1.本技术涉及计算机技术领域,特别涉及一种特征生成方法及装置、电子设备、计算机可读存储介质。
背景技术:
2.企业业务发展积累了大量、多维度的结构化数据。在为企业业务引入机器学习模型时,需要为业务从海量的数据中提取出有效的特征,使得以特征训练出的机器学习模型可以准确的满足业务需求。
3.在相关技术中,可以基于关系路径的方法从数据中提取特征。该方法可以从数据集中获取多个实体(entity),依据多个实体生成有向关系集合,并根据有向关系集合和目标实体,生成目标实体的关系路径集合。基于目标实体的关系路径集合,生成目标实体的特征集合。
4.然而,基于关系路径的方法由于计算的复杂度和冗余度,通常只能局限于小量的数据集合、小量的字段数量,应用小量的算子,产生低阶的衍生特征,无法推广到大规模数据集合复杂的应用场景中。
技术实现要素:
5.本技术实施例的目的在于提供一种特征生成方法及装置、电子设备、计算机可读存储介质,用于在基于关系路径的方法生成特征时,降低计算复杂度,提升特征生成的效率。
6.一方面,本技术提供了一种特征生成方法,包括:
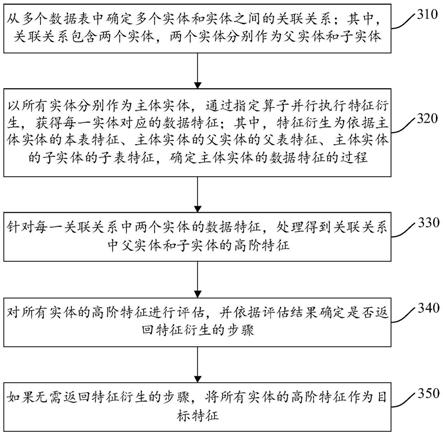
7.从多个数据表中确定多个实体和实体之间的关联关系;其中,所述关联关系包含两个实体,两个实体分别作为父实体和子实体;
8.以所有实体分别作为主体实体,通过指定算子并行执行特征衍生,获得每一实体对应的数据特征;其中,特征衍生为依据主体实体的本表特征、主体实体的父实体的父表特征、主体实体的子实体的子表特征,确定主体实体的数据特征的过程;
9.针对每一关联关系中两个实体的数据特征,处理得到所述关联关系中父实体和子实体的高阶特征;
10.对所有实体的高阶特征进行评估,并依据评估结果确定是否返回特征衍生的步骤;
11.如果无需返回特征衍生的步骤,将所有实体的高阶特征作为目标特征。
12.在一实施例中,在所述通过指定算子并行执行特征衍生之前,所述方法还包括:
13.根据预设数据筛选策略对所述多个数据表进行筛选,过滤异常数据。
14.在一实施例中,在所述通过指定算子并行执行特征衍生之前,所述方法还包括:
15.依据预设算子筛选策略对特征工程算子库进行筛选,得到若干指定算子。
16.在一实施例中,所述对所有实体的高阶特征进行评估,并依据评估结果确定是否
返回特征衍生的步骤,包括:
17.从所有实体的高阶特征筛选出指定高阶特征;
18.依据所述指定高阶特征对机器学习模型进行训练,获得已训练的业务模型;
19.获取所述业务模型的模型评估指标,作为所述高阶特征的评估结果;
20.比对所述评估结果与前一轮次的评估结果,并依据比对结果确定是否返回特征衍生的步骤。
21.在一实施例中,所述从所有实体的高阶特征筛选出指定高阶特征,包括:
22.根据目标业务对应的特征选择策略,从所有实体的高阶特征中确定指定高阶特征;其中,所述目标业务为所述业务模型对应的业务。
23.在一实施例中,所述依据比对结果确定是否返回特征衍生的步骤,包括:
24.如果所述比对结果指示所述评估结果与前一轮次的评估结果之间的相似度,达到预设相似度阈值,确定无需返回特征衍生的步骤;
25.如果所述比对结果指示所述评估结果与前一轮次的评估结果之间的相似度,未达到预设相似度阈值,确定需返回特征衍生的步骤。
26.在一实施例中,所述方法还包括:
27.如果需要返回特征衍生的步骤,依据预设特征筛选策略对所有实体的高阶特征进行筛选,过滤无效高阶特征。
28.另一方面,本技术还提供了一种特征生成装置,包括:
29.确定模块,用于从多个数据表中确定多个实体和实体之间的关联关系;其中,所述关联关系包含两个实体,两个实体分别作为父实体和子实体;
