一种临高话和普通话混合语音识别模型训练方法及系统
- 国知局
- 2024-06-21 10:39:26
本发明涉及语音识别,特别涉及一种临高话和普通话混合语音识别模型训练方法及系统。
背景技术:
1、汉语方言不仅代表着一种文字符号,更承载着深厚的中华文化。方言也具有浓郁的地域文化色彩和社会风土人情。当今,弱势方言正面临着全球化冲击,正处于逐渐消失的危险之中。因此,针对构成方言保护核心环节的方言语音识别研究具有重要的现实意义。
2、语音识别技术的核心目标是将声音转换为文字,使用户与机器进行语音交流时可以让机器能够明白你在说什么。大数据时代来临产生了海量的语音数据,极大地推动了语音识别技术的发展。传统语音识别技术以高斯混合模型和隐马尔可夫模型为代表,但由于高斯混合模型没有利用帧的上下文信息,不能学习深层非线性特征变换,求解算法容易陷入局部极值等,其实际识别效果并不理想。
3、随着技术的进步,传统的语音识别模型已经不能满足人们日益增长的需求,由于深度学习技术在处理大量数据时有着更明显的优势,因此科研人员将其应用到语音识别领域中来,使得语音识别技术有了突飞猛进的发展,语音识别的准确率达到了更高的水平。随着端到端语音识别技术的不断发展,大大减少了语音识别模型结构的复杂度,使整个识别过程整合到一个网络中,直接将输入的音频映射到文本序列。但为了提升语音识别模型识别准确率,神经网络层数不断增多,网络结构越来越复杂。这将导致模型参数量过大,计算复杂度高,模型识别的延迟率较高,难以满足实际应用需要。
技术实现思路
1、本发明提供了一种临高话和普通话混合语音识别模型训练方法及系统,采用预设编码器和ctc wfst search解码器的模型结构,增强了模型提取局部细微特征的能力,提升了模型的语言建模能力,提高了模型识别的准确率。
2、本发明提供了一种临高话和普通话混合语音识别模型训练方法,基于conformer模型构建的端到端混合语音识别模型,所述端到端混合语音识别模型为编码器-解码器结构,所述编码器由预设编码器构成,预设编码器包含多个相同的conformer模块;所述解码器采用由ctc解码器和n-gram语言模型所构成的ctc wfst search解码器,n-gram语言模型表示为加权有限状态转换器的形式;所述端到端混合语音识别模型的训练方法包括:
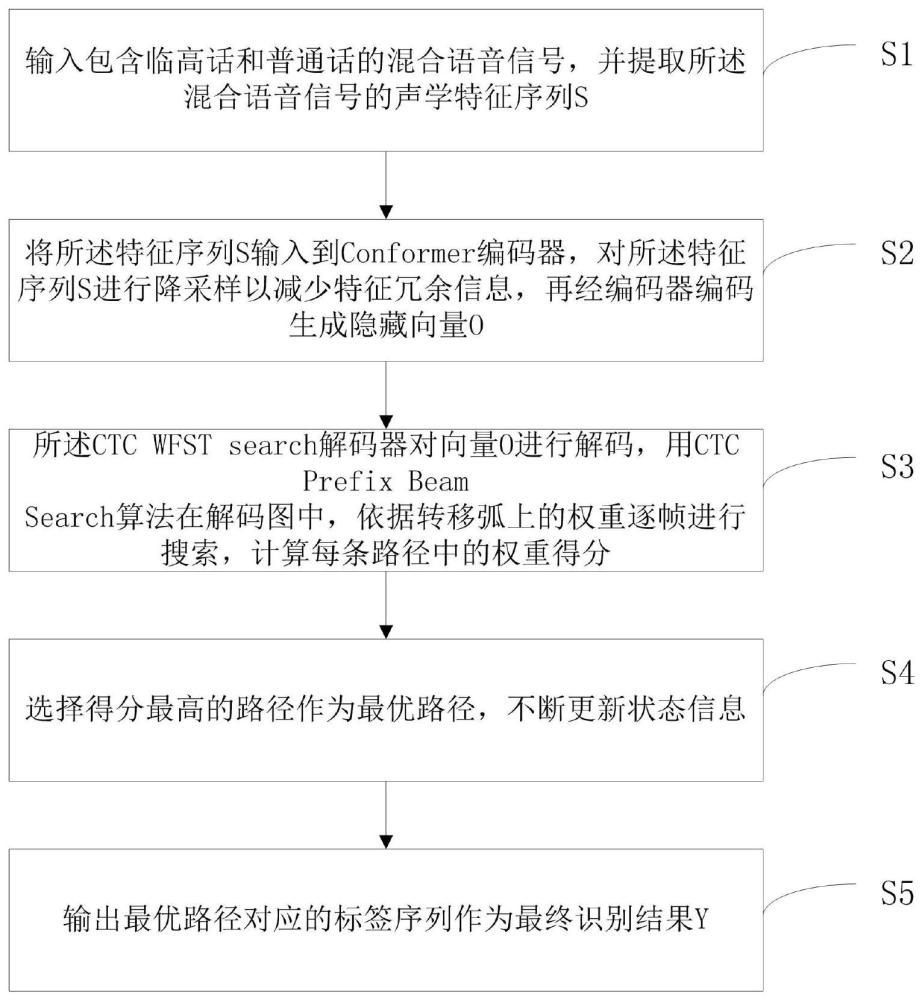
3、输入包含临高话和普通话的混合语音信号,并提取所述混合语音信号的声学特征序列s;
4、将所述特征序列s输入到预设编码器,对所述特征序列s进行降采样以减少特征冗余信息,再经编码器编码生成隐藏向量o;
5、所述ctc wfst search解码器对向量o进行解码,用ctc prefix beam search算法在解码图中,依据转移弧上的权重逐帧进行搜索,计算每条路径中的权重得分;
6、选择得分最高的路径作为最优路径,不断更新状态信息;
7、输出最优路径对应的标签序列作为最终识别结果y。
8、进一步地,所述预设编码器包括语音增强模块、卷积降采样模块、线性层和conformer模块;所述conformer模块包括前馈神经网络模块,多头注意力模块以及卷积模块,卷积模块和多头注意力模块被两个半步前馈神经网络模块夹在中间,在前馈神经网络模块、卷积模块和多头注意力模块上均使用了残差结构;
9、在所述预设编码器中,用xn表示第n个conformer模块的输入,yn表示其对应的输出,conformer模块的计算过程为:
10、
11、xmha=xf1+mha(xf1)
12、xconv=xmha+conv(xmha)
13、
14、其中,ffn表示前馈神经网络模块的计算函数,mha表示多头注意力模块的计算函数,conv表示卷积模块计算函数,layernorm表示归一化函数。
15、进一步地,所述卷积模块由swish激活、glu激活层、pointwise卷积、depthwise卷积、batch norm和归一化层组成;glu激活函数决定哪些信息可以被传送到下个模块,其公式为:
16、
17、其中,x表示输入,w和v分别代表不同的卷积核,b和c分别作为偏移量;
18、归一化层对信息进行整合,重新定位并优化网络参数,通过动态调整输入向量的长短避免输入分布差异,线性层将神经网络中每层的神经元与上一层神经元相连,实现线性变换操作。
