1.本发明属于涉及信息技术领域,尤其是涉及一种基于运行状态采样的自适应微服务运行优化的方法,主要用于提升云计算和边缘计算复杂环境中基于多微服务协同运行的应用系统的运行性能,特别是降低通信延迟。
背景技术:
2.智慧园区和智慧城市等大规模人工智能应用场景的驱动下,云计算和边缘计算协同的方式已经成为处理具有不同特点的应用系统(数据密集、运算密集和通信密集)的运算环境。云计算满足多数据源、高计算压力需求应用,边缘计算2侧重于少量数据源但计算密集应用的需求。微服务1为提供应用系统构建提供了模块化标准,并具备高可用特性,作为构建大型应用系统的实现方式已经广泛落地。在落地微服务应用的云-边计算环境中,如何避免通信造成的性能瓶颈,是面向高吞吐数据处理能力所要解决的技术挑战。
3.本项发明通过以动态采样机制获取微服务通信状态和统计数据,并进行动态重构,实现基于即时编译4的动态调度的微服务通信优化技术。该技术通过计算动态采样信息,搜索最佳服务聚合方式,使具有高频通信的服务彼此间的通信成本降低,特别是将由通信介质导致服务间通信延迟降低,从而提升基于微服务应用的整体数据吞吐率。
技术实现要素:
4.本发明提供了一种基于运行状态采样的自适应微服务运行优化,微服务调度器通过微服务运行过程中的信息,动态分析微服务通信特征并计算优化的微服务聚合策略,从而降低不必要的节点服务器间网络通信和节点服务器内的总线通信。
5.为实现上述目的,本发明通过编译器静态分析技术3将微服务本身植入采样点,并向调度中心发送采样信息,由调度中心进行动态计算与规划,最终实现高效的服务重构(聚合),降低服务间通信延迟。整个优化与重构过程发生在基于微服务应用的运行过程中。本项发明适用于云-边协同环境,即计算效能、通信和存储i/o速率存在复杂配置的运行环境。
6.本项发明包含3部分:1.基于编译器技术的静态分析和采样代码植入;2. 通过采样代码获取的通信信息,在运行时分析基于微服务系统的运行状态,计算最佳通信策略;3.基于最佳通信策略进行动态重构,将可聚合的微服务通过动态编译重构,并通过调度系统将重构的微服务替换原有的微服务。
附图说明
7.图1微服务优化系统架构;图2基于价值模型来计算优化任务调度策略(即微服务的优化调配)的例子;图3服务聚合;图4系统流程图;图5效果流程图;
图6效果流程图。
具体实施方式
8.本项发明的实现方式包括静态代码分析与植入和运行时的通信状态分析、微服务重构与替换。静态代码分析与植入通过编译器插件分析微服务代码,并在涉及微服务间通信的代码(api)部分植入采样代码。微服务调度系统在运行时收集通信状态统计信息,为微服务制定重构策略,并通过在线代码重构,实现微服务聚合并将聚合后的微服务替换原有微服务,如图1所示。
9.基于编译器的采样代码植入通过编译器扫描微服务程序,并在每个微服务交互操作(调用其他微服务或被其他微服务调用)之前插入采样函数,如图1所示/采样函数每次被调用都会更新针对通信类型和地址的计数,如果计数达到阈值,则向调度中心发送统计信息,包括计数内容、参与通信的目标地址(或调用本服务的调用者地址)。
10.采样函数伪代码如下:type表示通信类型,dest_addr表示通信目的地址,size表示流量计数计数信息包括调用微服务间通信的次数和通信信息容量,触发向调度中心发送统计信息的条件也包含通信信息容量达到容量阈值。通信次数阈值和通信容量阈值均对应用某类通信和某个特定微服务,因此需要一个全局表来维护。这里通信类型由编译器分析得出,编译器通过反向追溯,判断参与通信的数据的来源,主要包括2种类型:cpu内存计算,gpu加速计算。
