基于文本分类的交互式数据处理方法及系统与流程
- 国知局
- 2024-11-21 11:51:26
本发明涉及数据处理,尤其涉及一种基于文本分类的交互式数据处理方法及系统。
背景技术:
1、目前,在实现游戏服务或软件产品中的人机交互时,大部分仍然采用预先设定好的对话选项和应答规则来实现,例如在玩家与虚拟角色进行交互时,会提供多个选项给玩家作为发言的选项,服务器上会预存每一选项对应的答案以及后续的进一步数据规则。这一现有技术的做法显然无法为用户提供更加智能化的对话交互服务,且由于预设规则可能存在没有充分试验导致的矛盾,也容易导致用户的交互对话发生出错导致服务崩溃,因此其稳定性也存在问题。可见,现有技术存在缺陷,亟待解决。
技术实现思路
1、本发明所要解决的技术问题在于,提供一种基于文本分类的交互式数据处理方法及系统,能够实现为用户提供更加智能和多样的交互对话服务,提高交互对话服务的效率和自由度,减少出错。
2、为了解决上述技术问题,本发明第一方面公开了一种基于文本分类的交互式数据处理方法,所述方法包括:
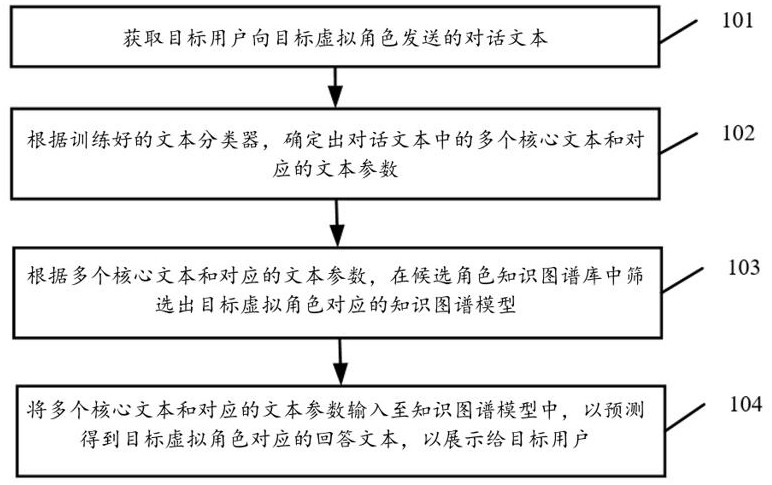
3、获取目标用户向目标虚拟角色发送的对话文本;
4、根据训练好的文本分类器,确定出所述对话文本中的多个核心文本和对应的文本参数;
5、根据所述多个核心文本和对应的文本参数,在候选角色知识图谱库中筛选出所述目标虚拟角色对应的知识图谱模型;
6、将所述多个核心文本和对应的文本参数输入至所述知识图谱模型中,以预测得到所述目标虚拟角色对应的回答文本,以展示给所述目标用户。
7、作为一个可选的实施方式,在本发明第一方面中,所述核心文本为对话目的文本、对话动机文本、下一步动作描述文本、上一步动作总结文本或指令文本。
8、作为一个可选的实施方式,在本发明第一方面中,所述文本参数包括文本目的和文本安全性;所述文本目的为发出问题、回答问题、作出选择、结束选择、引发联想、开启剧情、推进剧情或结束剧情。
9、作为一个可选的实施方式,在本发明第一方面中,所述根据训练好的文本分类器,确定出所述对话文本中的多个核心文本和对应的文本参数,包括:
10、对所述对话文本进行分词处理和随机划分处理,得到多个文本片段;
11、对所有所述文本片段基于聚类算法进行初步分类,得到多个文本片段集合;
12、对于每一所述文本片段集合,将该文本片段集合中的每一文本片段输入至训练好的核心文本预测神经网络,以得到每一所述文本片段对应的核心文本概率;所述核心文本分类神经网络通过包括有多个训练对话文本和对应的核心文本标注的训练数据集训练得到;
13、计算该文本片段集合中所有所述文本片段的核心文本概率的平均值,得到该文本片段集合对应的集合概率参数;
14、对于每一所述文本片段,计算该文本片段对应的核心文本概率与对应的概率权重的乘积,得到该文本片段对应的片段概率参数;所述概率权重与该文本片段所属的文本片段集合对应的所述集合概率参数成正比;
15、将所述片段概率参数大于第一参数阈值的所述文本片段确定为核心文本;
16、根据所述核心文本对应的所述文本片段集合,以及文本参数识别神经网络,确定每一所述核心文本对应的文本参数。
17、作为一个可选的实施方式,在本发明第一方面中,所述对所有所述文本片段基于聚类算法进行初步分类,得到多个文本片段集合,包括:
18、设定目标函数为每一文本片段集合中的文本数量达到最多以及所有所述文本片段集合的总集合数量达到最小;
19、设定限制条件包括:
20、每一文本片段集合中的任一文本片段和该文本片段集合中所有文本片段组成的文本之间的文本相似度大于第一相似度阈值;
21、任意两个不同的文本片段集合的所有文本片段组合的文本之间的文本相似度小于第二相似度阈值;所述第二相似度阈值小于所述第一相似度阈值;
22、每一文本片段集合中的任一文本片段与该文本片段集合中所有文本片段之间的隶属度参数大于第一隶属度阈值;
23、每一文本片段集合中的任一文本片段与任一其他的文本片段集合中所有文本片段之间的隶属度参数小于第二隶属度阈值;所述第二隶属度阈值小于所述第一隶属度阈值;
24、基于动态规划算法,根据所述目标函数和所述限制条件对所有所述文本片段基于聚类算法进行迭代分类直至收敛,得到多个文本片段集合。
25、作为一个可选的实施方式,在本发明第一方面中,所述根据所述核心文本对应的所述文本片段集合,以及文本参数识别神经网络,确定每一所述核心文本对应的文本参数,包括:
26、对于每一所述核心文本,将该核心文本对应的所述文本片段集合中每一所述片段概率参数大于第二参数阈值的文本片段确定为相关文本片段;所述第二参数阈值小于所述第一参数阈值;
27、将该核心文本对应的每一所述相关文本片段输入至训练好的文本参数识别神经网络中,以得到每一所述相关文本片段对应的预测文本参数;所述文本参数识别神经网络通过包括有多个训练文本和对应的文本参数标注的训练数据集训练得到;所述预测文本参数包括预测文本目的参数和预测文本安全性;
28、计算所有所述相关文本片段对应的预测文本目的参数之间的交集,得到该核心文本对应的文本目的;
29、计算所有所述相关文本片段对应的预测文本安全性的平均值,得到该核心文本对应的文本安全性。
30、作为一个可选的实施方式,在本发明第一方面中,所述根据所述多个核心文本和对应的文本参数,在候选角色知识图谱库中筛选出所述目标虚拟角色对应的知识图谱模型,包括:
31、对于候选角色知识图谱库中的每一候选知识图谱模型,获取该候选知识图谱模型对应的训练知识库数据;
32、分析所述训练知识库数据以得到对应的知识库角色参数集合和知识库文本参数集合;
33、根据所述多个核心文本和对应的文本参数、所述知识库角色参数集合和所述知识库文本参数集合,计算该候选知识图谱模型和所述目标虚拟角色之间的模型匹配度;
34、将所述模型匹配度最高的所述候选知识图谱模型,确定为所述目标虚拟角色对应的知识图谱模型。
35、作为一个可选的实施方式,在本发明第一方面中,所述根据所述多个核心文本和对应的文本参数、所述知识库角色参数集合和所述知识库文本参数集合,计算该候选知识图谱模型和所述目标虚拟角色之间的模型匹配度,包括:
36、计算每一所述核心文本对应的所述文本参数和所述知识库文本参数集合之间的第一相似度的平均值,得到第一匹配度参数;
37、计算所述目标虚拟角色的角色参数和所述知识库角色参数集合之间的第二相似度;所述角色参数或所述知识库角色参数集合中包括有角色名称、角色简介、角色职业、角色功能和角色性别;
38、计算所述第一匹配度参数和所述第二相似度的乘积,得到该候选知识图谱模型和所述目标虚拟角色之间的模型匹配度。
39、本发明实施例第二方面公开了一种基于文本分类的交互式数据处理系统,所述系统包括:
40、获取模块,用于获取目标用户向目标虚拟角色发送的对话文本;
