基于深度强化学习的安全电力调度方法与流程
- 国知局
- 2024-11-06 15:06:12
本发明属于电力调度领域,具体涉及基于深度强化学习的安全电力调度方法。
背景技术:
1、电力调度是一种有效的管理手段,旨在确保电网的安全稳定运行、可靠供电以及各类电力生产工作的有序进行。电力调度的具体工作内容包括依据各类信息采集设备反馈回来的数据信息,或监控人员提供的信息,结合电网实际运行参数(如电压、电流、频率、负荷等),综合考虑各项生产工作的开展情况,对电网的安全和经济运行状态进行判断。调度中心通过电话或自动系统发布操作指令,指挥现场操作人员或自动控制系统进行调整,例如调整发电机出力、负荷分布以及投切电容器、电抗器等,从而确保电网持续安全稳定运行。
2、新能源的快速发展和峰值负荷的持续增长,给发电侧调度能力带来了新的挑战。新能源指的是风电和光伏等可再生能源,可以通过自然的能力获得,具有间歇性和随机性的特点。不是每一个区域都具备建风电厂或者光伏厂的能力,所以需要做电网的快速大范围的互联。随着各种各样的柔性设备或者电子设备的增加,整个电力系统的调控规模变得更大,并且不确定性和波动性也加剧了。电网调度中需要满足每一个时刻的瞬时安全约束。一旦某一个约束不满足,可能整个电网就会崩溃,造成大范围的断电,带来巨大的经济损失。因此整个电力系统需要具有高效和鲁棒的调度能力。
3、近年来,深度强化学习(deep reinforcement learning)算法已被广泛用于电力调度领域,通过深度强化学习来进行电力调度是一项具有极大应用价值和前景的研究方向。强化学习已应用于涉及虚拟电厂的经济调度问题,便于对虚拟电厂的调度指令进行快速分解。该技术也可应用于风电场和储能系统的自调度,实现更快的调度决策。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的基于深度强化学习的安全电力调度方法解决了现有电力调度方法的效率性和鲁棒性较差的问题。
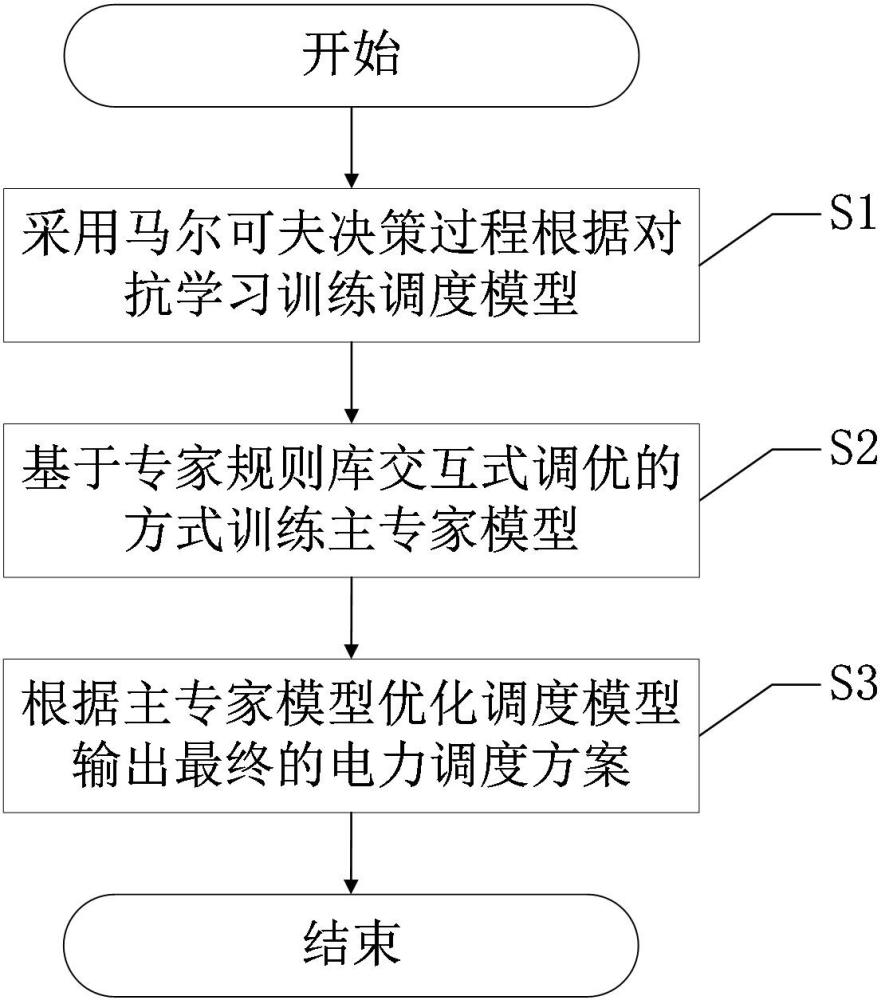
2、为了达到上述发明目的,本发明采用的技术方案为:基于深度强化学习的安全电力调度方法,包括以下步骤:
3、s1、采用马尔可夫决策过程根据对抗学习训练调度模型;
4、s2、基于专家规则库交互式调优的方式训练主专家模型;
5、s3、根据主专家模型优化调度模型输出最终的电力调度方案。
6、进一步地:所述s1具体为:
7、通过马尔可夫决策过程定义动作空间、状态空间和奖励函数,模拟调度模型和对抗模型在虚拟仿真电网环境中的行为,通过rainbow dqn 算法更新调度模型和对抗模型的网络参数,对调度模型进行对抗学习训练;
8、其中,马尔可夫决策过程定义的策略具体为:基于在虚拟仿真电网环境中的观测数据,通过调度模型或对抗模型生成电力调度方案;
9、马尔可夫决策过程定义的观察空间包括节点的电压值、线路的电流值、发电机的输出功率和负荷的电力需求的电网信息,状态空间的表达式具体为:
10、
11、式中,表示所有节点的电压值,表示所有线路的电流值,表示所有发电机的输出功率,表示所有负荷的电力需求;
