一种基于大数据的软件缺陷类别预测方法
- 国知局
- 2024-11-21 11:35:47
本发明属于深度学习领域,特别涉及一种基于大数据的软件缺陷类别预测方法。
背景技术:
1、在工业自动化和智能化的发展背景下,软件在工业生产中扮演着重要角色。随着软件在现代生活和工作中的广泛应用,软件缺陷的及时识别和预测变得至关重要。软件的稳定运行直接影响着生产线的效率和安全性。因此,准确预测软件缺陷类别对于提高生产效率和减少生产中断至关重要。
2、传统的软件缺陷预测方法往往依赖于经验规则或简单统计方法,难以满足实际生产中对准确性和泛化能力的要求。
技术实现思路
1、为了提高软件质量和稳定性,且能够有效地预测软件缺陷类别,帮助开发人员及时发现和解决问题,本发明提出一种基于大数据的软件缺陷类别预测方法,具体包括以下步骤:
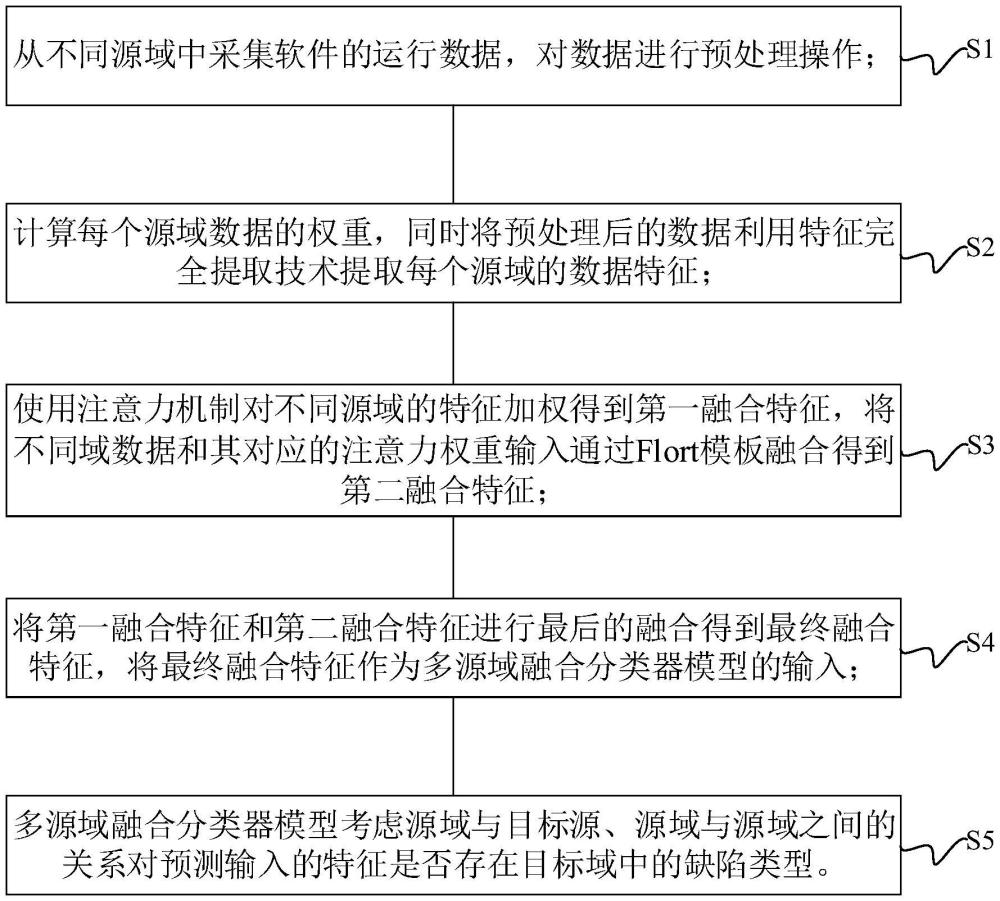
2、s1、从不同源域中采集软件的运行数据,对数据进行预处理操作;
3、s2、计算每个源域数据的权重,同时将预处理后的数据利用特征完全提取技术提取每个源域的数据特征;
4、s3、使用注意力机制对不同源域的特征加权得到第一融合特征,将不同域数据和其对应的注意力权重输入通过flort模板融合得到第二融合特征;
5、s4、将第一融合特征和第二融合特征进行最后的融合得到最终融合特征,将最终融合特征作为多源域融合分类器模型的输入;
6、s5、多源域融合分类器模型考虑源域与目标源、源域与源域之间的关系对预测输入的特征是否存在目标域中的缺陷类型。
7、进一步地,一个源域的权重计算包括:
8、
9、其中,wi为从源域i学习得到的权重参数,n为样本源域数量,m为一个源域中样本的数量,xis,j是源域i的第j个样本,yis,j是源域i的第j个样本的标签;fw(·)为网络参数为w的神经网络模型,用于将样本输入神经网络中预测该输入样本的缺陷标签;ls是源域损失函数,ld是域对抗损失函数,xt表示目标域t的样本,μ是损失函数的权重参数。
10、进一步地,利用特征完全提取技术提取每个源域的数据特征的过程包括:
11、
12、其中,表示利用特征完全提取技术提取得到的源域i的数据特征,σ是激活函数,m为一个源域中样本的数量;为一个源域中第j个数据特征的注意力权重,表示一个源域中第j个数据特征,为的向量表示;表示一个源域中第j个数据特征的注意力分数;w表示可学习的权重向量,wt表示w的转置;b1为偏置项。
13、进一步地,步骤s3具体包括以下步骤:
14、s31、构建不同源域的特征之间的相似度向量,计算特征之间的相关性;
15、s32、通过注意力机制对不同源域的特征进行加权,获得加权后的特征表征;
16、s33、将加权的特征表征送入flort模块进行特征融合,得到综合特征表征。
17、进一步地,通过注意力机制对不同源域的特征进行加权的过程包括:
18、si=(fis)ty
19、si′=wi×si
20、
21、其中,si表示源域i的数据特征fis与目标域中的标签y之间的相关性得分,在本发明中从划分的每个源域中获取该源域中缺陷类型的标签作为标签y;si′为利用从源域i学习得到的权重参数wi对si加权后的相关性得分;αi表示源域i中的数据特征注意力权重;n表示源域的个数;z表示注意力加权后的数据特征。
22、进一步地,将不同域数据和其对应的注意力权重输入通过flort模板融合得到第二融合特征的过程包括:
23、
24、其中,ffuesd为融合之后的综合特征表征;wi和bi为源域i对应的线性变换的权重和偏置项,σ为激活函数,tanh表示双曲正切函数.
