视频编码和解码中改进的片地址信令的制作方法
- 国知局
- 2024-11-18 18:15:29
公开的是与视频编码和解码相关的实施例。
背景技术:
1、高效视频编码(high efficiencyvideo coding)(hevc)是由itu-t和mpeg标准化的基于块的视频编解码器,它利用时间和空间预测两者。在编码器中,原始像素数据和预测像素数据之间的差异(称为残差(residual))被变换到频域,进行量化,然后进行熵编码(entropy-code),之后与必要的预测参数(诸如预测模式和运动向量)一起传送(这些预测参数也是熵编码的)。通过量化变换的残差,可以控制位率和视频质量之间的折衷。解码器执行熵解码、逆量化和逆变换,以获得残差;并且然后将残差加到帧内或帧间预测以重构图象(picture)。
2、mpeg和itu-t正在联合视频探索小组(jvet)内研究hevc的后继者。开发中的这个视频编解码器的名称是通用视频编码(vvc)。
3、vvc视频编码标准草案(draft vvc video coding standard)使用称为四叉树加二叉树加三叉树块结构(qtbt+tt)的块结构,其中每个图象首先被分区成称为编码树单元(ctu)的正方形块。所有ctu的大小都是相等的,并且分区是在没有任何语法(syntax)控制它的情况下完成的。每个ctu被进一步分区成能具有正方形或矩形形状的编码单元(cu)。ctu首先由四叉树结构分区;然后,它可以进一步以二进制结构用相等大小的分区(或者垂直或者水平)来分区,以形成cu。从而,块可能具有正方形或矩形形状。四叉树和二叉树的深度能由编码器在位流(bitstream)中设置。图1中图示了使用qtbt划分ctu的示例。该结构的三叉树(tt)部分增加了将cu划分为三个分区而不是两个大小相等的分区的可能性;这增加了使用更好地适合图象中内容结构的块结构的可能性。
4、vvc视频编码标准草案包括名为“片(tile)”的工具,该工具将图象划分成矩形的空间独立的区域。vvc编码标准草案中的片非常类似于在hevc中使用的片。使用片,能将vvc中的图象分区成样本的行和列,其中片是行和列的交集。图2示出了使用4个片行和5个片列的片分区的示例,导致图象总共有20个片。
5、通过指定行的厚度和列的宽度,在图象参数集(pps)中发信号通知(signal)片结构。各个行和列能具有不同的大小,但是分区总是跨越整个图象,分别从左到右和从上到下。
6、表1中列出了vvc标准草案中用于指定片结构的pps语法。首先,存在指示是否使用片的标志single_tile_in_pic_flag。如果标志被设置为0,则指定片列和行的数量。uniform_tile_spacing_flag是指定是否显式地发信号通知列宽和行高或者是否应使用预先定义的方法来均匀隔开片边界的标志。如果指示了显式地发信号通知,则按顺序发信号通知列宽,继之以行高。最后,loop_filter_cross_tiles_enabled_flag指定对于图象中的所有片边界是打开还是关闭跨片边界的环内滤波器(in-loop filter)。片语法还包括原始字节序列有效载荷(rbsp)尾随位。
7、表1-vvc标准草案中的片语法
8、
9、同一张图象的片之间没有解码依赖性。这包括帧内预测、对于熵编码的上下文选择和运动向量预测。一个例外是,在片之间通常允许环内滤波依赖性。
10、vvc中的编码图象的位被分区成tile_group_layer_rbsp()数据组块(datachunk),其中每个这样的组块都被封装到其自己的组网络抽象层(nal)单元中。数据组块由片组报头和片组数据组成,其中片组数据由整数个编码的完整片组成。表2示出了相关的vvc规范标准草案语法。下面进一步描述tile_group_header()和tile_group()数据语法。
11、表2-vvc标准草案中的片组层
12、
