用于语音处理的模型训练方法、设备、介质及程序产品与流程
- 国知局
- 2024-06-21 10:38:22
本技术涉及人工智能,特别涉及一种用于语音处理的模型训练方法、设备、介质及程序产品。
背景技术:
1、随着人工智能ai技术的不断发展,目前很多应用提供基于ai的音色转换功能,具体来说,就是将一个用户的语音,通过语音处理模型转换成某个特定的对象发出的语音。
2、在相关技术中,上述语音处理模型可以包含语音内容编码器、说话人编码器以及一个解码器;在训练过程中,将语音样本分别输入语音内容编码器和说话人编码器,得到语音内容编码器输出的语音内容的表示,以及说话人编码器输出的音色的表示,然后,通过解码器对上述语音内容的表示和音色的表示进行解码处理,得到合成语音,再根据合成语音和语音样本之间的差异对语音处理模型进行参数更新。
技术实现思路
1、本技术实施例提供了一种用于语音处理的模型训练方法、设备、介质及程序产品,能够提高用于进行音色转换的语音处理模型的准确性。所述技术方案如下:
2、一方面,提供了一种用于语音处理的模型训练方法,所述方法包括:
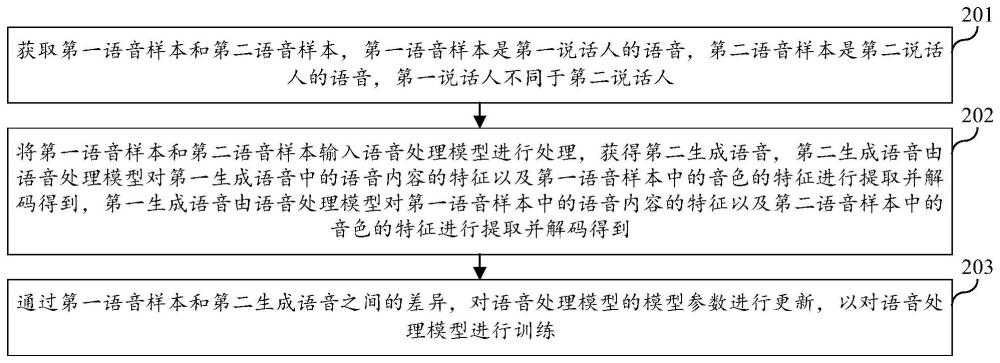
3、获取第一语音样本和第二语音样本,所述第一语音样本是第一说话人的语音,所述第二语音样本是第二说话人的语音,所述第一说话人不同于所述第二说话人;
4、将所述第一语音样本和所述第二语音样本输入语音处理模型进行处理,获得第二生成语音;所述第二生成语音由所述语音处理模型对第一生成语音中的语音内容的特征以及所述第一语音样本中的音色的特征进行提取并解码得到;所述第一生成语音由所述语音处理模型对所述第一语音样本中的语音内容的特征以及所述第二语音样本中的音色的特征进行提取并解码得到;
5、通过所述第一语音样本和所述第二生成语音之间的差异,对所述语音处理模型的模型参数进行更新,以对所述语音处理模型进行训练;
6、其中,在所述模型参数训练至收敛的情况下,所述语音处理模型用于将一个说话人的语音转换为具有相同语音内容的另一个说话人的语音。
7、一方面,提供了一种用于语音处理的模型训练装置,所述装置包括:
8、样本获取模块,用于获取第一语音样本和第二语音样本,所述第一语音样本是第一说话人的语音,所述第二语音样本是第二说话人的语音,所述第一说话人不同于所述第二说话人;
9、模型处理模块,用于将所述第一语音样本和所述第二语音样本输入语音处理模型进行处理,获得第二生成语音;所述第二生成语音由所述语音处理模型对第一生成语音中的语音内容的特征以及所述第一语音样本中的音色的特征进行提取并解码得到;所述第一生成语音由所述语音处理模型对所述第一语音样本中的语音内容的特征以及所述第二语音样本中的音色的特征进行提取并解码得到;
10、更新模块,用于通过所述第一语音样本和所述第二生成语音之间的差异,对所述语音处理模型的模型参数进行更新,以对所述语音处理模型进行训练;
11、其中,在所述模型参数训练至收敛的情况下,所述语音处理模型用于将一个说话人的语音转换为具有相同语音内容的另一个说话人的语音。
12、在所记载的实施例中,本技术可能被设置为,所述语音处理模型包括语音内容编码器、说话人编码器以及解码器;
13、所述模型处理模块,用于,
14、通过所述语音内容编码器对所述第一语音样本进行编码,获得第一内容表示,所述第一内容表示是用于表征所述第一语音样本中的语音内容的特征;
15、通过所述说话人编码器对所述第一语音样本进行编码,获得第一说话人表示,所述第一说话人表示是用于表征所述第一语音样本中的音色的特征;
16、通过所述说话人编码器对所述第二语音样本进行编码,获得第二说话人表示,所述第二说话人表示是用于表征所述第二语音样本中的音色的特征;
17、通过所述解码器对所述第一内容表示和所述第二说话人表示进行解码处理,获得所述第一生成语音;
18、通过所述语音内容编码器对所述第一生成语音进行编码,获得第二内容表示;所述第二内容表示是用于表征所述第一生成语音中的语音内容的特征;
19、通过所述解码器对所述第二内容表示和所述第一说话人表示进行解码处理,获得所述第二生成语音。
20、在所记载的实施例中,本技术可能被设置为,所述更新模块,用于,
21、获取所述第一语音样本和所述第二生成语音之间的第一语音差值;
22、通过第一函数对所述第一语音差值进行处理,获得第一损失函数值;
23、通过所述第一损失函数值对所述语音处理模型的模型参数进行更新,以对所述语音处理模型进行训练。
24、在所记载的实施例中,本技术可能被设置为,所述第一函数用于计算所述第一语音差值的2范数。
25、在所记载的实施例中,本技术可能被设置为,所述更新模块,还用于,
26、获取感知损失函数值,所述感知损失函数值包括第二损失函数值和第三损失函数值中的至少一项,所述第二损失函数值指示所述第二语音样本和所述第一生成语音的音色之间的差异,所述第三损失函数值指示所述第二语音样本和所述第一生成语音的语音内容之间的差异;
