1.本发明涉及知识图谱、nlp、人工智能领域,具体来说,涉及一种基于反馈自学习的动态字典库生成方法。
背景技术:
2.自然语言处理(nlp)是计算机科学领域和人工智能领域中的一个重要方向。实体识别、关系抽取又是自然语言处理方向的一个比较常见的应用,现有的实现技术也相对比较成熟。根据实体、关系数据结合行业特点,构建行业知识库,通过关系图谱展现方式显示知识库内容,让用户能够更直观、多维度的分析文件内容,随着对知识库的完善,自动优化行业模型,最终生成一条完善的行业知识库及行业模型。
3.但是现有技术中从基础字典库、自动标注模型训练、到标注数据反馈更新字典库的全流程为单独流程,并不能实现闭环
4.针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
5.本发明的目的在于提供一种基于反馈自学习的动态字典库生成方法,以解决上述背景技术中提出的问题。
6.为实现上述目的,本发明提供如下技术方案:
7.一种基于反馈自学习的动态字典库生成方法,包括以下步骤:
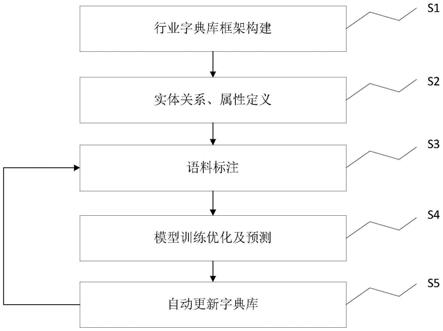
8.s1、字典库定义,初步定义字典库体系,完成字典库整体框架结构设置,按照实体分类层次结构,逐步细化实体分类;
9.s2、基于字典库分类体系,针对每种分类定义对应的描述信息,包括类与类之间的关系,每类对应的描述信息;
10.s3、根据定义好的实体分类、实体关系、实体属性,对现有语料数据进行标注,标注过程支持实体、关系选择,将标注数据导出等功能;
11.s4、基于语料库导出的标注数据,配合模型参数调整,逐步迭代优化模型,基于现有模型结合验证数据进行自动数据标注操作,生成最新预测数据;
12.s5、将s4步生成的预测数据回填到字典库,并确认自动标注数据是否正确,在此过程中,可以同步对字典库进行修改、调整,调整后的数据会自动进入模型训练过程。
13.进一步的,所述步骤s1字典库定义,初步定义字典库体系,完成字典库整体框架结构设置,按照实体分类层次结构,逐步细化实体分类包括以下步骤:
14.s11、构建横向行业内的各种概念分类体系与纵向每种概念分类进行细化形成动态立体网状结构;
15.s12、针对每种概念分类需要设置全局唯一的分类编码;
16.s13、按照一定的逻辑规则进行编码,编码中可以识别出层次关系、父类对象等信息;
17.s14、字典库与模型自动标注的关联关系就是通过分类编码进行匹配。
18.进一步的,所述横向行业内的各种概念分类体系包括地点、人物、机构;
19.所述纵向每种概念分类进行细化包括分类型进行二级分类、三级分类。
20.进一步的,所述步骤s2基于字典库分类体系,针对每种分类定义对应的描述信息,包括类与类之间的关系,每类对应的描述信息中,关系的定义逻辑采用主体、客体、关系三种对象表示,其中,其中主体、客体即为 s1步骤中的实体分类,关系是用来表示主、客体之间的描述,关系主要包括三方面内容:关系编码、关系名称、关系方向。
21.进一步的,所述步骤s3根据定义好的实体分类、实体关系、实体属性,对现有语料数据进行标注,标注过程支持实体、关系选择,将标注数据导出包括以下步骤:
22.步骤s31、根据已有的模型识别语料数据中的实体,并且高亮显示实体内容;
23.步骤s32、根据实体识别的情况,进行人工调整;
24.步骤s33、选择主体、客体进行拖动,构建关系,拖动完成后根据主客体的类型自动识别与其最相近的实体关系;
25.步骤s34、根据标注的数据生成模型训练所需要的语料数据,包括实体识别模型和关系识别模型。
26.步骤s35、将以上步骤标注的实体语料、关系语料分别生成模型可用的数据源。
27.进一步的,所述步骤s4基于语料库导出的标注数据,配合模型参数调整,逐步迭代优化模型,基于现有模型结合验证数据进行自动数据标注操作,生成最新预测数据包括以下步骤:
28.s41、基于s3步骤生成的数据源信息,分别训练实体识别模型和关系抽取模型。
29.s42、基于tensorflow框架,bert模型中实体识别、关系抽取预训练模型进行实体识别模型、关系抽取模型训练;
30.s43、训练过程中可根据模型评价结果,对模型参数进行调整来逐步优化模型;
31.s44、最终通过模型对语料数据进行实体识别、关系抽取,生成预测数据。
32.进一步的,所述步骤s5中生成的字典库内容主要有两种:实体内容、实体关系内容。
