基于图数据库和向量数据库的数据处理和存储方法及装置
- 国知局
- 2024-11-21 11:49:48
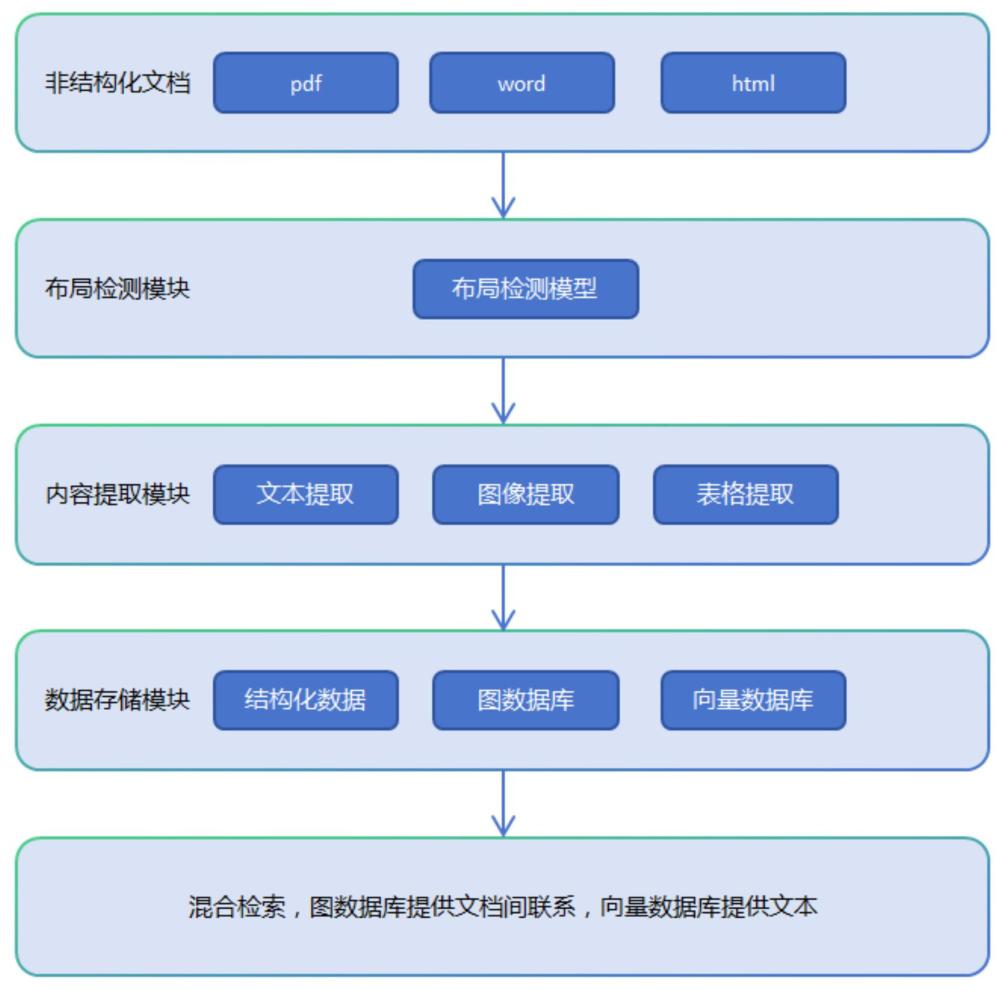
本发明涉及大数据处理,特别是一种基于图数据库和向量数据库的数据处理和存储方法及装置。
背景技术:
1、近年来,随着llm(大语言模型)的迅速发展,基于大语言模型的应用层出不穷,但是llm存在“胡说八道”和幻觉的问题,因此研究人员提出了一种结合检索(retrieval)与生成(generation)的语言模型,即rag模型。rag模型首先需要构建知识库,然后根据用户的问题从知识库中检索相关信息,并结合llm的生成功能输出答案,从而提高了llm问答的准确性。然而,rag技术的效果在很大程度上依赖于知识库中结构化数据的质量。如果数据结构化程度低,那么检索到的信息可能不够准确或包含噪声,进而导致生成模块基于不可靠的上下文生成结果,从而影响最终的输出质量。
2、为了解决这一问题,本发明提出了一种结合图数据库neo4j和向量数据库elasticsearch的数据处理与存储方法,旨在实现对文档图片的布局分析与数据转换处理。在该方法中,neo4j擅长于存储和处理包含复杂关系的数据,利用节点和边的形式直观地表示数据及其相互关系。而elasticsearch作为向量数据库,提供了一种高效的方式来存储和检索基于向量的特征数据,用于处理非结构化数据的搜索任务,如文本和图像的相似性搜索。
3、为了更好地分析文档的布局,本发明采用layoutlmv3文档布局分析模型,能够识别和分析文档中的不同元素,如文本、表格、图像区域等,使文档处理更加智能化和高效。结合基于transformer模型的表格转换模型和ocr技术,这些工具能够将文档中的非结构化数据(如图像、表格、文本等)自动转换为可结构化处理的文本数据,从而大大提高了文档信息的可访问性和利用性。
4、综上所述,本发明提出了一种基于图数据库neo4j和向量数据库elasticsearch的数据处理与存储方法,结合layoutlmv3、基于transformer的表格转换模型与ocr技术,实现对文档图片的布局分析与数据转换处理。该方法中,图数据库凭借其灵活的数据模型和强大的语义表达能力,能够有效存储和查询复杂的关系网络;向量数据库则通过向量化技术,将文本、图像等数据转换为数值向量,以支持高效的相似性搜索和数据聚类,从而确保rag技术所需的高质量数据输入。
技术实现思路
1、本发明针对现有技术的不足,即对非结构化数据和半结构化数据(如文档、图片、表格等)有效存储的局限性,提出了一种基于图数据库和向量数据库的数据处理和存储方法及装置,提供给用户一种更高效、更准确、更可靠的数据预处理方法。
2、本发明所提出的方法是通过以下技术方案来实现的:一种基于图数据库和向量数据库的数据处理和存储方法,该方法包括以下步骤:
3、步骤1:识别文档布局以及进行表格格式转换,将识别后的内容转换成markdown格式并存储;
