对视频画面数据进行编码/解码的制作方法
- 国知局
- 2024-11-21 11:54:17
本技术一般而言涉及视频画面编码和解码。特别地,但不限于此,本技术的涉及参考块与参考画面的边界重叠的运动补偿的时间预测。
背景技术:
1、本节旨在向读者介绍本领域的各个方面,这些方面可以与下面描述和/或要求保护的本技术的至少一个示例性实施例的各个方面有关。本讨论被认为有助于向读者提供背景信息以促进更好地理解本技术的各个方面。因而,应当理解这些陈述应以此为视角来阅读,而不是作为对现有技术的承认。
2、在最先进的视频压缩系统中,诸如hevc(iso/iec 23008-2high efficiencyvideo coding,itu-t recommendation h.265,https://www.itu.int/rec/t-rec-h.265-202108-p/en)或vvc(iso/iec 23090-3versatile video coding,itu-t recommendationh.266,https://www.itu.int/rec/t-rec-h.266-202008-i/en),提供低级和高级画面分区以将视频画面划分为画面区块,所谓的编解码树单元(ctu),其尺寸通常对于hevc可以在16x16和64x64像素之间,并且对于vvc可以在32x32、64x64或128x128像素之间。
3、视频画面的ctu划分形成由固定尺寸的ctu组成的网格,即,ctu网格,其上边界和左边界在空间上与视频画面的上边界和左边界重合。ctu网格表示视频画面的空间分区。
4、在vvc和hevc中,ctu网格的所有ctu的ctu尺寸(ctu宽度和ctu高度)等于相同的默认ctu尺寸(默认ctu宽度ctu dw和默认ctu高度ctu dh)。例如,默认ctu尺寸(默认ctu高度、默认ctu宽度)可以等于128(ctu dw=ctu dh=128)。默认ctu尺寸(高度、宽度)被编码到比特流中,例如在序列参数集(sps)中的序列级别。
5、ctu网格中ctu的空间位置根据ctu地址ctuaddr确定,该地址定义ctu的左上角相对于原点的空间位置。如图1中所示,ctu地址可以定义从包含ctu的更高级别空间结构s的左上角开始的空间位置。
6、每个ctu都与编解码树相关联,以确定ctu的树划分。
7、如图1中所示,在hevc中,编解码树是ctu的四叉树划分,其中每个叶子被称为编解码单元(cu)。视频画面中cu的空间位置由cu索引cuidx定义,该cu索引指示从ctu的左上角开始的空间位置。cu在空间上被分区为一个或多个预测单元(pu)。视频画面vp中pu的空间位置由pu索引puidx定义,该pu索引定义从ctu的左上角开始的空间位置,而被分区的pu的元素的空间位置由pu分区索引pupartidx定义,该pu分区索引定义从pu的左上角开始的空间位置。每个pu都被指派了一些帧内或帧间预测数据。
8、编解码模式帧内或帧间是在cu级别被指派的。这意味着,虽然预测参数因pu而异,但向cu的每个pu指派有相同的帧内/帧间编解码模式。
9、根据被称为变换树的四叉树,cu还可以在空间上被分区为一个或多个变换单元(tu)。变换单元是变换树的叶子。视频画面中tu的空间位置由tu索引tuidx定义,该tu索引定义从cu的左上角开始的空间位置。每个tu都被指派了一些变换参数。变换类型在tu级别被指派,并且在画面块的编解码或解码期间在tu级别执行2d单独变换。
10、图2上图示了hevc中现有的pu分区类型。它们包括方形分区(2nx2n和nxn),这是唯一在帧内和帧间预测cu中都使用的分区,对称非方形分区(2nxn、nx2n,仅用在帧间预测cu中)和非对称分区(仅用在帧间预测cu中)。例如,pu类型2nxnu代表pu的非对称水平分区,其中较小的分区位于pu的顶部。根据另一个示例,pu类型2nxnl代表pu的非对称水平分区,其中较小的分区位于pu的顶部。