25、进一步地,将第一融合特征和第二融合特征进行最后的融合得到最终融合特征的过程包括:
26、fcombined=tanh(wz×z+wf×ffused+b2)
27、其中,fcombined为融合得到最终融合特征;wz、wf为可学习的权重矩阵,分别用于将第一融合特征z、第二融合特征ffused映射到一个相同的特征空间中;b2为偏置项,用于调整最终融合特征的基线。
28、进一步地,多源域融合分类器模型进行分类的过程包括:
29、
30、其中,predicition(xt)表示预测目标域t上的输入特征xt的缺陷类别;σ是激活函数,用于将预测结果转化为概率分布函数;weightedattention(fis,fjs,y)表示经过源域i与目标域数据之间的注意力权重加权的源域i与源域j的数据特征相似度;fcombined表示融合得到最终融合特征;b3为多源域融合分类器模型中的偏置项。
31、进一步地,经过源域i与目标域数据之间的注意力权重加权的源域i与源域j的数据特征相似度weightedattention(fis,fjs,y)表示为:
32、weightedattention(fis,fjs,y)=attention(fis,y)×similarity(fis,fjs)
33、其中,similarity(fis,fjs)表示源域i中的数据特征fis与源域j中的数据特征fjs之间的相似度向量;attention(fis,y)表示i中的数据特征fis与目标域中数据特征y之间的注意力权重加权。
34、本发明针对软件缺陷类别预测问题提出了一种基于大数据和深度学习的创新方法,其核心在于通过对多源域收集到的不同数据和模型训练过程,实现对软件缺陷类别的准确预测;本发明首利用了cdann和ptr模块,这有助于从不同源域中提取数据特征,从而更好地捕获软件缺陷的关键特征。这种特征提取对于准确预测软件缺陷类别至关重要;接着,注意力机制进一步加权不同源域的特征,这有助于更好地捕获关键特征,从而提高了模型的预测性能;随后,多源域融合分类器模型的训练进一步加强了对目标域上缺陷类别的预测;最后,flort实时监控和动态调整分类器的阈值,这有助于保持模型的预测性能,并使其能够适应不断变化的环境。综上所述,本发明为识别软件类别缺陷提供了有益的效果,从而提高了预测的准确性和稳定性。
技术特征:1.一种基于大数据的软件缺陷类别预测方法,其特征在于,具体包括以下步骤:
2.根据权利要求1所述的一种基于大数据的软件缺陷类别预测方法,其特征在于,一个源域的权重计算包括:
3.根据权利要求1所述的一种基于大数据的软件缺陷类别预测方法,其特征在于,利用特征完全提取技术提取每个源域的数据特征的过程包括:
4.根据权利要求1所述的一种基于大数据的软件缺陷类别预测方法,其特征在于,步骤s3具体包括:通过注意力机制对不同源域的特征进行加权,获得加权后的特征表征;将加权的特征表征送入flort模块进行特征融合,得到综合特征表征。
5.根据权利要求4所述的一种基于大数据的软件缺陷类别预测方法,其特征在于,通过注意力机制对不同源域的特征进行加权的过程包括:
6.根据权利要求4所述的一种基于大数据的软件缺陷类别预测方法,其特征在于,将不同域数据和其对应的注意力权重输入通过flort模板融合得到第二融合特征的过程包括:
7.根据权利要求1所述的一种基于大数据的软件缺陷类别预测方法,其特征在于,将第一融合特征和第二融合特征进行最后的融合得到最终融合特征的过程包括:
8.根据权利要求1所述的一种基于大数据的软件缺陷类别预测方法,其特征在于,多源域融合分类器模型进行分类的过程包括:
9.根据权利要求1所述的一种基于大数据的软件缺陷类别预测方法,其特征在于,经过源域i与目标域数据之间的注意力权重加权的源域i与源域j的数据特征相似度表示为:
技术总结本发明属于深度学习领域,特别涉及一种基于大数据的软件缺陷类别预测方法,包括从不同源域中采集软件的运行数据,对数据进行预处理操作;计算每个源域数据的权重,同时将预处理后的数据利用特征完全提取技术提取每个源域的数据特征;使用注意力机制对不同源域的特征加权得到第一融合特征,将不同域数据和其对应的注意力权重输入通过Flort模板融合得到第二融合特征;将第一融合特征和第二融合特征进行最后的融合得到最终融合特征,将最终融合特征作为多源域融合分类器模型的输入;多源域融合分类器模型考虑源域与目标源、源域与源域之间的关系对预测输入的特征是否存在目标域中的缺陷类型。本发明提高了软件缺陷类别预测的准确性和稳定性。技术研发人员:张焱,王进,肖飞,李丹受保护的技术使用者:重庆邮电大学技术研发日:技术公布日:2024/11/18本文地址:https://www.jishuxx.com/zhuanli/20241120/331902.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表