30.生成模块,用于以所有实体分别作为主体实体,通过指定算子并行执行特征衍生,获得每一实体对应的数据特征;其中,特征衍生为依据主体实体的本表特征、主体实体的父实体的父表特征、主体实体的子实体的子表特征,确定主体实体的数据特征的过程;
31.处理模块,用于针对每一关联关系中两个实体的数据特征,处理得到所述关联关系中父实体和子实体的高阶特征;
32.评估模块,用于对所有实体的高阶特征进行评估,并依据评估结果确定是否返回特征衍生的步骤;
33.终止模块,用于如果无需返回特征衍生的步骤,将所有实体的高阶特征作为目标特征。
34.进一步的,本技术还提供了一种电子设备,所述电子设备包括:
35.处理器;
36.用于存储处理器可执行指令的存储器;
37.其中,所述处理器被配置为执行上述特征生成方法。
38.另外,本技术还提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序可由处理器执行以完成上述特征生成方法。
39.本技术方案,从数据表中确定多个实体和实体之间的关联关系之后,以所有实体分别为主体实体,通过指定算子并行执行特征衍生,获得每一实体对应的数据特征;针对关联关系中两个实体的数据特征,处理得到两个实体的高阶特征,并可对高阶特征进行评估,依据评估结果确定是否再次进行特征衍生;当无需重复进行特征衍生时,可以将所有实体
的高阶特征作为目标特征。本方案在特征衍生时,以所有实体分别为主体实体,并行执行特征衍生,且特征衍生时仅对关联关系中父实体和子实体进行处理,有效地提升了特征衍生的效率,降低了一次特征衍生的计算量。
附图说明
40.为了更清楚地说明本技术实施例的技术方案,下面将对本技术实施例中所需要使用的附图作简单地介绍。
41.图1为本技术一实施例提供的特征生成方法的应用场景示意图;
42.图2为本技术一实施例提供的电子设备的结构示意图;
43.图3为本技术一实施例提供的特征生成方法的流程示意图;
44.图4为本技术一实施例提供的关联关系的示意图;
45.图5为本技术一实施例提供的高阶特征的评估方法的流程示意图;
46.图6为本技术另一实施例提供的特征生成方法的流程示意图;
47.图7为本技术一实施例提供的关联关系的示意图;
48.图8为本技术一实施例提供的特征生成装置的框图。
具体实施方式
49.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行描述。
50.相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。同时,在本技术的描述中,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
51.图1为本技术实施例提供的特征生成方法的应用场景示意图。如图1所示,该应用场景包括客户端20和服务端30;客户端20可以是主机、手机、平板电脑等用户终端,用于向服务端30发送特征生成请求;服务端30可以是服务器、服务器集群或云计算中心,可以响应于特征生成请求,依据特征生成请求所指示的多个数据表和特征用途,生成数据特征。
52.如图2所示,本实施例提供一种电子设备1,包括:至少一个处理器11和存储器12,图2中以一个处理器11为例。处理器11和存储器12通过总线10连接,存储器12存储有可被处理器11执行的指令,指令被处理器11执行,以使电子设备1可执行下述的实施例中方法的全部或部分流程。在一实施例中,电子设备1可以是上述服务端30,用于执行特征生成方法。
53.存储器12可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(static random access memory,简称sram),电可擦除可编程只读存储器(electrically erasable programmable read
‑
