用于检索。考虑到大模型输入有长度限制,同时为切分提取出关键信息,需要将清洗后的文本切分为较短的块(chunk),再进行后续的嵌入(embedding)向量生成,最终将多个文本块表示为对应的多个一定长度的向量。
2、目前,常用的文本分块方案主要包括:1)按字符数分割:根据设定分块的字符长度进行分割,但是由于语义理解不足导致分块不够准确;2)按段落分割:结合文档的层次分级结构进行分割,对文档解析的能力要求较高,通常需要借助光学字符识别(opticalcharacter recognition,ocr)的能力实现,分块速度慢;3)按语义分割:需要结合模型能力对文档内容加以理解,并按语义进行分割和拼接,分块速度慢。
技术实现思路
1、本发明提供一种泛文本信息分块方法、装置、电子设备及存储介质,用以实现更加准确和快速的文本分块效果。
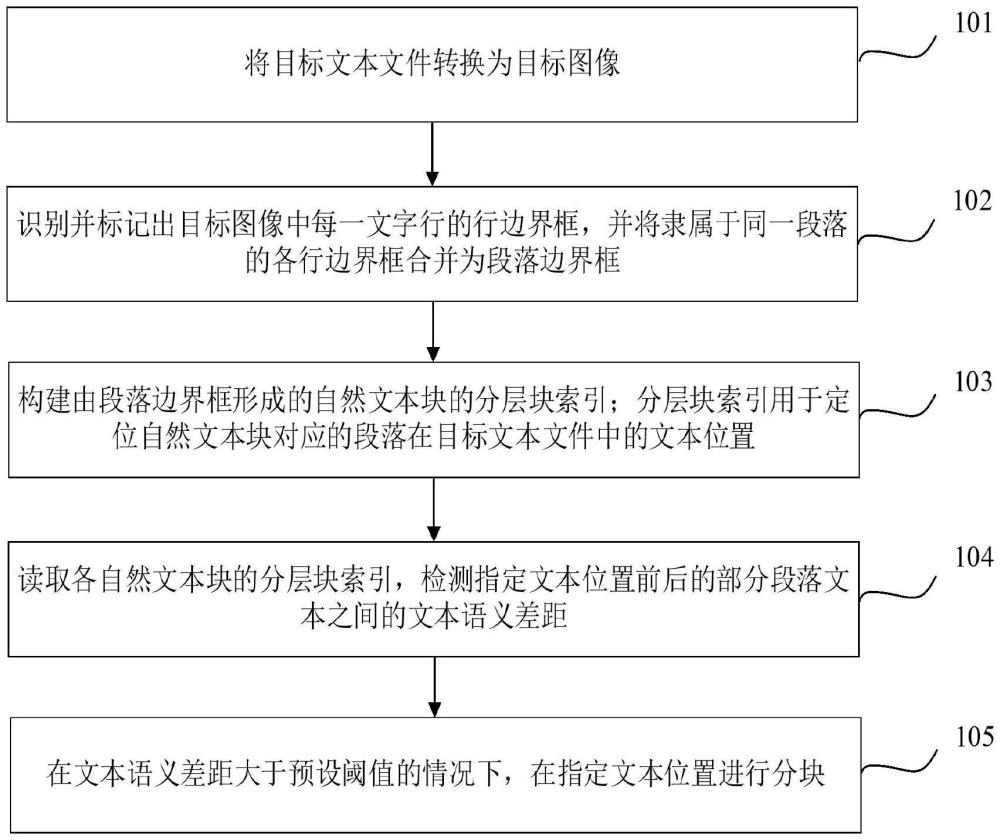
2、本发明提供一种泛文本信息分块方法,包括:
3、将目标文本文件转换为目标图像;
4、识别并标记出所述目标图像中每一文字行的行边界框,并将隶属于同一段落的各所述行边界框合并为段落边界框;
5、构建由所述段落边界框形成的自然文本块的分层块索引;所述分层块索引用于定位所述自然文本块对应的段落在所述目标文本文件中的文本位置;
6、读取各所述自然文本块的分层块索引,检测指定文本位置前后的部分段落文本之间的文本语义差距;
7、在所述文本语义差距大于预设阈值的情况下,在所述指定文本位置进行分块。
8、根据本发明提供的一种泛文本信息分块方法,所述构建由所述段落边界框形成的自然文本块的分层块索引,包括:
9、标记各所述自然文本块的编号、起止行号和级别;其中,若所述自然文本块的类别为标题,则标记所述自然文本块的级别为对应的标题级别,否则标记所述自然文本块的级别为默认值;统计各所述自然文本块的末尾行的字符数;
10、按顺序输出各所述自然文本块的编号、起止行号、级别和末尾行的字符数,作为各所述自然文本块的分层块索引。
11、根据本发明提供的一种泛文本信息分块方法,所述读取各所述自然文本块的分层块索引,检测指定文本位置前后的部分段落文本之间的文本语义差距,包括:
12、在识别出标题的情况下,读取各所述自然文本块的分层块索引,以定位不同级别的标题和所述标题覆盖的段落;
13、针对每个最高级别的标题,确定所述最高级别的标题覆盖的字数是否小于或等于第一预设字数;
14、在所述最高级别的标题覆盖的字数小于或等于所述第一预设字数的情况下,将所述最高级别的标题覆盖的最后一个段落的末尾位置确定为所述指定文本位置;
15、在所述最高级别的标题覆盖的字数大于所述第一预设字数的情况下,确定下一级标题覆盖的字数是否小于或等于所述第一预设字数;
16、在所述下一级标题覆盖的字数小于或等于所述第一预设字数的情况下,将所述下一级标题覆盖的最后一个段落的末尾位置确定为所述指定文本位置;
17、检测所述指定文本位置对应的当前标题覆盖的最后一个段落的末尾预设长度的文本与所述当前标题的下一标题覆盖的第一个段落的起始预设长度的文本之间的所述文本语义差距。
18、根据本发明提供的一种泛文本信息分块方法,所述读取各所述自然文本块的分层块索引,检测指定文本位置前后的部分段落文本之间的文本语义差距,包括:
19、在未识别出标题的情况下,读取各所述自然文本块的分层块索引,以定位各个段落;
20、针对每个段落,将所述段落的末尾位置确定为所述指定文本位置;
21、检测所述指定文本位置前的所述段落的末尾预设长度的文本与所述段落的起始预设长度的文本之间的所述文本语义差距。
22、根据本发明提供的一种泛文本信息分块方法,还包括:
23、在连续多个段落的字数均小于第二预设字数的情况下,将距离单位分块字数最近的段落的末尾位置确定为所述指定文本位置。
24、根据本发明提供的一种泛文本信息分块方法,还包括:
25、在目标段落的字数大于第三预设字数的情况下,按照单位分块字数在所述目标段落中确定至少一个所述指定文本位置;
26、在所述指定文本位置对所述目标段落进行分块,并在每个当前块的开头添加所述当前块的父级块和邻接块的信息。
27、根据本发明提供的一种泛文本信息分块方法,所述将隶属于同一段落的各所述行边界框合并为段落边界框,包括:
28、对各所述行边界框进行聚类分析,得到多个聚类簇;
29、将每个所述聚类簇中的隶属于同一段落的各所述行边界框合并为所述段落边界框。
30、根据本发明提供的一种泛文本信息分块方法,所述对各所述行边界框进行聚类分析,得到多个聚类簇,包括:
31、获取各所述行边界框的高度和各所述行边界框之间的距离;
32、在多个所述行边界框的高度位于段落中文字行高度范围内、且距离相近的情况下,确定多个所述行边界框隶属于同一段落;
33、将隶属于同一段落的多个所述行边界框聚合为一个所述聚类簇。
34、根据本发明提供的一种泛文本信息分块方法,所述将目标文本文件转换为目标图像,包括:
35、将所述目标文本文件转换为长图片;
36、对所述长图片进行灰度化操作,得到灰度图像;
37、对所述灰度图像进行二值化操作,得到所述目标图像。
38、本发明还提供一种泛文本信息分块装置,包括:
39、转换模块,用于将目标文本文件转换为目标图像;
40、合并模块,用于识别并标记出所述目标图像中每一文字行的行边界框,并将隶属于同一段落的各所述行边界框合并为段落边界框;
41、构建模块,用于构建由所述段落边界框形成的自然文本块的分层块索引;所述分层块索引用于定位所述自然文本块对应的段落在所述目标文本文件中的文本位置;
42、检测模块,用于读取各所述自然文本块的分层块索引,检测指定文本位置前后的部分段落文本之间的文本语义差距;
43、分块模块,用于在所述文本语义差距大于预设阈值的情况下,在所述指定文本位置进行分块。
44、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述的泛文本信息分块方法。
45、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述的泛文本信息分块方法。
46、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述的泛文本信息分块方法。
47、本发明提供的泛文本信息分块方法、装置、电子设备及存储介质,首先,将目标文本文件转换为目标图像;而后,识别并标记出目标图像中每一文字行的行边界框,并将隶属于同一段落的各行边界框合并为段落边界框;也即,通过抛弃语义信息和忽略光学文本识别过程,大幅缩减处理过程的耗时;接着,构建由段落边界框形成的自然文本块的分层块索引,可以通过分层块索引快速定位自然文本块对应的段落在目标文本文件中的文本位置;然后,读取各自然文本块的分层块索引,检测指定文本位置前后的部分段落文本之间的文本语义差距,可以在检测时跳过指定文本位置前后的其他段落文本,可以提升检测速度;最后,在文本语义差距大于预设阈值的情况下,在指定文本位置进行分块,可以提升分块的准确性。因此,本发明可以实现更加准确和快速的文本分块效果。
本文地址:https://www.jishuxx.com/zhuanli/20240830/285529.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表