11、如图3中所示,在vvc中,编解码树从根节点(即,ctu)开始。接下来,四叉树(或四元树)拆分将根节点划分为4个节点,与4个尺寸相等的子块(实线)对应。接下来,四叉树(或四元树)叶子可以通过所谓的多类型树被进一步划分,这涉及根据图4中所示的4种拆分模式之一进行二叉或三叉拆分。这些拆分类型是垂直和水平二叉拆分模式(记为sbtv和sbth)以及垂直和水平三叉拆分模式spttv和stth。
12、在亮度和色度分量共享的联合编解码树的情况下,ctu的编解码树的叶子是cu。
13、与hevc相反,在vvc中,在大多数情况下,cu、pu和tu具有相等的尺寸,这意味着除了在一些特定的编解码模式中之外,编解码单元一般不分区为pu或tu。
14、图5和图6提供了例如当前视频标准压缩系统(如hevc或vvc)中使用的视频编码/解码方法的概述。
15、图5示出了根据现有技术对视频画面vp进行编码的方法100的步骤的示意性框图。
16、在步骤110中,将视频画面vp分区成样本块并将分区信息数据用信号发送到比特流中。每个块包括视频画面vp的一个分量的样本。因此,这些块包括定义视频画面vp的每个分量的样本。
17、例如,在hevc中,画面被划分为编解码树单元(ctu)。每个ctu可以使用四叉树划分进一步细分,其中四叉树的每个叶子表示为编解码单元(cu)。然后,分区信息数据可以包括描述ctu的数据以及每个ctu的四叉树细分。
18、于是,每个样本块(简称块)可以是cu(如果cu包括单个pu)或者cu的pu。
19、使用帧内或者帧间预测模式,沿着编码循环(也称为“循环中”)对每个块进行编码。
20、帧内预测(步骤120)使用帧内预测数据。帧内预测包括借助于基于已编码、解码和重构的样本的帧内预测的块来预测当前块,该样本位于当前块周围,通常位于当前块的顶部和左侧。帧内预测在空间域中执行。
21、在帧间预测模式下,执行运动估计(步骤130)和运动补偿(135)。运动估计在用于预测性地编码当前视频画面的一个或多个参考画面中搜索作为当前块的良好预测器的参考块。在单向运动估计/补偿中,候选参考块属于表示为l0或l1的参考画面列表的单个参考画面,而在双向运动估计/补偿中,候选参考块得自参考画面列表l0的参考块和参考画面列表l1的参考块。
22、例如,当前块的良好预测器是与当前块相似的候选参考块。它也可以对应于在与当前块的相似性与指示其用于当前块的时间预测所需的运动信息的速率成本之间提供良好权衡的参考块。
23、运动估计步骤130的输出是帧间预测数据,其包括与当前块相关联的运动信息和用于在编码/解码侧获得相同预测块的其他信息。通常,运动信息包括用于单向估计/补偿的一个运动向量和参考画面索引以及用于双向估计/补偿的两个运动向量和两个参考画面索引。接下来,运动补偿(步骤135)借助于由运动估计步骤130确定的(一个或多个)运动向量和(一个或多个)参考画面索引获得预测块。基本上,属于所选择的参考画面并由运动向量指向的参考块可以被用作当前块的预测块。此外,由于运动向量以整数像素位置的分数表达(这被称为亚像素准确性运动向量表示),因此运动补偿一般而言涉及参考画面的一些重构样本的空间插值以计算预测块。
24、将预测信息数据发信号通知到比特流中。预测信息可以包括预测模式(帧内、帧间或跳过)、帧内/帧间预测数据以及用于在解码侧获得相同预测块的任何其他信息。
25、考虑到计算出的预测残差块的编码(例如,通过从当前块中减去候选预测块)以及在解码侧确定所述候选预测块所需的预测信息数据的发信号通知,方法100通过优化速率-失真权衡来选择一种预测模式(帧内或帧间预测模式)。
26、通常,最佳预测模式作为由下式给出的当前块的最佳编解码模式p*的预测模式给出:
27、
28、其中p是当前块的所有候选编解码模式的集合,p表示该集合中的候选编解码模式,rdcost(p)是候选编解码模式p的速率-失真成本,通常表达为:
29、rdcost(p)=d(p)+λ.r(p)
