一种基于人脸照片生成捏脸参数的方法与流程
- 国知局
- 2024-07-11 16:24:10
本发明涉及游戏中虚拟人物的塑造成像领域,具体涉及一种基于人脸照片生成捏脸参数的方法,基于该方法产生的捏脸参数能够直接利用目标捏脸系统的分区功能产生与真实人脸对应的捏脸图像。
背景技术:
1、对于捏脸系统,很多单机游戏均有配备,比如《gta5》,《上古卷轴5》,《赛博朋克2077》等单机大型游戏均配置了复杂的捏脸系统,但大部分单机游戏或者电脑端游戏并没有照片捏脸的功能。
2、随着手机性能的提高,很多手机游戏和软件配备有捏脸系统。而手机游戏也由于自身的互联网属性,使得用户可以方便地将图片上传至企业的服务平台,因此目前有一部分手机游戏配备了捏脸服务,例如《一梦江湖》,《天涯明月刀》,《花与剑》,《天谕》等。但受制于技术的复杂性以及部署的不便,大多数手机游戏并没有配备利用人脸照片直接捏脸的功能。目前的照片捏脸系统因为其部署需要的数据量大,灵活性较差,后期效果不便于调节和更改,且开发和迭代周期较长,故除了大型的手机游戏外,没有在产品中得到广泛使用。
3、目前已有的照片捏脸系统虽然该方案提供了一套将图片变为捏脸参数的流程,但是组成的模块较多,且转换器模块需要依赖面部识别模块和面部选区模块的完成,才可进行训练,耦合性高,提高了技术的使用难度。以shi,tianyang和网易伏羲实验室提出的“fast and robust face-to-parameter translation for game character auto-creation”[1]方案为例。该方案的整体思路为:
4、将用户输入的人脸图像转化为参数化的人脸,再通过训练好的转换器模块根据参数化人脸生成捏脸参数;其中转换器需要使用面部识别模块和面部选区模块的识别结果,所以在实现时需要先制作这两个模块才能开始训练转换器。
5、对于面部识别模块,文中采用了预先训练好的light cnn-29 v2模型,由于该网络事先进行过人脸识别领域的训练,可以将二维的人脸图像信息编码为向量表示的特征向量。文中将输入的图片输入light cnn-29 v2得到一个256维的特征向量,用处理后的该特征向量表示人脸。为了让照片捏脸的结果与输入图像在空间位置上更加相似,文中还添加了一个对输入的面部区域进行划分的面部选区模块。该模块是使用imagenet数据集对一个resnet-50神经网络架构进行预训练使其对图像有了初步的处理能力之后,将该神经网络模型的最后一层加以修改,再使用helen人脸数据集对其进行进一步的训练得到。helen人脸数据集中对人脸五官的不同区域做了划分,训练后的resnet-50神经网络架构具备对人脸的不同区域进行划分的能力。
6、完成上述训练后,输入特定人脸图片即可得到相应参数化人脸和人脸选区。转换器的功能是将参数化人脸转换成游戏内特定的捏脸参数。对于一个已知的参数化人脸,转换器产生的捏脸参数对用户来说不可知的(不对外输出)。转换器使用梯度下降算法进行训练,其需要一个度量方式(损失函数)来衡量生成的捏脸效果与原图的相似性,并将差异的梯度传递回转换器来引导其训练过程。而通常的游戏引擎不可微的,无法将捏脸效果的差异性直接回传至上一级的系统,所以文中训练了一个神经网络,作为捏脸效果模拟器,来模拟一个输入捏脸参数到捏脸效果图的过程,从而在训练中无需再使用游戏引擎,并可将梯度沿网络层逐层回传。