only memory,简称eeprom),可擦除可编程只读存储器(erasable programmable read only memory,简称eprom),可编程只读存储器(programmable red
‑
only memory,简称prom),只读存储器(read
‑
only memory,简称rom),磁存储器,快闪存储器,磁盘或光盘。
54.本技术还提供了一种计算机可读存储介质,存储介质存储有计算机程序,计算机程序可由处理器11执行以完成本技术提供的特征生成方法。
55.参见图3,为本技术一实施例提供的特征生成方法的流程示意图,如图3所示,该方法可以包括以下步骤310
‑
步骤350。
56.步骤310:从多个数据表中确定多个实体和实体之间的关联关系;其中,关联关系包含两个实体,两个实体分别作为父实体和子实体。
57.其中,实体时客观存在并可相互区别的事务。对于数据库,实体往往指某类事务的集合。实体可以包括行为类实体(比如:购买、销售等)、实物类实体(比如:商户、订单等)。
58.每一数据表对应一个实体,服务端可以依据数据表的id主键确定数据表对应的实体。示例性的,订单表对应的实体为订单;商户表对应的实体为商户;客户表对应的实体为客户。
59.服务端可以依据数据表内实体之间的对应关系,确定实体之前的关联关系。
60.一种情况下,两个实体均为实物类实体,记为实体a和实体b。从数据表中,可以确定实体a与实体b之间存在多对一的关系,则实体a与实体b存在关联关系,在该关联关系中,实体a为子实体,实体b为父实体。示例性的,实物类实体“客户”和“订单”,在订单数据表中,一个客户对应多个订单,因此,“客户”为父实体,“订单”为子实体。
61.另一种情况下,一个实体为实物类实体,记为实体c;另一个实体为行为类实体,记为实体d。从数据表中,可以确定实体c与实体d之间存在多对一或一对多的关系,则实体c与实体d存在关联关系,在该关联关系中,实体c为父实体,实体d为子实体。示例性的,实体类实体“商户”与行为类实体“交易”在交易数据表中存在对应关系,因此,“商户”为父实体,“交易”为子实体。
62.步骤320:以所有实体分别作为主体实体,通过指定算子并行执行特征衍生,获得每一实体对应的数据特征;其中,特征衍生为依据主体实体的本表特征、主体实体的父实体的父表特征、主体实体的子实体的子表特征,确定主体实体的数据特征的过程。
63.这里,算子是数据的处理、转换、聚合等特征工程算法的简称。指定算子为预先指定用于执行特征衍生的算子。
64.在确定多个实体和实体之间的关联关系之后,服务端可以针对每一实体,执行特征衍生过程,获得该实体的数据特征。对于任一实体而言,该实体可能涉及多个关联关系,且在不同关联关系中,同一实体的实体身份不同。比如,实体a涉及第一关联关系和第二关联关系,在第一关联关系中,实体a为子实体;在第二关联关系中,实体a为父实体。
65.参见图4,为本技术一实施例提供的关联关系的示意图,如图4所示,实体a与实体b构成一个关联关系,此时,实体a为父实体,实体b为子实体;实体b与实体c构成一个关联关系,此时,实体b为父实体,实体c为子实体。
66.以任一实体为主体实体,执行特征衍生时,服务端可以确定该实体的本表特征和关联特征。这里,本表特征是以主体实体对应数据表确定的特征;关联特征可以包括父表特征和子表特征,父表特征是以主体实体的父实体对应数据表确定的特征,子表特征是以主体实体的子实体对应数据表确定的特征。
67.服务端可以通过指定算子将主体实体对应的数据表中特征进行转换,从而得到本表特征。实例性的,主体实体对应的数据表包含日期,可以将日期转换为年份、月份等作为本表特征。
68.服务端可以将父实体对应的数据表中特征,直接作为父表特征。服务端可以将子实体对应的数据表中特征进行求和、求最小值、求最大值等聚合处理,得到子表特征。