30、d(p)是当前块与用候选编解码模式p对当前块进行编码/解码之后获得的重构块之间的失真,r(p)是与用编解码模式p对当前块进行编解码相关联的速率成本,并且λ是表示对当前块进行编解码的速率约束的拉格朗日参数并且通常根据用于对当前块进行编码的量化参数计算得出。
31、当前块通常由预测残差块pr编码而成。更精确地说,例如,通过从当前块中减去最佳预测块来计算预测残差块pr。然后,通过使用例如dct(离散余弦变换)或dst(离散正弦变换)类型变换或任何其他适当的变换来变换预测残差块pr(步骤140),并且对获得的变换后的系数块进行量化(步骤150)。
32、在变体中,方法100还可以根据所谓的变换-跳过编解码模式跳过变换步骤140并直接对预测残差块pr应用量化(步骤150)。
33、将量化的变换系数块(或量化的预测残差块)熵编码到比特流中(步骤160)。
34、接下来,作为编码循环的一部分,对量化的变换系数块(或量化的残差块)进行去量化(步骤170)和逆变换(180)(或不进行),从而得到解码的预测残差块。然后,组合(通常是求和)解码的预测残差块和预测块,从而提供重构的块。
35、还可以在步骤160中对其他信息数据进行熵编码,以对视频画面vp的当前块进行编码。
36、可以将循环中滤波器(步骤190)应用于重构的画面(包括重构的块)以减少压缩伪影。可以在重构所有画面块之后应用循环滤波器。例如,它们包括去块滤波器、样本自适应偏移量(sao)或自适应环路滤波器。
37、重构的块或经滤波的重构的块形成参考画面,该参考画面可以存储到解码的画面缓冲器(dpb)中,以便可以被用作用于对视频画面vp的下一个当前块进行编码的参考画面或用作用于对下一个要编码的视频画面的进行编码的参考画面。
38、图6示出了根据现有技术对视频画面vp进行解码的方法200的步骤的示意性框图。
39、在步骤210中,通过对编码的视频画面数据的比特流进行熵解码来获得分区信息数据、预测信息数据和量化的变换系数块(或量化的残差块)。例如,这个比特流已根据方法100而生成。
40、还可以对其他信息数据进行熵解码,以从比特流中解码视频画面vp的当前块。
41、在步骤220中,基于分区信息将重构的画面划分为当前块。每个当前块沿着解码循环(也称为“循环中”)从比特流中熵解码。每个解码的当前块是量化的变换系数块,或者是量化的预测残差块。
42、在步骤230中,对当前块进行去量化并且可能进行逆变换(步骤240),以获得解码的预测残差块。
43、另一方面,预测信息数据被用于预测当前块。通过其帧内预测(步骤250)或其运动补偿的时间预测(步骤260)获得预测块。在解码侧执行的预测过程与编码侧的预测过程完全相同。
44、接下来,组合(通常是求和)解码的预测残差块和预测块,这提供重构的块。
45、在步骤270中,循环中滤波器可以应用于重构的画面(包括重构的块),并且重构的块或经滤波的重构的块形成参考画面,该参考画面可以存储到解码的画面缓冲器(dpb)中,如上面所讨论的(图5)。
46、在vvc中,运动信息以4×4块为单位存储在每个视频画面中。这意味着一旦参考画面被存储在解码的画面缓冲器(dpb,图5或图6)中,用于视频画面块的时间预测的运动向量和参考画面索引就会以4×4块为基础被存储。它们可以用作运动信息的时间预测,用于对后续的帧间预测视频画面进行编码/解码。
47、在vvc中,当前块的时间预测可以基于参考画面的参考块,该参考块可以与所述参考画面的边界重叠。例如,图7示出了基于参考画面列表l0的第一参考块和参考画面列表l1的第二参考块的当前块的双向运动补偿的预测的示例。第一(分别地第二)参考块由第一(分别地第二)运动向量指向。在图7的示例中,第一参考块部分地位于参考画面列表l0的参考画面之外,而第二参考块位于参考画面列表l1的参考画面之内。更一般地,两个参考画面之一的参考块或这两个参考画面的两个参考块可以部分地或全部位于参考画面边界之外。