若将参数化的人脸输入未训练的转换器可得到未调优的面部参数输出,将该参数放入一个捏脸效果模拟器得到对应的捏脸效果图,再将该图重新输入面部识别模块和面部选区模块即可得到一个新的参数化人脸和人脸选区。通过对比真实人脸,和根据参数生成的人脸之间人脸区域以及参数的不同,即可对生成结果进行评价,越相似时损失函数得出的结果应当越小。而由于捏脸效果模拟器是一个神经网络,所以可以通过梯度下降算法,将损失函数求得的梯度传递回转换器,对其进行训练。在运行时,需要将用户提供的面部图片,输入面部识别模块,得到256维的参数化人脸,再输入转换器变为捏脸参数。而面部选区模块以及捏脸效果模拟器,仅在训练时作为辅助组件使用。
7、从上述照片捏脸方案可知,虽然该方案提供了一套将图片变为捏脸参数的流程,但是组成的模块较多且各模块耦合程度高,转换器模块需要依赖面部识别模块和面部选区模块的完成才可进行训练,使用难度大。其次,由于面部识别模块使用的256维的面部特征向量对于使用者而言缺乏可解释性,无法对该向量进行拆分,转换器也只能将整体的参数化人脸转换捏脸参数,并且转换后的捏脸参数并不对外输出。导致用户很难针对指定五官的局部效果进行修改优化,比如当使用者对眼睛部分的效果感到不满意时,如果重新训练模型很可能会导致嘴巴,鼻子等其他无关的部位效果也发生更改,极大的提升了训练的不稳定性。面部特征种类的单一也使得诸如特征点之类的其他的特征提取方案在局部的表达效果更好时,无法被接纳进系统中来。另外,由于图片中面部五官特点的概率分布并不均匀增加了学习的复杂性,容易使部分数据量多的人脸风格在目前照片捏脸系统训练使起主导作用,而在样本覆盖少的情况人脸风格中效果不够显著。例如,圆脸多,尖脸少,小眼睛多,大眼睛少等。
技术实现思路
1、为了解决目前照片捏脸系统只能对整张参数化的人脸转换捏脸参数且不对外输出捏脸参数,导致难以单独对某一捏脸区域进行调整而不影响其他捏脸区域的捏脸效果,而在训练相关预测器时由于图片中面部五官特点的概率分布并不均匀增加机器学习复杂性的技术问题。本发明提供一种基于人脸照片生成捏脸参数的方法。通过该方法分捏脸区域单独设置相应的子预测器,相关的子预测器用于预测单一捏脸区域的捏脸参数以便单独针对某一捏脸区域的捏脸效果进行调整。
2、本发明提供的技术方案实现为一种基于人脸照片生成捏脸参数的方法,该方法包括以下步骤:
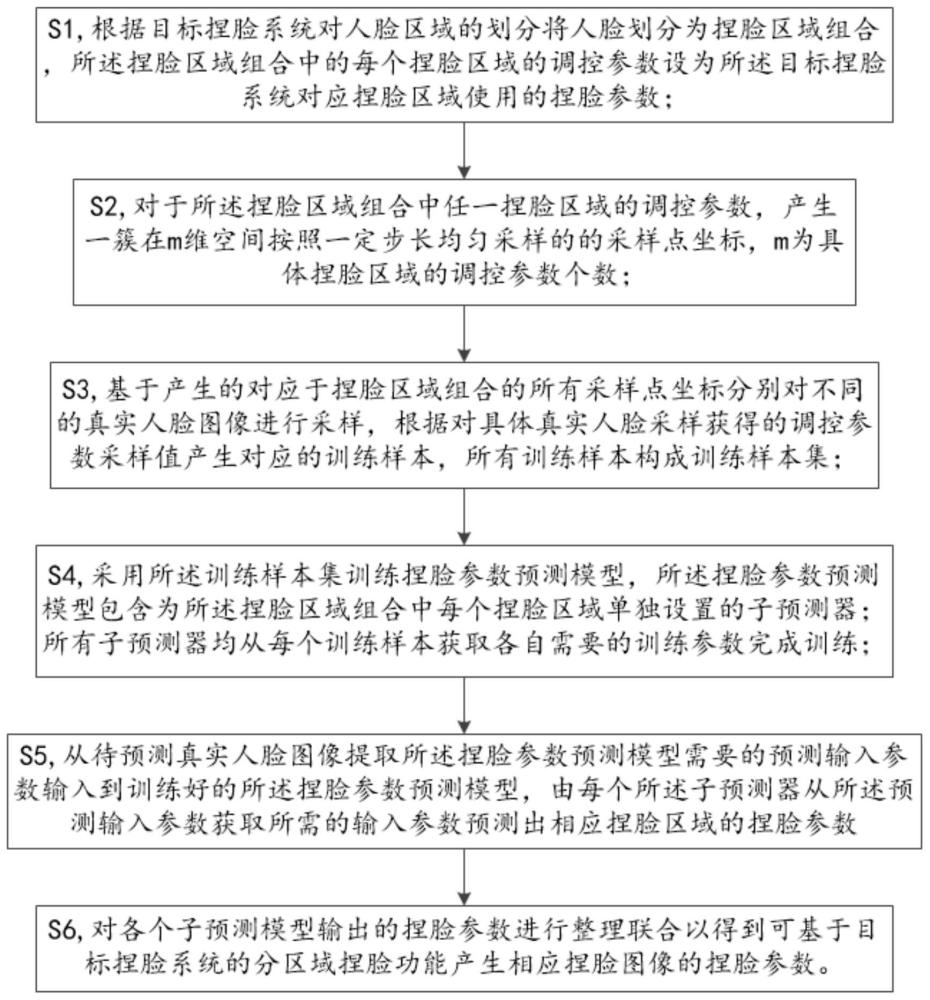
3、s1,根据目标捏脸系统对人脸区域的划分将人脸划分为捏脸区域组合,所述捏脸区域组合中的每个捏脸区域的调控参数设为所述目标捏脸系统对应捏脸区域使用的捏脸参数;
4、s2,对于所述捏脸区域组合中任一捏脸区域的调控参数,产生一簇在m维空间按照一定步长均匀采样的的采样点坐标,m为具体捏脸区域的调控参数个数;
5、s3,基于步骤s2产生的对应于所述捏脸区域组合的所有采样点坐标分别对不同的真实人脸图像进行采样,并根据对具体真实人脸采样获得的调控参数采样值产生对应的训练样本,所有训练样本构成训练样本集;
6、s4,采用所述训练样本集训练捏脸参数预测模型,所述捏脸参数预测模型包含为所述捏脸区域组合中每个捏脸区域单独设置的子预测器;所有子预测器均从每个训练样本获取各自需要的训练参数完成训练;所述子预测器输出参数的个数与其对应捏脸区域的调控参数的个数相同,输入参数为其对应的捏脸区域的特征或特征组合;