13、片组报头以tile_group_pic_parameter_set_id语法元素开始。该元素指定应该被激活并用于解码片组的图象参数集(pps)(见表1)。片组地址码字指定片组中第一片的片地址。地址被表示为0和n-1之间的数字,其中n是图象中的片的数量。使用图2作为示例,存在的片的数量等于20,因此该图象的有效片组地址值在0和19之间。片地址以光栅扫描次序(raster scan order)指定片,并被示出在图2的底部。解码器解码该地址值,并通过使用从活动pps解码的片结构信息,解码器能导出图象中第一片的空间坐标。例如,如果我们假设图2中的片全都具有256×256亮度样本(luma sample)的相同大小,则片地址8意味着片组中第一片的y坐标为int(8/5)*256=1*256=256,而x坐标为(8%5)*256=3*256=768亮度样本。
14、片组报头中的下一个码字num_tiles_in_tile_group_minus1指定片组中存在的片的数量。如果片组中存在多于一个片,则发信号通知除第一个之外的片的入口点(entrypoint)。首先,存在码字offset_len_minus1,它指定用于发信号通知偏移中的每个偏移的位数。然后,存在入口点偏移码字entry_point_offset_minus1的列表。这些指定了位流中的字节偏移,这些字节能由解码器用来找到每个片的起始点,以便并行解码它们。没有这些偏移,解码器将不得不解析片数据,以便找出每个片在位流中开始的地方。片组中的第一片紧跟在片组报头之后,因此没有针对该片发送的字节偏移。这意味着偏移的数量比片组中的片的数量少一。
15、表3-vvc标准草案中的片组报头
16、
17、片组数据包含片组中的所有ctu。首先,在片组中的所有片上都有for循环。在该循环内部,在片组中的所有ctu上都有for循环。注意,不同片中的ctu的数量可能不同,因为片行高和片列宽不必须相等。出于熵编码原因,在每个片的末尾都有一位设置为1。每个片以字节对齐结束,这意味着用于片组中每个片的数据都从位流中的偶数字节地址开始。这对于以字节数指定入口点是必要的。注意,片组报头也以字节对齐结束。
18、表4-vvc标准草案中的片组数据
19、
20、片的报头开销由信令、地址、片组中的片的数量、字节对齐以及每个片的入口点偏移组成。在vvc标准草案中,当启用片时,片组报头中包括入口点偏移是强制的。
21、入口点偏移还简化了片组或片的提取和拼接(stitching),以将它们重构为输出流。这要求一些编码器侧约束,以使片组或片在时间上独立。编码器约束之一是需要限制运动向量,使得对于片组或片的运动补偿仅使用包括在先前图象的空间上共置区域中的样本。另一个约束是要限制时间运动向量预测(tmvp),使得该过程在时间上独立于不共置的区域。为了完全独立,还要求禁用片组或片之间的环内滤波。
22、片有时被用于提取和拼接360度视频,该视频旨在用于使用头戴式显示器(hmd)装置的消费。使用现今的hmd装置时,视野被限制在整个球体的20%左右,这意味着用户仅消费整个360度视频的20%。通常,使整个360度视频球体对hmd装置可用,并且装置然后裁剪出(crop out)为用户呈递(render)的那部分。那部分,即用户看到的球体的那部分,被称为视口(viewport)。众所周知的资源优化是要使hmd装置视频系统意识到头部移动和用户正在看的方向,使得在处理没有向用户呈递的视频样本上花费更少的资源。这里的资源可以是从服务器到客户端的带宽,或者是装置的解码能力。对于具有大于当前技术水平的视野的未来hmd装置,非均匀的资源分配将仍然是有益的,因为人类视觉系统需要在中央视觉区域(大约18°水平视图)中更高的图像质量,而对外围区域(对于舒适的水平视图大约为120°或更高)中图像质量它提出了较低要求。
23、优化感兴趣区域(roi)的资源是片的另一个用例。roi能在内容中指定,或者通过诸如眼睛跟踪的方法提取。