69.在获得本表特征、父表特征和子表特征之后,可以将本表特征、父表特征和子表特
征均作为主体实体的数据特征。
70.若任一实体在关联关系中仅具有单一的实体身份,服务端可以仅将该实体的父表特征或子表特征作为关联特征,在获得关联特征和本表特征后,获得该实体作为主体实体的数据特征。以图4为例,实体a与实体b构成一个关联关系,以实体a为主体实体时,实体a不存在父实体,只存在子实体。这种情况下,服务端可以将实体a对应的数据表中特征进行转换,得到本表特征,将实体b对应数据表中特征直接作为父表特征,并可将父表特征和本表特征作为实体a的数据特征。
71.为提升特征衍生的效率,服务端可以以所有实体分别作为主体实体,通过指定算子并行执行特征衍生,从而得到每一实体对应的数据特征。
72.步骤330:针对每一关联关系中两个实体的数据特征,处理得到关联关系中父实体和子实体的高阶特征。
73.在获得每一实体对应的数据特征之后,针对每一关联关系中的两个实体,服务端可以进行特征交叉,从而衍生得到关联关系中父实体与子实体的高阶特征。对于任一关联关系进行特征交叉时,以父实体为主体实体的特征交叉结果,与以子实体为主体实体的特征交叉结果不同。服务端可以以父实体为主体实体,对父实体的数据特征和子实体的数据特征进行特征交叉处理,得到父实体的高阶特征;以子实体为主体实体,对父实体的数据特征和子实体的数据特征进行特征交叉处理,得到子实体的高阶特征。
74.通过对每一关联关系进行处理,可以得到所有实体对应的高阶特征。
75.步骤340:对所有实体的高阶特征进行评估,并依据评估结果确定是否返回特征衍生的步骤。
76.步骤350:如果无需返回特征衍生的步骤,将所有实体的高阶特征作为目标特征。
77.在获得高阶特征之后,服务端可以对所有实体的高阶特征进行评估,获得评估结果。
78.当评估结果指示高阶特征不够有效时,服务端可以返回步骤320,重新执行特征衍生。当进入下一轮次的特征衍生过程时,每一实体的高阶特征均可作为该实体的本表特征。
79.当评估结果指示高阶特征足够有效时,无需返回特征衍生步骤,服务端可以将所有实体的高阶特征作为目标特征。其中,目标特征为最终挖掘出的特征。
80.在一实施例中,在执行步骤320之前,为降低特征衍生的计算量,服务端可以根据预设数据筛选策略对多个数据表进行筛选,过滤异常数据。
81.其中,数据筛选策略用于从多个数据表中筛选出异常的数据表和/或数据表中异常的数据列。
82.示例性的,在确定多个关联关系之后,针对每一关联关系,服务端可以确定该关联关系中子实体对应数据表与父实体对应数据表之间的匹配度。匹配度用于衡量数据的覆盖比例。比如,父实体为客户,子实体为订单,匹配度=(订单表中客户∩客户表中客户)/客户表中客户。
83.在获得匹配度之后,可以判断该匹配度是否达到预设匹配度阈值,若否,则子实体对应的数据表为异常的数据表,可以舍弃。这里,匹配度阈值可以是经验值。
84.示例性的,对于各数据表的各数据列,可以计算方差。如果方差低于预设方差阈值,确定数据列为异常的数据列,可以舍弃。
85.示例性的,服务端可以确定数据列中唯一值的个数与总行数的比值。如果该比值接近1,则该数据列中可能为标识符,可以舍弃,不作为特征衍生的数据。如果该比值接近0,则该数据列中可能所有数值均相同,可以舍弃,不作为特征衍生的数据。
86.示例性的,服务端可以判断同一数据表中是否存在高相关性的至少两个数据列,如果存在,可以仅保留一个数据列。
87.示例性的,服务端可以检查数据表中数据列的异常值,并计算异常值与总行数的占比,若该占比超过异常占比阈值,可以认定数据列异常,可以舍弃。
88.示例性的,服务端可以检查数据表中数据列的缺失率,该缺失率表示数据列中缺失的数值个数与总行数的比值。如果缺失率达到预设缺失率阈值,可以认定数据列异常,可以舍弃。