7、s5,从待预测真实人脸图像提取所述捏脸参数预测模型需要的预测输入参数输入到训练好的所述捏脸参数预测模型,由每个所述子预测器从所述预测输入参数获取所需的输入参数预测出相应捏脸区域的捏脸参数;
8、s6,根据目标捏脸系统提供的捏脸参数输入接口中各捏脸区域对应的捏脸参数的组织顺序,整理联合各子预测模型输出的捏脸参数得到可输入到目标捏脸系统产生相应捏脸图像的捏脸参数。
9、进一步地,上述步骤s2具体实现为:确定具体捏脸区域的样本维度m,采样阶数n以及所需要的采样点数s;按照所述n个连续自然数的大小顺序,依次将所述n个连续自然数一对一地转换成在m维空间中均匀分布的采样点坐标并按照产生顺序赋予序号记录在坐标列表cl中,n=2m*n且n>s;然后,对所述n个坐标进行均匀插值以获得s个在m维空间均匀分布的采样点坐标。
10、进一步地,所述按照所述n个连续自然数的大小顺序,依次将所述n个连续自然数一对一地转换成m维空间中对应的采样点坐标,具体实现为:按照所述n个连续自然数的大小顺序,依次将n个自然数中的一个转换成一个n位的二进制数据x,将该n位二进制数据以m位为间隔进行按从高位到低位的顺序进行截断得到n组二进制数,其中n为迭代次数,m为数据维度;按截断顺序基于所述n组二进制数,根据预设的转换方法产生m位采样空间一个采样点的一个对应维度的分量,按照转换前每一组二进制数的顺序组织转换后每个采样点的维度分量得到一个的采样点坐标;所述预设的转换方法包括以下步骤:
11、a,设x[i]表示当前n位二进制数x截断所得的第i份二进制数,;计算x[i]标识位置p[i]:设b[i]中最后一位二进制数为b[i][-1],p[i]的取值为b[i]中最后一个与b[i][-1]值不相等的位在b[i]中的序号;
12、b,设m位二进制数c[i],c[i]中的第j位数字为c[i][j],其值通过以下计算方式得到:c[i][j]=b[i][j]⊕b[i][j-1],;并且当j=1时,c[i][1]=b[i][1],⊕表示异或运算;
13、c,设置m位进制数d[i],令d[i][j]=c[i][j]后将d[i][m]取反;统计在d[i]中“1”的个数,若为奇数,将d[i,p[i]]的值取反,若为偶数,则不作处理;
14、d,计算偏移值r[i],r[i]=(p[1]–1)+…+(p[i–1]–1),r[1]=0,将二进制数c[i]循环右移r[i]位得到c[i],将二进制数d[i]循环右移r[i]位进得到d[i];
15、e,分别设m位二进制数e[i]、f[i],当时,e[i]=e[i-1]⊕d[i-1];当i=1时,e[1]为n个全为0的二进制数,计算f[i]:f[i]=e[i]⊕c[i];
16、f,设n行m列的矩阵g,矩阵的第i行g[i]=f[i];将矩阵g转置后得到g_t;
17、g,设m维空间点坐标h,h[i]为h第i维度的分量,h[i]为将g_t的第i行二进制数g_t[i]转换为十进制后的结果。
18、进一步地,对所述n个坐标进行均匀插值以获得s个在m维空间均匀分布的采样点坐标,具体实现为:计算所需的样本数量s和总共的坐标数量n的比值step;从0开始,遍历坐标列表cl所有的采样点坐标,记录当前遍历的采样点坐标序号为p,每一次遍历,采样点坐标序号p都会加上step后得到px,将px向上取整得到p1,向下取整得到p0,px的小数部分为r,计算得到两个混合权重:r0=r,r1=1-r;对应于采样点坐标序号为p得到插值后的采样点坐标为pin:
19、pin=coords[p0]*r0+coords[p1]*r1;
20、coords[p0]表示坐标列表cl中坐标序号为p0对应的采样点坐标值,coords[p1]表示坐标列表cl中坐标序号为p1对应的采样点坐标值,coords[p0]*r0和coords[p1]*r1两者之间相加,表示相同坐标空间维度的分量分别相加。
21、进一步地,所述步骤s3中根据对具体真实人脸采样获得的调控参数采样值产生对应的训练样本,具体实现为:基于步骤s2产生的所述捏脸区域组合中各捏脸区域对应的一簇采样点坐标对同一张真实人脸图像进行采样得到各捏脸区域对应的一簇调控参数采样值。根据采样值的取值范围和目标捏脸系统中对应参数取值范围之间的映射关系,将采样得到调控参数采样值映射成目标捏脸系统对应捏脸参数的取值范围内的调控参数采样值。将映射后得到的各捏脸区域对应的调控参数采样值遍历组合,产生对应所述捏脸区域组合的捏脸参数采样值组合集合。将捏脸参数采样值组合集合中的每一个捏脸参数采样值组合输入到目标捏脸系统以产生对应的捏脸图像。分别基于预先训练好的面部特征提取模块提取该捏脸图像对应的特征点和特征向量;将每个捏脸参数采样值组合,及其对应的捏脸图像、特征点以及特征向量按照特定捏脸区域排序组成四元组<捏脸图像,特征向量,特征点,捏脸参数采样值组合>作为一个训练样本。所有子预测器均从每个训练样本的捏脸图像、特征向量和特征点这三部分分别获取各自训练阶段的输入参数。
22、所述分别基于预先训练好的面部特征提取模块提取该捏脸图像对应的特征点和特征向量,具体实现为:用预先训练好的facenet网络从所述捏脸图像提取k1维的特征向量,再用预先训练好的dlib特征点标注器从所述捏脸图像提取k2个特征点;k1=128,k2=68。相应地,步骤s5中从待预测真实人脸图像提取所述捏脸参数预测模型需要的预测输入参数,实现为:用所述预先训练好的facenet网络从所述待预测真实人脸图像提取k1维的特征向量,用所述预先训练好的dlib特征点标注器从该待预测真实人脸图像提取k2个特征点;将所述真实人脸图像、对应提取的k1维的特征向量和k2个特征点作为捏脸预测模型的预测输入参数。
23、进一步地,所述步骤s6中对各个子预测模型输出的捏脸参数进行整理联合以得到所述待预测真实人脸的捏脸参数,包括:设置的捏脸区域之间相对位置的约束模型,基于该约束模型和选定具体捏脸区域对应的子预测器的输出参数,对另一部分捏脸区域对应的子预测器的输出参数进行修调。
24、与上述方法相对应,本发明还提供一种计算机可读存储介质。所述计算机可读存储介质上存储有程序代码,所述程序代码在被处理器执行时,实现上述的基于人脸照片生成捏脸参数的方法。
25、本发明提供的基于人脸照片生成捏脸参数的方法,克服了训练相关预测器时由于人脸图片中面部五官特点的概率分布并不均匀增加机器学习复杂性的技术问题。通过该方法能够生成具有分区捏脸功能的目标捏脸系统对应的捏脸参数并对用户输出,并且产生的捏脸参数按照捏脸区域有序组织,对于用户来说可解析性强,便于单独针对某一捏脸区域的捏脸效果进行调整。
本文地址:https://www.jishuxx.com/zhuanli/20240615/79106.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表