24、使用头部移动来减少所需资源量的一种最先进的方法是要使用片。这能通过首先对视频序列进行多次编码来完成,其中在所有编码中片分区结构是相同的。编码以不同的视频质量完成,这导致至少一个高质量编码和一个低质量编码。这意味着对于在特定时间点的每个片位置,存在至少一个高质量片表示和至少一个低质量片表示。高质量片和低质量片之间的差异可以是:与低质量片相比,高质量片以更高的位率编码;或者与低质量片相比,高质量片具有更高的分辨率。
25、图3示出了将视频编码成具有高质量片的一个流302和具有低质量片的另一个流304的示例。这里我们假设每个片都放在其自己的片组中。片在vvc草案中以光栅扫描次序编号,这里使用白色文本示出所述光栅扫描次序。这些片编号被用作片组地址。根据用户正在看的地方,客户端请求不同质量的片,使得对应于用户正在看的地方的片以高质量接收,而用户不在看的地方的片以低质量接收。然后,客户端在位流域中将片拼接在一起,并将输出位流馈送到视频解码器。例如,图3示出了拼接之后的输出流306,其中片列310和316(两个外部列)由来自低质量流304的片组成;并且其中片列3123和316(两个内部列)由来自高质量流302的片组成。注意,输出图象的宽度小于输入。原因是,我们在这里假设,对于用户正在看的地方后面的区域,根本没有请求任何片。
技术实现思路
1、重要的是进行拼接,使得输出位流符合位流规范(诸如未来公布的vvc规范),以便能使用没有任何修改的任何符合标准的解码器来解码输出流。为了使图3中所示的拼接示例符合vvc规范草案,片组地址(片组报头中的tile_group_address码字)需要由拼接器来更新。例如,输出图象中右下方片组的片组地址必须设置为等于15,而输入低质量流和高质量流中该片的片组地址等于19。
2、提供了改进编码和解码视频(例如改进片拼接在一起)的实施例。本公开还引入了术语段组(segment group)、段和单元。如这里所使用的,术语段是比片(在vvc草案中使用的)更通用的术语,并且注意到实施例可应用于不同种类的图象分区方案,并且不仅仅是从hevc和vvc草案已知的片分区。如这里所使用的,来自这些草案的“片”是段的一个示例,但是也可以有段的其它示例。
3、如图4中所示,视频流的单个图象402以各种方式被分区。例如,图象402被分区成单元410、段412和段组414。如图所示,图象402包括64个单元410(图4的顶部)、16个段412(图4的中部)和8个段组414(图4的底部)。如图所示,图象402的分区结构413(由虚线示出)定义了段412。每个段412包括多个单元410。段412可以包括整数个完整单元或者完整和部分单元的组合。多个段412形成段组414。段组可以包括按光栅扫描次序的段。备选地,段组可以包括一起形成矩形的段的任何组。备选地,段组可以由段的任何子集组成。
4、如图5中所示,图象402可以由分区结构(以虚线示出)分区成多个段;这里,示出有四个段,包括段502和504。图5还示出了三个单元510、512和514;这些单元中的两个(512和514)属于当前段504,而单元中的一个(510)属于不同的相邻段502。段相对于其它段是独立的,这意味着在对单元进行解码时,段边界类似于图象边界被处置。这在解码期间影响元素的导出过程,诸如例如,帧内预测模式的导出和量化参数值的导出。
5、帧内预测模式在当前技术中是众所周知的,并且仅针对将来自当前图象的先前解码样本的预测用于样本预测的单元发信号通知和使用帧内预测模式。常见的是,当前单元512中的帧内预测模式的导出取决于其它相邻单元514中先前导出的帧内预测模式。在段是独立的情况下,当前单元512中的帧内预测模式的导出可以仅依赖于属于当前段504的单元514中先前导出的帧内预测模式,并且可以不依赖于属于不同段502的任何单元510中的任何帧内预测模式。