48、在vvc中,为了处置此类情况,参考画面通过简单的填充方法进行扩展,该方法包括对视频画面边界样本bs进行垂直填充,如图8中所示。这包括简单地沿着垂直于参考画面边界的样本行或列重复边界样本值bs,超出这个边界。参考画面沿着其每个边界扩展m个样本的扩展部分。
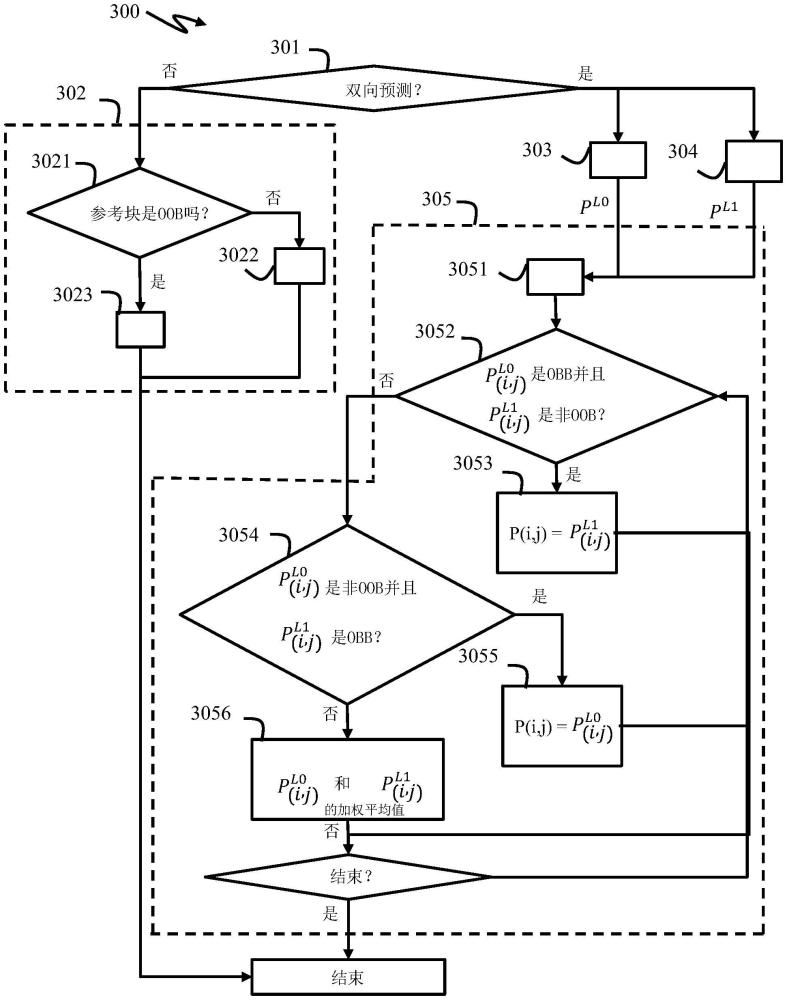
49、在现有技术中,基于帧间或帧内预测的填充方法改进了图8的基本填充。
50、jvet贡献jvet-j0014的2.1.7.5节描述了一种基于帧内预测的填充方法(“description of sdr,hdr and 360°video coding technology proposal byfraunhofer hhi”,itu-t sg 16wp 3和iso/iec jtc 1/sc 29/wg 11的联合视频探索小组(jvet),第10次会议:美国圣地亚哥,2018年4月10日至20日,文档jvet-j0014)。基本上,每当被参考的样本区块部分地或全部位于参考画面的区块之外时,多方向边界填充(mdbp)使用角度帧内预测来扩展参考画面边框。通过使用位于重构的参考画面内的模板区块(如图9中所示),在编码器和解码器二者中估计最佳帧内模式。通过使用所有可用的帧内编解码模式并通过从最外面的像素线进行帧内预测来得出模板区块的样本值来填充模板区块。最佳帧内编解码模式导致相对于原始重构的样本值的最小sad。
51、jvet贡献jvet-j0021的第3.1节描述了第一种基于帧间预测的填充方法(“description of sdr,hdr and 360°video coding technology proposal by qualcommand technicolor-low and high complexity versions”,itu-t sg 16wp 3和iso/iecjtc 1/sc 29/wg 11的联合视频探索小组(jvet),第10次会议:美国圣地亚哥,2018年4月10日至20日,文档https://jvet-experts.org/doc_end_user/documents/10_san%20diego/wg11/jvet-j0021-v5.zip)。基本上,如图10中所示,当解码器执行运动补偿时,如果与当前视频画面的块cb相关联的运动向量mv1指向至少部分地位于参考画面1的边界之外的块rb,那么参考块rb的区域z不可用。如图11中所示,周围的填充区域被拆分成尺寸为4×m或m×4的一个子区域sz,以及尺寸为4×(p-z)的第二个子区域pz,其,其中p是完整填充区块的尺寸。对于沿着参考画面的边界的每个子区域sz,运动向量mv2得自参考画面1内的最近的4×4子块nb和参考画面2的4×4子块。如果最近的4×4子块nb是帧内编解码的(帧内预测的),那么使用零运动向量mv2。如果用双向帧间预测对最近的4×4子块nb进行编解码(预测),那么在用于填充的运动补偿中仅使用指向远离其参考画面的边界的样本的运动向量。在运动向量推导之后,然后考虑到最近的4×4子块与其在参考画面2中的对应块之间的平均样本值偏移量,使用所选择的运动向量mv2和参考画面2执行运动补偿,以获得填充子区域sz中的样本。注意的是,基于帧间预测的经扩展区域的尺寸m是由运动向量mv2的值得出的并且与画面边界与由运动向量mv2所指向的位置之间的距离有关,参见图11。此外,尺寸m可以小于参考画面的完整填充尺寸p。在这种情况下,基于帧间预测的填充由vvc的基本垂直填充进一步完成。这意味着通过帧间预测填充的区块通过上面参考vvc提到的基本垂直填充进行扩展。