19、进一步地,所述前馈神经网络模块由两个内部线性层组成,并采用swish激活函数进行线性变换,同时采用dropout减少过拟合问题;
20、所述前馈神经网络用于更新注意力层输出向量的每个状态信息,其公式为:
21、ffn(x)=max(0,xw1+b1)w2+b2
22、其中,w表示权重,b表示偏差,x表示输入。
23、进一步地,所述ctc wfst search解码器在解码时包含构建解码图和解码两个操作;
24、所述解码图的构建将t、l和g每个部分的信息组合在一起,其中建模单元用t表示,词典用l表示,语言模型用g表示;用中文汉字作为端到端混合语音识别模型中的建模单元t,由词语或者句子拆分成建模单元组合成词典l,将n-gram语言模型转换成wfst的表示形式构成g,其中wfst为普遍应用于语音识别领域的解码形式,可以将n-gram语言模型表示成图的形式。
25、进一步地,还包括多头注意力解码器,所述预设编码器的输出与ctc解码器和多头注意力解码器相连,所述多头注意力解码器由多个transformer结构的解码器组成,其中包含多头注意力层和屏蔽多头注意力层。
26、进一步地,所述多头注意力解码器按照自回归的方式进行解码,上一时刻解码器输出的标签经过输出嵌入层和位置编码后输入到屏蔽多头注意力层,并生成对应的q、k和v的值;多头注意力层的输入一部分为编码器的输出k向量和v向量,另一部分为屏蔽多头注意力层的输出q向量;最后经过softmax层输出完整的识别结果;
27、多头注意力解码器中的位置编码采用不同频率的正弦和余弦函数,其公式为:
28、
29、
30、其中,pos是指单词在这个句子中的位置,i表示嵌入词向量的维度,2i表示偶数维度,2i+1表示奇数维度,位置编码的每一维对应一个正弦信号,对应的波长以几何级数的形式从2π增长到10000·2π。
31、本发明还提供了一种临高话和普通话混合语音识别模型训练系统,基于conformer模型构建的端到端混合语音识别模型,所述端到端混合语音识别模型为编码器一解码器结构,所述编码器由预设编码器构成,预设编码器包含多个相同的conformer模块;所述解码器采用由ctc解码器和n-gram语言模型所构成的ctc wfst search解码器,n-gram语言模型表示为加权有限状态转换器的形式;所述端到端混合语音识别模型的训练系统包括:
32、输入模块,用于输入包含临高话和普通话的混合语音信号,并提取所述混合语音信号的声学特征序列s;
33、编码模块,用于将所述特征序列s输入到预设编码器,对所述特征序列s进行降采样以减少特征冗余信息,再经编码器编码生成隐藏向量o;
34、解码模块,用于所述ctc wfst search解码器对向量o进行解码,用ctc prefixbeam search算法在解码图中,依据转移弧上的权重逐帧进行搜索,计算每条路径中的权重得分;
35、选择模块,用于选择得分最高的路径作为最优路径,不断更新状态信息;
36、输出模块,用于输出最优路径对应的标签序列作为最终识别结果y。
37、本发明还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
38、本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。
39、本发明的有益效果为:
40、1、本发明结合conformer模型与n-gram语言模型,提出采用预设编码器和ctcwfstsearch解码器的模型结构,ctc wfst search解码器由n-gram语言模型与ctc解码器构成。不仅增强了模型提取局部细微特征的能力,还提升了模型的语言建模能力,进一步提高模型识别的准确率。采用数据增强的方法降低语料数据不足带来的影响,增强了模型的鲁棒性。
41、2、基于conformer模型使用ctc和多头注意力机制联合解码,提出基于预设编码器使用ctc解码器和多头注意力解码器联合解码的方法,将两个解码器部分输出结果对应的概率加权求和,以概率最高的结果作为最终的模型输出。与n-gram语言模型相结合,进一步提升了模型的识别准确率。
本文地址:https://www.jishuxx.com/zhuanli/20240618/20989.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表