89.在过滤异常数据之后,服务端可以执行后续的特征衍生步骤。过滤异常数据之后,减少了大量无效的计算过程,从而提升了特征衍生的效率,节约了计算资源。
90.在一实施例中,在执行步骤320之前,为降低特征衍生的计算量,服务端可以依据预设算子筛选策略对特征工程算子库进行筛选,得到若干指定算子。
91.其中,算子筛选策略用于筛选通用性较高的算子。特征工程算子库内可以包含多个特征工程算子,特征工程算子库中的算子可以包括基础算子、挖掘算子和业务算子。
92.基础算子为基础、常用的特征工程算法,通用性强。挖掘算子为基于业务数据进行统计类数据挖掘方法而总结出的算法,通用性适中。业务算子为具有明确业务含义的数据处理加工算法,往往仅适用于指定数据表,通用性弱。
93.服务端可以选择所有基础算子,并依据预设白名单选择若干挖掘算子,将选中的挖掘算子和所有基础算子作为指定算子。
94.通过该措施,可以筛选出通用性强的算子用于特征衍生,避免以通用性弱的算子进行无效计算,大大降低了特征衍生的计算量。
95.在一实施例中,服务端在对所有实体的高阶特征进行评估,并依据评估结果确定是否返回特征衍生的步骤时,参见图5为本技术一实施例提供的高阶特征的评估方法的流程示意图,如图5所示,该方法可以包括如下步骤341
‑
步骤344。
96.步骤341:从所有实体的高阶特征筛选出指定高阶特征。
97.其中,指定高阶特征是筛选出的用于代表所有高阶特征的特征,对指定高阶特征的评估结果即为对所有高阶特征的评估结果。
98.步骤342:依据指定高阶特征对机器学习模型进行训练,获得已训练的业务模型。
99.在获得指定高阶特征之后,服务端可以依据指定高阶特征对机器学习模型进行训练。服务端可以依据指定高阶特征,构建样本数据,并依据样本数据训练机器学习模型,从而得到业务模型。
100.步骤343:获取业务模型的模型评估指标,作为高阶特征的评估结果。
101.在获得业务模型之后,可以应用业务模型,或者利用业务模型对测试数据进行处理,从而得到若干模型评估指标,作为高阶模型的评估结果。这里,模型评估指标可以是ks(kolmogorov
‑
smirnov)、auc(area under curve)、mse(mean square error)等一种或多种的组合。
102.步骤344:比对评估结果与前一轮次的评估结果,并依据比对结果确定是否返回特
征衍生的步骤。
103.这里,前一轮次的评估结果,为以前一轮次的指定高阶特征训练出的业务模型的模型评估指标。在第一次训练得到业务模型的情况下,前一轮次的评估结果为空。
104.服务端根据比对结果可以确定业务模型的性能是否改善。一方面,如果性能改善,说明特征衍生过程仍有助于获得更有效的高阶特征。这种情况下,可以返回特征衍生的步骤,进一步对特征进行挖掘。另一方面,如果性能未改善,说明特征衍生过程已无助于获得更有效的高阶特征。这种情况下,无需返回特征衍生的步骤。
105.在一实施例中,服务端从所有实体的高阶特征筛选出指定高阶特征时,可以根据目标业务对应的特征选择策略,从所有的高阶特征中确定指定高阶特征。其中,目标业务为业务模型对应的业务。
106.示例性的,服务端可以确定目标业务涉及的多个实体,并选择多个实体对应的高阶特征,作为指定高阶特征。比如:目标业务为预测客户在促销活动中的消费额,涉及实体包括“客户”、“订单”,选择“客户”和“订单”对应的高阶特征,作为指定高阶特征。
107.在一实施例中,服务端在依据比对结果确定是否返回特征衍生的步骤时,可以判断比对结果是否指示两者足够相似。
108.如果比对结果指示评估结果与前一轮次的评估结果之间的相似度,达到预设相似度阈值,确定无需返回特征衍生的步骤。