4、步骤2:基于大语言模型提取markdown格式文件中文档的主题、参考文件和附录关键信息;
5、步骤3:将markdown格式文件转换为非机构化数据,进行数据块划分存入向量数据库,基于文档的关键信息,构建文档间的关系类型集合,生成可视化知识图谱。
6、进一步地,步骤1中,通过构建布局检测模型,分析文档布局,构建步骤如下:
7、1)获取模型训练的数据集,包括publaynet数据集和手动收集标注的自建数据集,并划分为训练集和测试集;
8、2)设计布局检测模型架构,基于layoutlmv3架构利用文档图像来识别文档的结构,实现将文档图像划分出文本、图像、表格3类区域的功能;
9、3)训练布局检测模型,设定学习率,通过交叉熵损失函数来衡量模型预测与实际标签之间的差异,并通过adam优化器对模型参数进行更新。
10、进一步地,步骤1中,通过构建表格转换模型,将表格转换为json格式,构建步骤如下:
11、1)获取模型训练的数据集,包括fetaqa、tat-qa数据集和手动收集标注的自建中文表格数据集,并划分训练集和测试集;
12、2)设计表格检测模型的架构,基于transformer架构添加可训练的提示学习模块,辅助模型的生成任务;
13、3)训练表格转换模型,设定学习率,通过交叉熵损失函数来衡量模型预测与实际标签之间的差异,并用adamw优化器来提高训练稳定性。
14、进一步地,将文档转换为文档图像后,使用布局检测模型分析文档图像的内容布局,将文档图像划分出文本、图像、表格3类区域,并用不同的颜色进行表示;布局检测模型输出所有区域框的四个边界值,表示区域在图像中的位置,每个检测到的区域会被分配一个类别标签; 提取文本、图像和表格区域的内容,将提取的数据保存为markdown格式。
15、进一步地,步骤3中,构建数据存储模块,将转换后的markdown格式的文档进行结构化划分,保存在图数据库neo4j和向量数据库elasticsearch中,构建步骤如下:
16、1)针对markdown文档进行结构化划分;对于文本数据,以标题作为段落的划分依据,对于段落内的文本,采用滑动窗口技术进行划分数据块;对于表格和图像数据,以每个实体为单位,将每个表格或图像视为一个独立的数据块;
17、2)定义实体类型集合和关系类型集合,其中实体类型集合文档名和文档类型;关系类型集合基于文档的主题、参考文件、附录关键信息,生成文档之间的联系;将得到的实体关系二元组导入neo4j数据库,形成可视化文档关系知识图谱;
18、3)在elasticsearch中创建一个关联类型的索引,该索引存储了文档的具体数据,索引的结构由属性信息组成,属性包括索引的唯一id,文档的唯一的file_id,文档的theme,content,embedding,type和level;
19、4)依据划分的数据块,使用bge-embedding向量化模型将所有数据块拓展后保存在elasticsearch向量数据库中。