52、jvet贡献jvet-j0025的2.1.7.5节中描述了第二种基于帧间预测的填充方法(“description of sdr,hdr and 360°video coding technology proposal by huawei,gopro,hisilicon,and samsung-general application scenario”,itu-t sg 16wp 3和iso/iec jtc 1/sc 29/wg 11的联合视频探索小组(jvet),第10次会议:美国圣地亚哥,2018年4月10日至20日,文档https://jvet-experts.org/doc_end_user/documents/10_san%20diego/wg11/jvet-j0025-v4.zip)。基本上,如果视频画面的边界样本是通过运动补偿得出的,那么所填充样本也通过使用所述运动补偿得出,如图12中所示。对于使用参考块的邻居样本,进行由所填充样本所参考的区块的运动补偿。如果该区块小于所填充的区块或者边界块不是通过运动补偿得出的,那么使用最近样本得出左侧填充的样本。通过使用每个位置的最近样本得出填充区块的左上角、右上角、左下角、右下角。该方法在进行循环中滤波之后进行。
53、jvet贡献jvet-y0125的2.1.7.5节中描述了处置边界外参考块的第三种帧间预测方法(“ahg12:enhanced bi-directional motion compensation”,yi-wen chen、che-weikuo、ning yan、wei chen、xiaoyu xiu、xianglin wang,itu-t sg 16wp 3和iso/iec jtc1/sc 29联合视频专家组(jvet)第25次会议,通过电话会议,2022年1月12日至21日,文档jvet-y0125)。基本上,为了避免预测(运动补偿的预测)块b至少部分地超出参考画面边界(这不太有效),当组合多于一个运动补偿的预测块时,预测块b的oob(边界外)预测样本被丢弃并且仅使用非oob(边界内)预测样本来生成最终的预测块。更精确地说,令(pos_xi,j,pos_yi,j)为当前块内样本位置(i,j)的笛卡尔坐标。令为当前块内与样本位置(i,j)相关联的运动向量(mv)的笛卡尔坐标(lx指示参考画面是属于参考画面列表l0(x=0)还是属于参考画面列表l1(x=1)。令posleftbdry,posrightbdry,postopbdry,posbottombdry是4个参考画面边界的笛卡尔坐标。
54、当以下条件中至少有一个成立时,预测块plx的样本位置(i,j)的预测样本被视为oob
55、
56、或者
57、
58、当上述条件都不成立时,预测样本被视为非oob。此处,half_sample表示两个邻近亮度样本之间的距离的一半,根据编解码器的mv内部表示准确性(对于vvc是1/16像素)。否则,预测样本将被视为oob。如果预测块plx的至少一个样本是oob,那么该预测块将被视为oob;并且当其所有样本都是非oob,那么该预测块将被视为非oob。此处,根据编解码器的mv内部表示准确性(对于vvc是1/16像素),half_sample表示2个样本之间的距离的一半。
59、接下来,如果预测样本是oob并且预测样本是非oob,那么最终的预测样本等于预测样本
60、否则,如果预测样本是非oob并且预测样本是oob,那么最终的预测样本等于预测样本
61、否则,最终的预测样本由两个预测样本和的加权平均值给出。这个加权平均值通常是均值,因此使用权重1/2和1/2)。
62、第三种基于帧间预测的填充方法的局限性在于它无法处置其中mv指向oob参考块的单向预测块的情况。而且,当与属于参考画面列表l0和l1二者的参考画面相关联的所有预测块都是oob时,它无法改进vvc的双向运动补偿方法。
63、jvet-y0125中提出的边界外预测块管理方法还有改进的空间。
64、本发明解决的问题是进一步提高现有视频编解码标准(如hevc或vvc)的压缩率。
65、特别地,所解决的问题是在某一运动向量指向参考画面的边界之外的参考块的情况下提高运动补偿的时间预测的效率。
66、本技术的至少一个示例性实施例是考虑到上述情况而设计的。
技术实现思路