12、马尔可夫决策过程定义的动作空间包括所有电力调度动作的排列组合,动作空间的表达式具体为:
13、
14、式中,表示发电机输出功率的调整值,表示开关操作状态,表示负荷调整;
15、马尔可夫决策过程定义的奖励函数具体为基于电网运行的目标,其包括供电可靠性、经济效益和鲁棒性,奖励函数rt的表达式具体为:
16、
17、
18、
19、
20、
21、式中,表示供电可靠性,用于衡量电压稳定性、频率偏差,表示第i个节点的电压,表示电网中各节点的额定电压,n表示电网中节点的总数,表示第j条线路的电流,表示第j条线路的最大允许电流,m表示电网中线路的总数,表示经济效益,用于衡量发电成本,为第 k台发电机的成本系数,g表示发电机总数,表示第k台发电机输出功率的调整值,表示环境效益,用于衡量污染物排放,为第k台发电机的排放系数,表示鲁棒性,用于衡量对故障的抵抗能力,为第l个故障的影响评估值,f表示故障的总数,表示第一指标权重,表示第二指标权重,表示第三指标权重,表示第四指标权重。
22、进一步地:通过rainbow dqn 算法更新调度模型和对抗模型的网络参数的表达式具体为:
23、
24、式中, 为在具有原子的向量上的投影,表示离散支持上的原子数量,为目标分布,为kl散度,为时间差误差的概率,为调节对的影响程度的控制参数。
25、进一步地:所述s1中,马尔可夫决策过程的安全成本根据状态设置;
26、安全成本的表达式具体为:
27、
28、
29、
30、
31、式中,表示第一权重系数,表示第二权重系数,表示第三权重系数,表示电压安全成本,用于反映电压偏离额定值的程度,表示允许的电压偏差范围,表示电流安全成本,用于反映线路电流是否超过安全运行的限制,表示频率安全成本,用于衡量电网的频率偏差情况,表示当前电网频率,表示电网的额定频率,表示允许的频率偏差范围,表示最大值函数。
32、上述进一步方案的有益效果为:通过rainbow dqn 算法根据电力系统的特性,采用对抗学习和专家规则库交互式调优的方式训练调度模型,进一步提升电力调度方案的优化效果。
33、进一步地:对调度模型进行对抗学习训练的目标函数具体为下式:
34、
35、式中,表示当前状态,表示调度模型的动作,表示扰动,表示执行调度和扰动后,系统转移到的状态,表示调度模型的策略,表示对抗模型的策略,和均通过状态空间获取,通过动作空间获取;
36、表示对抗模型尝试寻找最不利的扰动,表示调度模型学习如何在对抗模型生成的最不利情景下调整调度策略,表示所有可能状态转移的平均情况。
37、进一步地:所述s2包括以下分步骤:
38、s21、设置主专家模型和从专家模型,主专家模型包括电力调度的基本知识和初步优化能力,从专家模型根据主专家模型的副本生成;
39、s22、初始化主专家模型和从专家模型;
40、s23、通过专家规则库优化从专家模型的输出,进而训练主专家模型。
41、上述进一步方案的有益效果为:本发明采用基于电力专家构建的专家规则库交互式调优的方式训练主专家模型,每个从专家模型对应一个电力专家,主专家模型用于统一更新和管理,进一步提升电力调度方案的优化效果。
42、进一步地:所述s23包括以下分步骤:
43、s231、通过调度模型输出初始电力调度方案,将初始电力调度方案输入从专家模型,得到调整后的电力调度方案;
44、s232、通过专家规则库对调整后的电力调度方案进行故障业务分析,生成调整后的电力调度方案的反馈结果;
45、s233、通过虚拟仿真电网环境将反馈结果发送至从专家模型,根据反馈结果更新从专家模型的模型参数;
46、s234、按照预设周期将从专家模型更新的模型参数反馈至主专家模型,对主专家模型进行训练。
47、上述进一步方案的有益效果为:使用专家规则库交互式调优调整主专家模型,使其更符合电力专家的专业判断。使用环境反馈调整从专家模型,使其更符合电网运行的实际情况。定期将从专家模型的更新反馈到主专家模型,确保主专家模型能够逐渐吸收各个电力专家的知识和经验。
48、进一步地:所述s234中,对主专家模型进行训练的损失函数loss的表达式具体为:
49、
50、式中,为专家规则库对第i调整后的电力调度方案的专家确信度评分,为从专家模型对第i调整后的电力调度方案的预测评分,n为调度方案的数量。
51、进一步地:所述s3包括以下分步骤:
52、s31、将虚拟仿真电网环境中的观测值输入调度模型,生成电力调度方案,其中,观测值包括节点电压、线路电流、发电机输出功率和负荷需求;
53、s32、将电力调度方案发送至主专家模型,生成优化后的电力调度方案;
54、s33、通过专家规则库对优化后的电力调度方案进行故障业务分析,生成优化后的电力调度方案的反馈结果;
55、s34、根据优化后的电力调度方案的反馈结果判断优化后的电力调度方案是否合格,若是,则将优化后的电力调度方案作为最终的电力调度方案;若否,则根据优化后的电力调度方案的反馈结果优化主专家模型,返回s32。
56、本发明的有益效果为:
57、(1)本发明提供了基于深度强化学习的安全电力调度方法,通过对电力调度相关知识的学习,并且结合深度强化学习的特点和缺点,以有效地应对电力调度中的各种安全问题,本发明基于 rainbow dqn 算法,提出了两种新颖的训练方式,分别是以基于对抗学习的方式训练对抗模型和调度模型来进行安全约束保障学习,以基于专家规则库交互式调优的方式训练得到主专家模型。本发明提出了一种基于深度强化学习的安全电力调度算法,马尔可夫决策过程的安全成本将电压安全成本、电流安全成本、频率安全成本考虑在内,提升了电网运行的安全性,理论分析表明该方法在安全性和调度性能方面具有潜在优势。
58、(2)本发明的目的在于基于电力调度中的各种安全标准与规则,结合电网系统的特点,将问题拓展为电力安全调度,包括负荷管理、故障检测与隔离、应急预案等,最后建立一个基于深度强化学习的安全电力调度算法。用于在用电高峰期通过需求响应、负荷转移和削峰填谷等措施,平衡供需,减少高峰负荷对系统的压力;还用于快速检测并隔离故障区域,防止故障扩展,减少对电力系统的影响;还用于制定应急预案,确保在突发事件发生时能够快速响应和恢复供电。
本文地址:https://www.jishuxx.com/zhuanli/20241106/325314.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。