6、这意味着图5中的分区结构使得不同段502中的单元510中的帧内预测模式不可用于导出当前段504中的单元512的帧内预测模式。因而,对于当前段504中的单元512,段边界对帧内预测模式导出的影响可以与图象边界相同。注意,不同段502中的一些单元510中的模式很可能已经被用于导出当前段504中的单元512中的帧内预测模式,如果那些单元本属于同一段的话。
7、如这里所使用的,段可能(在某些情况下)等同于片或切片(slice),并且因此这些术语可以互换使用。同样,段组可以(在某些情况下)等同于片组,而单元可以(在某些情况下)等同于ctu。
8、如上面所解释的,过程可能期望将一个或多个位流作为输入,并通过从一个或多个输入位流中选择片来产生输出位流;这种过程可以称为拼接过程。现有视频编码和解码解决方案的一个问题是,可能要求通过拼接过程来修改片组层的数据,以便产生符合位流规范(诸如未来公布的vvc规范)的输出位流。这使得拼接在计算上非常复杂,因为每秒必须重写的分组的数量可能变得非常高。例如,考虑60帧每秒(fps)的帧速率,其中每个图象包括16个片组。如果每个片都放在其自己的分组中,那么可能需要重写960(=60*16)个分组每秒。
9、现有视频编码和解码解决方案的另一个问题是,在不修改位流的片组层部分的情况下提取、拼接和/或重定位位流中的片是不可能的。
10、实施例通过用片组报头中的索引值替换当前片地址信令并通过输送这种索引值与片地址之间的映射来克服这些和其它问题。例如,这种映射可以在诸如pps的参数集中输送。如果在编码期间是考虑到拼接而设置了索引值,则索引值能在拼接期间保持原样(例如,当对诸如不同质量的版本进行编码时,编码器可以强制执行以下条件:索引值跨不同版本是唯一的)。然后,能通过仅修改索引值于参数集中片地址的映射来完成片组地址的改变。
11、为了便于提取、拼接和/或重定位位流中的片而不修改位流的片组层部分,实施例提供了参数集中的片组中片的数量和索引值之间的映射,其中在片组报头中发送索引。
12、实施例的优点包括允许仅通过重写参数集来执行拼接,而片组报头保持原样。如果我们采用上面的60fps示例,并且假设参数集在位流中作为分组每秒发送一次,那么实施例将要求每秒至多重写1个分组,而不是每秒961个分组。因此,拼接的计算复杂度显著降低。
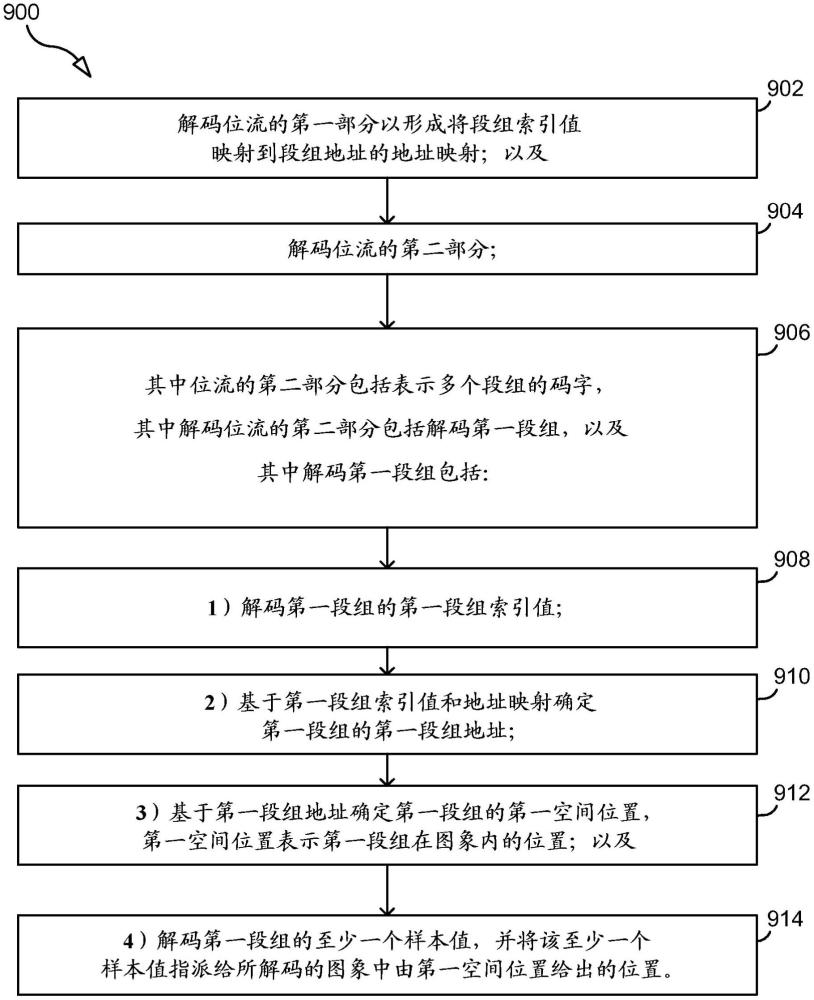
13、根据第一方面,提供了一种用于从位流解码图象的方法,该图象被分区成多个段组。该方法包括:解码位流的第一部分以形成将段组索引值映射到段组地址的地址映射;以及解码位流的第二部分。位流的第二部分包括表示多个段组的码字。解码位流的第二部分包括解码第一段组。解码第一段组包括:1)解码第一段组的第一段组索引值;2)基于第一段组索引值和地址映射确定第一段组的第一段组地址;3)基于第一段组地址确定第一段组的第一空间位置,第一空间位置表示第一段组在图象内的位置;以及4)解码第一段组的至少一个样本值,并将该至少一个样本值指派给所解码的图象中由第一空间位置给出的位置。
14、在一些实施例中,地址映射包括阵列和/或列表、阵列和/或列表的并行集合、散列图(hash map)和关联阵列(associative array)中的一个或多个。在实施例中,解码位流的第一部分以形成地址映射包括:从位流解码指示列表值的数量的第一值;以及通过从位流解码多个列表值来形成列表,列表值的数量等于第一值。在实施例中,基于第一段组索引值和地址映射来确定第一段组的第一段组地址包括使用第一段组索引值来执行查找操作。
15、在一些实施例中,解码位流的第一部分以形成地址映射包括:从位流解码指示列表值的数量的第一值;以及通过从位流解码表示键-值对(key-value pair)k和v的多个值来形成第一列表(key)和第二列表(value),键-值对的数量等于第一值。第一列表包括键k,并且第二列表包括键-值对的值v,并且第一列表和第二列表的排序使得对于给定的键-值对,第一列表中给定键k的索引对应于第二列表中给定值v的索引。在实施例中,解码位流的第一部分以形成地址映射包括:从位流解码指示散列值的数量的第一值;以及通过从位流解码表示键-值对k和v的多个值来形成散列图,键-值对的数量等于第一值,其中对于给定的键-值对,给定键k的索引由散列图映射到给定值v。