20、进一步地,所述布局检测模型使用文本-图像多模态transformer来学习跨模态特征,通过使用掩码语言建模mlm、掩码图像建模mim和词块对齐wpa三个模块实现对文本信息和图像信息的捕捉;其中掩码语言建模随机遮盖一部分的文本词向量,但保留对应的二维位置信息,任务目标是根据未被遮盖的图文和布局信息还原文本中被遮盖的词;掩码图像建模随机遮盖一部分的图像块,任务目标是根据未被遮盖的文本和图像的信息还原被遮盖的图像块经过离散化的id;词块对齐通过显式地预测一个文本词的对应图像块是否被掩盖来学习语言和视觉模态之间的细粒度对齐关系。
21、进一步地,所述表格转换模型叠加采用了一个12层的transformer,特别的,在输入表格内容前添加特殊符号“instruction:”,用于提示文本生成,并且在每层的多头注意力模块中添加可训练向量来预训练任务的提示;训练过程中,首先将表格压平成一个序列,以便直接输入到模型中;通过插入特殊的标记来表示表的边界。
22、进一步地,构建一个以“主题”为核心的图数据库,形成一个互联的信息网络,在这个网络中,“主题”节点占据中心地位,与多个“文件”节点相连,每个“文件”节点均是一个丰富的信息集合,包含“参考文件”、“es索引”、“附件”子节点;所有节点通过参考文件、附录的关系类型与其他节点相连,形成一个复杂的语义网络。
23、进一步地,将数据块以向量化表示,对于图像数据,在转为向量表示后,单独在elasticsearch中存储,具体的,使用bge-embedding向量化模型,向量化划分的数据块,在elasticsearch数据库中以文件作为索引,每个文件包括多个数据块,每个数据块有着独自的数据类型;特别的,同时在elasticsearch数据库保存文件数据块的原始版本,即未经过向量化的版本,以实现混合检索。
24、另一方面,本发明还提供了一种基于图数据库和向量数据库的数据处理和存储装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现所述的一种基于图数据库和向量数据库的数据处理和存储方法。
25、本发明的有益效果如下:
26、1.通过使用多种专业的解析器对文档中的不同数据类型进行解析,该发明能够全面识别并准确提取文本、表格、图像等多模态数据。
27、2.构建多模态知识图谱,有效地将非结构化数据转换为结构化形式,存储在图数据库中,同时保留了数据的层次结构和语义信息。
28、3.在elasticsearch中同时保存原始数据和向量化数据,支持对原始数据和向量化数据的混合检索,增强了检索的一致性和灵活性。
29、4.结合图数据库和向量数据库的优势,该发明提供了一种高效的信息检索机制,能够实现快速且准确的语义搜索。
本文地址:https://www.jishuxx.com/zhuanli/20241120/332916.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。