11.对于不同类型编程语言实现的微服务,可以通过不同类型编译器以基于源代码、中间代码或二进制代码的方式进行分析和代码植入。采样函数作为单独的函数库挂接于微服务实现中。语言类型分析与采样代码植入方式c/c 分析二进制文件并插入采样函数调用java分析bytecode文件并插入采样函数调用python分析源程序文件并插入采样函数调用
12.基于采样信息的微服务重构云-边集群调度中心在收集到统计信息后计算在运行环境中的任意两个微服务a和b是否可以聚合,且聚合后是否可以正常运行。判别聚合a和b的算法canaggregate(a,b) 如图6所示。
13.,这里freq函数表示基于统计信息计算的a与b的交互频率,volume函数表示a与b之间的数据交互容量,r这里为介于0与1之间的数值,可根据经验设定,表示频率与数据量对聚合判断的影响因子。如果基于交互频率和数据量计算的交互成本cost大于给定阈值threshold,则可考虑a与b进行聚合。这里阈值也通过用户以经验值来确定。
14.abletoexecute函数判别a与b聚合后是否可以正常运行,包括考察如下内容:1. a与b聚合后的cpu内存消耗是否可被a或b当前运行节点满足;2. a与b聚合后的网络带宽需求是否可被a或b当前运行节点满足;3. a与b聚合后的存储i/o带宽是否可被a或b当前运行节点满足;
4. a与b聚合后的gpu内存消耗是否可被a或b当前运行节点满足。
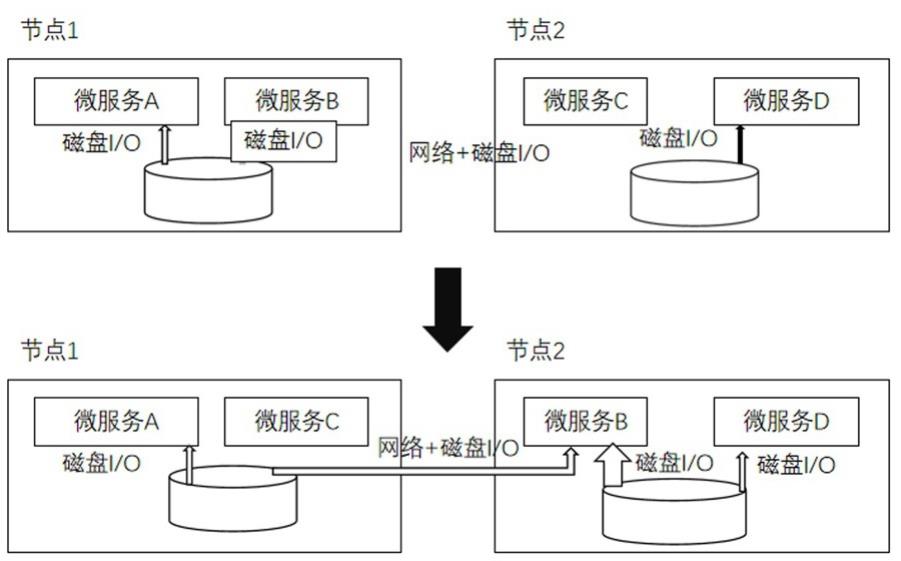
15.上述4条如果无法满足,则abletoexecute返回false,即无法正常执行,a与b无法进行聚合。图3给出了通过服务聚合降低跨计算节点间网络通信的例子,服务a,d聚合,服务b,c聚合。
16.在确定a和b可以聚合后,通过动态重构(重编译)将两个微服务整合为同一微服务,如图4所示。实现方式如下列表:语言类型分析与采样代码植入方式c/c 将二进制文件封装函数库并整合为兼顾a与b服务接口的微服务java将bytecode文件封装函数库并整合为兼顾a与b服务接口的微服务python将源代码文件进行重构整合为兼顾a与b服务接口的微服务对于a与b之间的交互,将a与b之间交互的接口实现复制为基于本机ip的服务接口,即a与b之间通过本机tcp接口进行通信,避免远程数据访问。
17.对于提供源代码的微服务,重构算法需要进行如下2步深度优化:1. 将a与b之间基于网络传输的远程过程调用的交互改为本机的进程间交互(ipc)或进程内交互(函数库调用);2. 如果a与b分别应用gpu加速设备,则将a与b所调用的gpu代码或机器学习模型同时载入gpu内存,并修改gpu计算代码的输入输出,使其直接在gpu内存中进行数据交互,避免在本机进行总线数据传输。
18.微服务调度、替换对于在整个云-边计算集群中运行的微服务,进行可聚合分析、重构与调度,算法流程表示如图5所示。
19.该算法将在集群中运行的所有微服务进行两两聚合,直到无法在找到可聚合的微服务。
20.在微服务a和b聚合后,需要确定新生产微服务ab的执行位置。可考虑如下策略:1. 在a与b的运行节点分别部署ab;2. 分别计算ab在a所在计算节点a
node
和b所在计算节点b
node
的运算成本,决定ab的部署位置。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。