16、在一些实施例中,基于第一段组索引值和地址映射确定第一段组的第一段组地址包括:确定索引(i),使得对应于第一列表中的索引的值(key[i])与第一段组索引值匹配;以及将第一段组地址确定为对应于第二列表中的索引的值(value[i])。
17、中的在一些实施例中,基于第一段组索引值和地址映射来确定第一段组的第一段组地址包括使用第一段组索引值来执行散列查找操作。在一些实施例中,被解码的表示键-值对k和v的值包括表示键k的增量值,使得对于第一键-值对,键k由增量值确定,并且对于其它键-值对,键k通过将增量值与先前确定的键值相加以生成当前键k来确定。
18、在一些实施例中,段组对应于片组、子图象和/或切片。在一些实施例中,段组包括一个或多个段,并且在一些实施例中,段组仅包括一个段。
19、在实施例中,段组对应于片组。在一些实施例中,位流的第一部分被包括在参数集中,并且该方法进一步包括解码附加段组,其中地址映射被用于解码附加段组。在一些实施例中,位流的第一部分被包括在参数集中,并且该方法进一步包括解码附加图象,其中地址映射被用于解码附加图象。
20、根据第二方面,提供了一种用于从位流解码图象的方法,该图象被分区成多个段组。该方法包括:解码位流的第一部分以形成将段组索引值映射到针对第一段组要解码的段的数量的大小映射;以及解码位流的第二部分。位流的第二部分包括表示多个段组的码字。解码位流的第二部分包括解码第一段组。解码第一段组包括:1)解码第一段组的第一段组索引值;2)基于第一段组索引值和大小映射来确定第一段组的第一大小;以及3)解码多个段以形成所解码的图象,段的数量等于第一大小。
21、在一些实施例中,大小映射包括阵列和/或列表、阵列和/或列表的并行集合、散列图和关联阵列中的一个或多个。在实施例中,解码位流的第一部分以形成大小映射包括:从位流解码指示列表值的数量的第一值;以及通过从位流解码多个列表值来形成列表,列表值的数量等于第一值。在实施例中,基于第一段组索引值和大小映射来确定第一段组的第一大小包括使用第一段组索引值来执行查找操作。
22、在一些实施例中,段组对应于片组、子图象和/或切片。在一些实施例中,段组包括一个或多个段,并且在一些实施例中,段组仅包括一个段。
23、根据第三方面,提供了一种用于将图象编码成位流的方法,该图象被分区成多个段组。该方法包括针对多个段组,确定将段组索引值映射到段组地址的地址映射;编码位流的第一部分;以及编码位流的第二部分。编码位流的第一部分包括生成形成地址映射的码字,地址映射将段组索引值映射到段组地址。编码位流的第二部分包括生成表示多个段组的码字。编码位流的第二部分包括编码第一段组。编码第一段组包括:1)从第一段组的第一段组地址确定第一段组索引值,其中地址映射将第一段组索引值映射到第一段组地址;2)编码第一段组的第一段组索引值;以及3)编码第一段组的样本值。
24、根据第四方面,提供了一种用于将图象编码成位流的方法,该图象被分区成多个段组。该方法包括:确定将段组索引值映射到针对第一段组要编码的段的数量的大小映射;编码位流的第一部分;以及编码位流的第二部分。编码位流的第一部分包括生成形成大小映射的码字,所述大小映射将段组索引值映射到针对第一段组要编码的段的数量。编码位流的第二部分包括生成表示多个段组的码字。编码位流的第二部分包括编码第一段组。编码第一段组包括:1)确定第一段组的第一段组索引值,其中大小映射将第一段组的第一段组索引值映射到第一大小,所述第一大小是针对第一段组要编码的段的数量;2)编码第一段组的第一段组索引值;以及3)编码第一段组的多个段,段的数量等于第一大小。
25、在一些实施例中,编码第一段组索引值包括生成表示第一段组索引值的一个或多个码字。
26、根据第五方面,解码器适合于执行第一或第二方面的实施例中的任何一个。