109.这里,相似度阈值可以是经验值,用于评估两次评估结果之间是否足够相似。服务端可以对同一类别的模型评估指标计算相似度,并确定是否达到相似度阈值(比如:95%)。当所有模型评估指标对应的相似度均达到相似度阈值时,可以确定无需返回特征衍生的步骤。
110.如果比对结果指示评估结果与前一轮次的评估结果之间的相似度,未达到预设相似度阈值,可以确定需返回特征衍生的步骤。服务端可以对同一类别的模型评估指标计算相似度,并确定是否达到相似度阈值。当存在任一模型评估指标对应的相似度未达到相似度阈值时,可以确定需返回特征衍生的步骤。
111.在一实施例中,如果需要返回特征衍生的步骤,服务端可以依据预设的特征筛选策略对所有实体的高阶特征进行筛选,过滤无效高阶特征。
112.其中,特征筛选策略用于过滤无效的高阶特征,从而减少后续特征衍生的计算量。
113.针对高阶特征,服务端可以确定若干项特征评价指标。示例性的,特征评价指标可以包括iv(information value)值、woe(weight of evidence)、通过决策树算法确定的特征重要程度、通过逻辑回归算法确定的特征权值等。
114.在获得特征评价指标之后,服务端可以依据特征评价指标过滤无效高阶特征。示例性的,对于iv值小于预设阈值、woe小于预设阈值、特征重要程度小于预设阈值、特征权值小于预设阈值的若干高阶特征,可以认定为无效特征进行过滤。
115.通过该措施,可以过滤无效的高阶特征,从而减少下一轮特征衍生过程的计算量,提高特征衍生的效率。
116.参见图6,为本技术另一实施例提供的特征生成方法的流程示意图,如图6所示,该特征生成方法包含本技术方案的所有实施例。
117.服务端可以从数据表中确定多个实体,以及实体之间的关联关系。每一关联关系
中包含两个实体,一个为父实体,另一个为子实体。
118.服务端可以过滤数据表中的异常数据,从而减少后续特征衍生过程中的无效计算。服务端可以从特征工程算子库筛选出通用的指定算子,用于特征衍生。
119.服务端可以以所有实体为主体实体,通过指定算子并行执行特征衍生。在特征衍生过程中,针对任一实体,以该实体的本表特征、该实体的父实体的父表特征和/或子实体的子表特征,确定该实体的数据特征。
120.参见图7,为本技术一实施例提供的关联关系的示意图,如图7所示,共有6个实体:实体a、实体b、实体c、实体d、实体e、实体f。实体a为实体b的父实体,实体b为实体c的父实体,实体c为实体d的父实体,实体d为实体e的父实体,实体e为实体f的父实体。
121.以图7为例,服务端可以分别以6个实体为主体实体,并行执行特征衍生。对于实体b而言,可以依据实体b对应的本表特征、实体a对应的父表特征和实体c对应的子表特征,确定实体b对应的数据特征。对于实体a而言,可以依据实体a对应的本表特征、实体b对应的子表特征,确定实体a对应的数据特征。对于实体f而言,可以依据实体f对应的本表特征、实体e对应的父表特征,确定实体f对应的数据特征。
122.需要说明的是,同一实体对应的本表特征、子表特征和父表特征,受主体实体的影响,可能是不同的。比如:以实体b为主体实体,所获得的实体c的子表特征,与实体c的本表特征不同。
123.在特征衍生之后,针对每个关联关系中两个实体的数据特征,可以进行特征交叉处理,从而分别得到两个实体的高阶特征。
124.获得高阶特征之后,可以从所有实体的高阶特征中选择若干指定高阶特征,并以指定高阶特征训练机器学习模型,得到业务模型。在业务模型的应用或测试过程中,可以得到业务模型的模型评估指标,作为高阶特征的评估结果。
125.服务端可以判断高阶特征的评估结果是否指示重新进行特征衍生。一方面,如果相比前一轮次的评估结果,评估结果指示业务模型的性能无改善,则无需返回特征衍生的步骤,可将当前所有实体的高阶特征作为目标特征。另一方面,如果相比前一轮次的评估结果,评估结果指示业务模型的性能有改善,则可以过滤无效的高阶特征,并返回特征衍生的步骤。