41、分类模块,用于根据训练好的文本分类器,确定出所述对话文本中的多个核心文本和对应的文本参数;
42、筛选模块,用于根据所述多个核心文本和对应的文本参数,在候选角色知识图谱库中筛选出所述目标虚拟角色对应的知识图谱模型;
43、预测模块,用于将所述多个核心文本和对应的文本参数输入至所述知识图谱模型中,以预测得到所述目标虚拟角色对应的回答文本,以展示给所述目标用户。
44、作为一个可选的实施方式,在本发明第二方面中,所述核心文本为对话目的文本、对话动机文本、下一步动作描述文本、上一步动作总结文本或指令文本。
45、作为一个可选的实施方式,在本发明第二方面中,所述文本参数包括文本目的和文本安全性;所述文本目的为发出问题、回答问题、作出选择、结束选择、引发联想、开启剧情、推进剧情或结束剧情。
46、作为一个可选的实施方式,在本发明第二方面中,所述分类模块根据训练好的文本分类器,确定出所述对话文本中的多个核心文本和对应的文本参数的具体方式,包括:
47、对所述对话文本进行分词处理和随机划分处理,得到多个文本片段;
48、对所有所述文本片段基于聚类算法进行初步分类,得到多个文本片段集合;
49、对于每一所述文本片段集合,将该文本片段集合中的每一文本片段输入至训练好的核心文本预测神经网络,以得到每一所述文本片段对应的核心文本概率;所述核心文本分类神经网络通过包括有多个训练对话文本和对应的核心文本标注的训练数据集训练得到;
50、计算该文本片段集合中所有所述文本片段的核心文本概率的平均值,得到该文本片段集合对应的集合概率参数;
51、对于每一所述文本片段,计算该文本片段对应的核心文本概率与对应的概率权重的乘积,得到该文本片段对应的片段概率参数;所述概率权重与该文本片段所属的文本片段集合对应的所述集合概率参数成正比;
52、将所述片段概率参数大于第一参数阈值的所述文本片段确定为核心文本;
53、根据所述核心文本对应的所述文本片段集合,以及文本参数识别神经网络,确定每一所述核心文本对应的文本参数。
54、作为一个可选的实施方式,在本发明第二方面中,所述分类模块对所有所述文本片段基于聚类算法进行初步分类,得到多个文本片段集合的具体方式,包括:
55、设定目标函数为每一文本片段集合中的文本数量达到最多以及所有所述文本片段集合的总集合数量达到最小;
56、设定限制条件包括:
57、每一文本片段集合中的任一文本片段和该文本片段集合中所有文本片段组成的文本之间的文本相似度大于第一相似度阈值;
58、任意两个不同的文本片段集合的所有文本片段组合的文本之间的文本相似度小于第二相似度阈值;所述第二相似度阈值小于所述第一相似度阈值;
59、每一文本片段集合中的任一文本片段与该文本片段集合中所有文本片段之间的隶属度参数大于第一隶属度阈值;
60、每一文本片段集合中的任一文本片段与任一其他的文本片段集合中所有文本片段之间的隶属度参数小于第二隶属度阈值;所述第二隶属度阈值小于所述第一隶属度阈值;
61、基于动态规划算法,根据所述目标函数和所述限制条件对所有所述文本片段基于聚类算法进行迭代分类直至收敛,得到多个文本片段集合。
62、作为一个可选的实施方式,在本发明第二方面中,所述分类模块根据所述核心文本对应的所述文本片段集合,以及文本参数识别神经网络,确定每一所述核心文本对应的文本参数的具体方式,包括:
63、对于每一所述核心文本,将该核心文本对应的所述文本片段集合中每一所述片段概率参数大于第二参数阈值的文本片段确定为相关文本片段;所述第二参数阈值小于所述第一参数阈值;
64、将该核心文本对应的每一所述相关文本片段输入至训练好的文本参数识别神经网络中,以得到每一所述相关文本片段对应的预测文本参数;所述文本参数识别神经网络通过包括有多个训练文本和对应的文本参数标注的训练数据集训练得到;所述预测文本参数包括预测文本目的参数和预测文本安全性;
65、计算所有所述相关文本片段对应的预测文本目的参数之间的交集,得到该核心文本对应的文本目的;
66、计算所有所述相关文本片段对应的预测文本安全性的平均值,得到该核心文本对应的文本安全性。
67、作为一个可选的实施方式,在本发明第二方面中,所述筛选模块根据所述多个核心文本和对应的文本参数,在候选角色知识图谱库中筛选出所述目标虚拟角色对应的知识图谱模型的具体方式,包括:
68、对于候选角色知识图谱库中的每一候选知识图谱模型,获取该候选知识图谱模型对应的训练知识库数据;
69、分析所述训练知识库数据以得到对应的知识库角色参数集合和知识库文本参数集合;
70、根据所述多个核心文本和对应的文本参数、所述知识库角色参数集合和所述知识库文本参数集合,计算该候选知识图谱模型和所述目标虚拟角色之间的模型匹配度;
71、将所述模型匹配度最高的所述候选知识图谱模型,确定为所述目标虚拟角色对应的知识图谱模型。
72、作为一个可选的实施方式,在本发明第二方面中,所述筛选模块根据所述多个核心文本和对应的文本参数、所述知识库角色参数集合和所述知识库文本参数集合,计算该候选知识图谱模型和所述目标虚拟角色之间的模型匹配度的具体方式,包括:
73、计算每一所述核心文本对应的所述文本参数和所述知识库文本参数集合之间的第一相似度的平均值,得到第一匹配度参数;
74、计算所述目标虚拟角色的角色参数和所述知识库角色参数集合之间的第二相似度;所述角色参数或所述知识库角色参数集合中包括有角色名称、角色简介、角色职业、角色功能和角色性别;
75、计算所述第一匹配度参数和所述第二相似度的乘积,得到该候选知识图谱模型和所述目标虚拟角色之间的模型匹配度。
76、本发明第三方面公开了另一种基于文本分类的交互式数据处理系统,所述系统包括:
77、存储有可执行程序代码的存储器;
78、与所述存储器耦合的处理器;
79、所述处理器调用所述存储器中存储的所述可执行程序代码,执行本发明第一方面公开的基于文本分类的交互式数据处理方法中的部分或全部步骤。
80、本发明第四方面公开了一种计算机存储介质,所述计算机存储介质存储有计算机指令,所述计算机指令被调用时,用于执行本发明第一方面公开的基于文本分类的交互式数据处理方法中的部分或全部步骤。
81、与现有技术相比,本发明实施例具有以下有益效果:
82、本发明能够基于训练好的文本分类器确定出用户的对话文本中的多个核心文本和对应的文本参数,再基于此筛选出合适的知识图谱模型以预测出合理以及准确的回答文本,从而能够实现为用户提供更加智能和多样的交互对话服务,提高交互对话服务的效率和自由度,减少出错。
本文地址:https://www.jishuxx.com/zhuanli/20241120/333038.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表