27、通过所述感知损失函数值对所述语音处理模型的模型参数进行更新,以对所述语音处理模型进行训练。
28、在所记载的实施例中,本技术可能被设置为,所述更新模块,用于在所述感知损失函数值包括第二损失函数值的情况下,
29、通过所述说话人编码器对所述第一生成语音进行编码处理,获得第三说话人表示,所述第三说话人表示是用于表征所述第一生成语音中的音色的特征;
30、获取所述第二说话人表示与所述第三说话人表示之间的说话人表示差值;
31、通过第二函数对所述说话人表示差值进行处理,获得所述第二损失函数值。
32、在所记载的实施例中,本技术可能被设置为,所述更新模块,用于在所述感知损失函数值包括第三损失函数值的情况下,
33、获取所述第一内容表示与所述第二内容表示之间的内容表示差值;
34、通过第三函数对所述内容表示差值进行处理,获得所述第三损失函数值。
35、在所记载的实施例中,本技术可能被设置为,所述更新模块,还用于,
36、获取语音样本对,以及所述语音样本对的标注信息,所述语音样本对包含第三语音样本和第四语音样本,所述标注信息用于指示所述第三语音样本和所述第四语音样本是否是同一个说话人的语音;
37、通过所述说话人编码器对所述第三语音样本进行编码处理,获得第四说话人表示,所述第四说话人表示是用于表征所述第三语音样本中的音色的特征;
38、通过所述说话人编码器对所述第四语音样本进行编码处理,获得第五说话人表示,所述第五说话人表示是用于表征所述第四语音样本中的音色的特征;
39、通过第四函数对所述第四说话人表示、所述第五说话人表示以及所述标注信息进行处理,获得第四损失函数值;
40、通过所述第四损失函数值对所述语音处理模型的模型参数进行更新,以对所述语音处理模型进行训练。
41、在所记载的实施例中,本技术可能被设置为,所述第四函数包括第一函数项和第二函数项,所述第一函数项用于计算所述第四说话人表示的停止梯度操作的操作结果与所述第五说话人表示之间的差值,所述第二函数项用于计算所述第五说话人表示的停止梯度操作的操作结果与所述第四说话人表示之间的差值。
42、在所记载的实施例中,本技术可能被设置为,所述第四函数用于通过所述第四说话人表示和所述第五说话人表示之间的差值,计算得到所述第四损失函数值。
43、在所记载的实施例中,本技术可能被设置为,所述第二说话人包含两个或者两个以上的说话人,所述第三语音样本和所述第四语音样本各自的说话人,是所述两个或者两个以上的说话人中的同一个说话人,或者,所述第三语音样本和所述第四语音样本各自的说话人,是所述两个或者两个以上的说话人中的不同的说话人。
44、在所记载的实施例中,本技术可能被设置为,所述更新模块,还用于,
45、通过所述解码器对所述第一内容表示和所述第一说话人表示进行解码处理,获得第三生成语音;
46、获取所述第一语音样本和所述第三生成语音之间的第二语音差值;
47、通过第五函数对所述第二语音差值进行处理,获得第五损失函数值;
48、通过所述第五损失函数值对所述语音处理模型的模型参数进行更新,以对所述语音处理模型进行训练。
49、另一方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如上述本技术实施例所述的用于语音处理的模型训练方法。
50、另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现如上述本技术实施例所述的用于语音处理的模型训练方法。
51、另一方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述实施例所述的用于语音处理的模型训练方法。
52、本技术实施例提供的技术方案带来的有益效果至少包括:
53、获取对应不同说话人的第一语音样本和第二语音样本,先通过语音处理模型对第一语音样本中的语音内容的特征以及第二语音样本中的音色的特征进行提取并解码得到第一生成语音,然后再通过语音处理模型对第一生成语音中的语音内容的特征以及第一语音样本中的音色的特征进行提取并解码得到第二生成语音,再通过第二生成语音与第一语音样本之间的差异进行模型的参数更新,在上述训练过程中,通过语音处理模型合成语音时,解码使用的语音内容的特征和音色特征分别来自不同的说话人的语音样本,而在上述语音处理模型的推理过程中,解码使用的语音内容的特征和音色的特征也分别来自于不同的说话人的语音,因此,能够使得模型的推理过程和训练过程保持一致,从而提高语音处理模型的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/20854.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。