27、根据第六方面,编码器适合于执行第三或第四方面的实施例中的任何一个。
28、在一些实施例中,编码器和解码器可以共置于同一节点中,或者它们可以彼此分离。在实施例中,编码器和/或解码器是网络节点的一部分;在实施例中,编码器和/或解码器是用户设备的一部分。
29、根据第七方面,提供了一种用于从位流解码图象的解码器,该图象被分区成多个段组。解码器包括解码单元和确定单元。解码单元被配置成解码位流的第一部分以形成将段组索引值映射到段组地址的地址映射;并且被进一步配置成解码位流的第二部分。位流的第二部分包括表示多个段组的码字。解码位流的第二部分包括解码第一段组。解码第一段组包括:1)(由解码单元)解码第一段组的第一段组索引值;2)基于第一段组索引值和地址映射(由确定单元)确定第一段组的第一段组地址;3)基于第一段组地址(由确定单元)确定第一段组的第一空间位置,第一空间位置表示第一段组在图象内的位置;以及4)(由解码单元)解码第一段组的至少一个样本值,并将该至少一个样本值指派给所解码的图象中由第一空间位置给出的位置。
30、根据第八方面,提供了一种用于从位流解码图象的解码器,该图象被分区成多个段组。解码器包括解码单元和确定单元。解码单元被配置成解码位流的第一部分以形成将段组索引值映射到针对第一段组要解码的段的数量的大小映射;并且被进一步配置成解码位流的第二部分。位流的第二部分包括表示多个段组的码字。解码位流的第二部分包括解码第一段组。解码第一段组包括:1)(由解码单元)解码第一段组的第一段组索引值;2)基于第一段组索引值和大小映射来(由确定单元)确定第一段组的第一大小;以及3)(由解码单元)解码多个段以形成所解码的图象,段的数量等于第一大小。
31、根据第九方面,提供了一种用于从位流编码图象的编码器,该图象被分区成多个段组。编码器包括编码单元和确定单元。确定单元被配置成针对多个段组,确定将段组索引值映射到段组地址的地址映射。编码单元被配置成编码位流的第一部分;并且被进一步配置成编码位流的第二部分。编码位流的第一部分包括生成形成地址映射的码字,地址映射将段组索引值映射到段组地址。编码位流的第二部分包括生成表示多个段组的码字。编码位流的第二部分包括编码第一段组。编码第一段组包括:1)从第一段组的第一段组地址(由确定单元)确定第一段组索引值,其中地址映射将第一段组索引值映射到第一段组地址;2)(由编码单元)编码第一段组的第一段组索引值;以及3)(由编码单元)编码第一段组的样本值。
32、根据第十方面,提供了一种用于将图象编码成位流的编码器,该图象被分区成多个段组。编码器包括编码单元和确定单元。确定单元被配置成确定将段组索引值映射到针对第一段组要编码的段的数量的大小映射。编码单元被配置成编码位流的第一部分;并且被进一步配置成编码位流的第二部分。编码位流的第一部分包括生成形成大小映射的码字,所述大小映射将段组索引值映射到针对第一段组要编码的段的数量。编码位流的第二部分包括生成表示多个段组的码字。编码位流的第二部分包括编码第一段组。编码第一段组包括:1)(由确定单元)确定第一段组的第一段组索引值,其中大小映射将第一段组的第一段组索引值映射到第一大小,所述第一大小是针对第一段组要编码的段的数量;2)(由编码单元)编码第一段组的第一段组索引值;以及3)(由编码单元)编码第一段组的多个段,段的数量等于第一大小。
33、根据第十一方面,提供了一种包括指令的计算机程序,所述指令当由节点的处理电路执行时,使得该节点执行第一、第二、第三和第四方面中任一方面的方法。
34、根据第十二方面,提供了包含第十一方面的任一实施例的计算机程序的载体,其中所述载体是电信号、光信号、无线电信号和计算机可读存储介质之一。
本文地址:https://www.jishuxx.com/zhuanli/20241118/327828.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表