126.在进入下一轮次的特征衍生步骤时,每一实体的高阶特征可作为该实体的本表特征。以图7为例,在第一轮特征衍生过后,每个实体都获得高阶特征,并以高阶特征作为本表特征。服务端在第二轮特征衍生时,分别以6个实体为主体实体,并行执行特征衍生。对于实体b而言,可以依据实体b对应的本表特征、实体a对应的父表特征和实体c对应的子表特征,确定实体b对应的数据特征。这里,实体b对应的本表特征为第一轮获得的高阶特征,实体a对应的父表特征可由第一轮获得的高阶特征确定,实体c对应的子表特征可由第一轮获得的高阶特征确定。
127.对于实体a而言,可以依据实体a对应的本表特征、实体b对应的子表特征,确定实体a对应的数据特征。这里,实体a对应的本表特征为第一轮获得的高阶特征,实体b对应的子表特征可由第一轮获得的高阶特征确定。由于实体b第一轮获得的高阶特征与实体c第一轮的数据特征有关,因此,实体a第二轮的数据特征与实体c第一轮的数据特征有关。在特征衍生过程中,多个关联关系构成的关系路径中,特征会沿着路径上下传递。
128.在第二轮特征衍生之后,重新执行特征交叉及评估的步骤。上述过程反复迭代,直至高阶特征满足要求,最终获得目标特征。
129.图8是本发明一实施例的一种特征生成装置,如图8所示,该装置可以包括:
130.确定模块810,用于从多个数据表中确定多个实体和实体之间的关联关系;其中,所述关联关系包含两个实体,两个实体分别作为父实体和子实体;
131.生成模块820,用于以所有实体分别作为主体实体,通过指定算子并行执行特征衍生,获得每一实体对应的数据特征;其中,特征衍生为依据主体实体的本表特征、主体实体的父实体的父表特征、主体实体的子实体的子表特征,确定主体实体的数据特征的过程;
132.处理模块830,用于针对每一关联关系中两个实体的数据特征,处理得到所述关联关系中父实体和子实体的高阶特征;
133.评估模块840,用于对所有实体的高阶特征进行评估,并依据评估结果确定是否返回特征衍生的步骤;
134.终止模块850,用于如果无需返回特征衍生的步骤,将所有实体的高阶特征作为目标特征。
135.上述装置中各个模块的功能和作用的实现过程具体详见上述特征生成方法中对应步骤的实现过程,在此不再赘述。
136.在本技术所提供的几个实施例中,所揭露的装置和方法,也可以通过其它的方式实现。以上所描述的装置实施例仅仅是示意性的,例如,附图中的流程图和框图显示了根据本技术的多个实施例的装置、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或代码的一部分,模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。在有些作为替换的实现方式中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
137.另外,在本技术各个实施例中的各功能模块可以集成在一起形成一个独立的部分,也可以是各个模块单独存在,也可以两个或两个以上模块集成形成一个独立的部分。
138.功能如果以软件功能模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本技术各个实施例方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read
‑
only memory)、随机存取存储器(ram,randomaccess memory)、磁碟或者光盘等各种可以存储程序代码的介质。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。