33.与现有技术相比,本发明具有以下有益效果:
34.本发明所述方法主要基于语料自动标注、实体识别、关系识别等技术,整体实现从行业语料数据到行业模型再到行业数据自动标注生成字典库流程闭环操作。本发明主要基于业务系统将字典库图谱的展现方式,同时提供对字典库的编辑、维护操作,使字典库逐渐细粒度化,最终构建出能够满足特定领域需求的分析字典库,该过程利用nlp技术实现模型训练,基于训练得到的模型自动对新的语料数据进行标注,并更新到基础字典库中,达到整个流程的闭环运行。本发明公开了一种基于自然语言处理技术实现的数据自动标注、模型持续优化反向更新标注数据的自学习方法。该方法通过概念模式定义、自然语言处理技术、全流程调度机制,实现从原始语料概念模式定义生成基础字典库,在基础字典库基础上进行标注模型的自动构建、迭代训练及修正,最后再利用标注模型来进行新的语料数据标注,反馈更新字典库,实现从标注训练到反馈自学习的闭环流程,达到模型自动逐步优化能力。最终实现字典库的自动完善,标注模型逐步优化的全自动循环过程。
附图说明
35.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
36.图1是根据本发明实施例的一种基于反馈自学习的动态字典库生成方法的整体流程图;
37.图2是根据本发明实施例的一种基于反馈自学习的动态字典库生成方法中字典库分类体系的结构示意图;
38.图3是根据本发明实施例的一种基于反馈自学习的动态字典库生成方法中实体属性关系图的结构示意图;
39.图4是根据本发明实施例的一种基于反馈自学习的动态字典库生成方法中实体关系图的结构示意图。
具体实施方式
40.下面,结合附图以及具体实施方式,对发明做出进一步的描述,本发明所述方法主要基于语料自动标注、实体识别、关系识别等技术,整体实现从行业语料数据到行业模型再到行业数据自动标注生成字典库流程闭环操作。整个流程如图1所示,具体实现步骤如下:
41.请参阅图1
‑
4,根据本发明实施例的一种基于反馈自学习的动态字典库生成方法,包括以下步骤:
42.s1、字典库定义,初步定义字典库体系,完成字典库整体框架结构设置,按照实体分类层次结构,逐步细化实体分类;
43.该步骤主要是基于行业特点,构建具有行业代表性的实体分类体系。分类体系结构上看,可以形成动态立体网状结构。横向可以包括行业内的各种概念分类体系,如:地点、人物、机构等,纵向可以对每种概念分类进行细化,对某细分类型进行二级分类、三级分类、
……
等;针对每种概念分类需要设置全局唯一的分类编码,编码按照一定的逻辑规则,编码中可以识别出层次关系、父类对象等信息,如按照“父类编码.编码”。分类编码在该发明中是至关重要的组成部分,字典库与模型自动标注的关联关系就是通过分类编码进行匹配,如图2所示实体分类体系。
44.s2、基于字典库分类体系,针对每种分类定义对应的描述信息,包括类与类之间的关系,每类对应的描述信息;
45.基于s1步骤构建的实体分类体系,在s2步骤中主要是定义实体分类与分类之间的逻辑关系,关系的定义要根据具体的行业场景,定义后的关系能够在识别出的实体中最大体现出行业关注点。关系的定义逻辑采用主体、客体、关系三种对象表示,其中主体、客体即为s1步骤中的实体分类,关系是用来表示主、客体之间的描述。关系主要包括三方面内容:关系编码、关系名称、关系方向。定义后的数据格式如下:
……
。实体分类属性信息主要用于描述分类下的实体信息,如:人物分类,属性中需要定义姓名、职位、出生地等描述信息。
46.s3、根据定义好的实体分类、实体关系、实体属性,对现有语料数据进行标注,标注过程支持实体、关系选择,将标注数据导出等功能;
47.基于以上两个步骤构建完成的实体分类、关系、属性体系,完成s3对应的语料标注步骤。该步骤主要将现有的语料数据和实体分类体系通过标注工作。语料标注内容主要包括实体、关系、属性。
48.s31、根据已有的模型识别语料数据中的实体,并且高亮显示实体内容;
49.s32、根据实体识别的情况,进行人工调整;
50.s33、选择主体、客体进行拖动,构建关系,拖动完成后根据主客体的类型自动识别与其最相近的实体关系;
51.s34、根据标注的数据生成模型训练所需要的语料数据,包括实体识别模型和关系识别模型。
52.实体识别模型语料规则:
53.实体标注采用常用的bioes命名实体标注方法,b表示这个词处于一个实体的开始(begin),i表示内部(inside),o表示外部(outside),e 表示这个词处于一个实体的结束为止,s表示,这个词是自己就可以组成一个实体(single)。标注完成的数据按照该命名方法生成预测数据,提供实体识别模型训练使用。
54.关系抽取模型语料规则:
55.关系抽取模型语料数据结构采用三元组形式组合成的json数据, sro_l ist表示关系列表的list,其中每个对象存储一个三元组的关系数据,实体编码、关系编码、客体编码;text表示标注的语句,数据样式如下:
56.{"sro_list":
57.[
[0058]
{"object":"主体编号","predicate":"关系编码","subject":"客体编码"},
[0059]
{"object":"主体编号","predicate":"关系编码","subject":"客体编码"}
[0060]
],
[0061]
"text":"语料句子"
[0062]
}
[0063]
s35、将以上步骤标注的实体语料、关系语料分别生成模型可用的数据源。
[0064]
s4、基于语料库导出的标注数据,配合模型参数调整,逐步迭代优化模型,基于现有模型结合验证数据进行自动数据标注操作,生成最新预测数据;
[0065]
基于s3步骤生成的数据源信息,分别训练实体识别模型和关系抽取模型。基于tensorflow框架,bert模型中实体识别、关系抽取预训练模型进行实体识别模型、关系抽取模型训练,训练过程中可根据模型评价结果,对模型参数进行调整来逐步优化模型,最终通过模型对语料数据进行实体识别、关系抽取,生成预测数据。
[0066]
s5、将s4步生成的预测数据回填到字典库,并确认自动标注数据是否正确,在此过程中,可以同步对字典库进行修改、调整,调整后的数据会自动进入模型训练过程。
[0067]
s5步骤主要将模型生成的预测数据回填到字典库。生成的字典库内容主要有两种:实体内容、实体关系(包括属性)内容。
[0068]
实体内容更新逻辑:实体存储逻辑为一个实体一个map对象,最后封装成一个json对象,向后端字典更新数据。map对象中存储实体名称 (entityname)、实体分类编码(entityclassifycode)、来源句子 (sourcesentence)、来源文章(sourcedocument)四部分
内容。字典库更新过程中,根据entityclassifycode、sourcesentence、sourcedocument 做唯一性判断,如果实体存在则进行更新操作,实体数据状态为“更新”,否则进行插入操作,实体数据状态为“新词”。
[0069]
关系更新:
[0070]
实体属性更新数据结构:每个句子进行一次关系提取,提取后封装成 json对象保存到字典库。json对象中主要包括:关系(relations)、来源句子(sourcesentence)、来源文章(sourcedocument),其中关系中用了该句识别出的具体关系其中包括主体(object)、客体(subject)、关系(predicate)。
[0071]
实体属性更新逻辑:
[0072]
实体属性字典库更新逻辑为:首先判断当前关系是否是主体所属分类的属性内容,如果是属性则更新为主体的属性,否则更新为主体、客体关系。
[0073]
在实际应用时,本发明所述方法主要基于语料自动标注、实体识别、关系识别等技术,整体实现从行业语料数据到行业模型再到行业数据自动标注生成字典库流程闭环操作。本发明主要基于业务系统将字典库图谱的展现方式,同时提供对字典库的编辑、维护操作,使字典库逐渐细粒度化,最终构建出能够满足特定领域需求的分析字典库,该过程利用nlp技术实现模型训练,基于训练得到的模型自动对新的语料数据进行标注,并更新到基础字典库中,达到整个流程的闭环运行。本发明公开了一种基于自然语言处理技术实现的数据自动标注、模型持续优化反向更新标注数据的自学习方法。该方法通过概念模式定义、自然语言处理技术、全流程调度机制,实现从原始语料概念模式定义生成基础字典库,在基础字典库基础上进行标注模型的自动构建、迭代训练及修正,最后再利用标注模型来进行新的语料数据标注,反馈更新字典库,实现从标注训练到反馈自学习的闭环流程,达到模型自动逐步优化能力。最终实现字典库的自动完善,标注模型逐步优化的全自动循环过程。
[0074]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。