1、以下部分对至少一个示例性实施例进行简要概述,以便对本技术的一些方面提供基本理解。本概述并非示例性实施例的详尽概述。其目的并非识别示例性实施例的关键或核心要素。以下概述仅以简化的形式给出至少一个示例性实施例的一些方面,作为本文档其他地方提供的更详细描述的序言。
2、根据本技术的第一方面,提供了一种将视频画面编码成经编码的视频画面数据的比特流的方法,该方法包括通过基于由与视频画面块相关联的至少一个运动向量指向的至少一个参考画面的至少一个参考块获得时间预测的块来对视频画面块进行时间预测,其中,如果视频画面块的时间预测基于参考画面的单个参考块,那么该方法还包括基于从视频画面内当前块的最近子块导出的运动向量来填充参考块。
3、根据本技术的第一方面,提供了一种用于从经编码的视频画面数据的比特流中解码视频画面的方法,该方法包括通过基于由与视频画面块相关联的至少一个运动向量指向的至少一个参考画面的至少一个参考块获得时间预测的块来对视频画面块进行时间预测,其中,如果视频画面块的时间预测基于参考画面的单个参考块,那么该方法还包括基于从视频画面内当前块的最近子块导出的运动向量来填充参考块。
4、在一个示例性实施例中,如果视频画面块的时间预测基于参考画面的单个参考块,并且如果参考块至少部分地位于参考画面的边界之外,那么该方法还包括基于从视频画面内当前块的最近子块导出的运动向量来填充参考块。
5、在一个示例性实施例中,如果视频画面块的时间预测基于第一参考画面的第一参考块和第二参考画面的第二参考块,那么该方法还包括根据第一预测块的给定位置处的样本是否在第一参考画面的边界之外并且根据第二预测块的相同位置处的样本是否在另一个参考画面的边界之外,通过基于样本对第一预测块和第二预测块求平均来获得当前视频画面块的最终运动补偿的预测。
6、在一个示例性实施例中,第一预测块和第二预测块是通过使用单向运动补偿的预测获得的。
7、在一个示例性实施例中,基于从视频画面内当前块的最近子块导出的运动向量来填充参考画面的参考块,和/或基于从视频画面内当前块的最近子块导出的运动向量来填充另一个参考画面的参考块,并且单向运动补偿的预测基于参考块或者经填充的参考块。
8、在一个示例性实施例中,仅当第一预测块或第二预测块在参考画面中的位置超出扩展参考画面的时间预测的区块时,才认为第一预测块或第二预测块位于第一参考画面或第二参考画面的边界之外。
9、在一个示例性实施例中,当第一预测块或第二预测块从帧间编解码的子块导出时,第一预测块或第二预测块被视为位于第一参考画面或第二参考画面的边界之外,而当第一预测块或第二预测块从帧内编解码的子块导出时,第一预测块或第二预测块被视为位于第一参考画面或第二参考画面的边界之内。
10、在一个示例性实施例中,最近子块是帧内编解码或者帧间编解码的。
11、在一个示例性实施例中,将语法元素发信号通知到比特流中,以指示对参考画面的参考块的填充是基于从视频画面内当前块的最近子块导出的运动向量还是基于基于帧内预测的填充方法。
12、在一个示例性实施例中,语法元素在序列画面或切片级别上被发信号通知。
13、根据本技术的第三方面,提供了一种通过根据本技术的第一方面的方法之一生成的经编码的视频画面数据的比特流。
14、根据本技术的第四方面,提供了一种装置,包括用于执行根据本技术的第一和/或第二方面的方法之一的部件。
15、根据本技术的第五方面,提供了一种包括指令的计算机程序产品,当程序由一个或多个处理器执行时,使得该指令使得一个或多个处理器执行根据本技术的第一和/或第二方面的方法。
16、根据本技术的第六方面,提供了一种非暂态存储介质,其携带用于执行根据本技术的第一和/或第二方面的方法的程序代码指令。
17、示例性实施例中的至少一个的具体性质以及所述至少一个示例性实施例的其他目的、优点、特征和用途将从以下结合附图对示例进行的描述中变得显而易见。
本文地址:https://www.jishuxx.com/zhuanli/20241120/333311.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。