自动确定通过自动化助理接口接收的口头话语的语音识别的语言的制作方法
- 国知局
- 2024-06-21 10:40:11
本技术大体上涉及自动确定通过自动化助理接口接收的口头话语的语音识别的语言。
背景技术:
1、人类可以与交互式软件应用进行人机对话,该交互式软件应用在此称为“自动化助理”(也称为“数字代理”、“聊天机器人”、“交互式个人助理”、“智能个人助理”、“助理应用”、“会话代理”等)。例如,人类(当他们与自动化助理交互时,可以被称为“用户”)可以使用口头自然语言输入(即,话语)向自动化助理提供命令和/或请求,在某些情况下该口头自然语言输入可以被转换成文本然后被处理,和/或通过提供文本(例如,键入的)自然语言输入向自动化助理提供命令和/或请求。自动化助理通过提供响应用户接口输出来响应于请求,该用户接口输出可以包括可听和/或视觉用户接口输出。
2、如上所述,自动化助理可以将对应于用户口头话语的音频数据转换成对应的文本(或其他语义表示)。例如,音频数据可以基于通过客户端设备的一个或多个麦克风的对用户的口头话语的检测来生成,该客户端设备包括用于使用户能够与自动化助理交互的助理接口。自动化助理可以包括语音识别引擎,其试图识别音频数据中捕获的口头话语的各种特征,诸如口头话语产生的声音(例如音素)、产生的声音的顺序、语音节奏、语调等。此外,语音识别引擎可以标识由这些特性表示的文本词或短语。然后,在确定口头话语的响应内容时,文本可以由自动化助理(例如,使用自然语言理解(nlu)引擎和/或对话状态引擎)进一步处理。语音识别引擎可以由客户端设备和/或远离客户端设备但与客户端设备进行网络通信的一个或多个自动化助理组件来实现。
3、然而,许多语音识别引擎被配置为识别仅单个语言的语音。对于多语言用户和/或家庭来说,这种单个语言语音识别引擎可能不令人满意,并且当接收到不是语音识别引擎支持的单个语言的附加语言的口头话语时,这种单个语言语音识别引擎可使自动化助理故障和/或提供错误的输出。这可以渲染不可使用的自动化助理和/或导致计算和/或网络资源的过度使用。当自动化助理故障或提供错误输出时,计算和/或网络资源的过度使用可能是用户需要提供进一步的所支持的单个语言的口头话语的结果。这种进一步的口头话语必须另外由对应的客户端设备和/或远程自动化助理组件处理,从而导致各种资源的附加使用。
4、其他语音识别引擎可以被配置为识别多个语言的语音,但是需要用户明确指明在给定时间应该在语音识别中使用多个语言中的哪一个。例如,其他语音识别引擎中的一些可能需要用户手动指明要被用于在特定客户端设备接收的所有口头话语的语音识别中的默认语言。要将默认语言更改为另一个语言,可以要求用户与图形和/或可听接口交互,以明确更改默认语言。这种交互会在渲染接口、处理通过接口提供的用户输入等时导致过度使用计算和/或网络资源。此外,在提供不是当前默认语言的口头话语之前,用户可能经常忘记改变默认语言。如上所述,这可能导致渲染不可使用的自动化助理和/或导致计算和/或网络资源的过度使用。
技术实现思路
1、本文描述的实施方式涉及用于自动确定通过自动化助理接口接收的口头话语的语音识别的语言的系统、方法和装置。在一些实施方式中,使用给定语言的口头话语的语音识别可以包括处理捕获口头话语的音频数据,使用给定语言的一个或多个语音识别模型以便生成对应于口头话语并且使用给定语言的文本。如本文所述,多个语音识别模型可用于语音识别,并且语音识别模型中的每个可被配置以用于多个语言中的对应语言。例如,第一语音识别模型可以被配置为基于处理包括英语口头话语的音频数据来生成英语文本、第二语音识别模型可以被配置为基于处理包括法语口头话语的音频数据来生成法语文本、第三语音识别模型可以被配置为基于处理包括西班牙语口头话语的音频数据来生成西班牙语文本等。
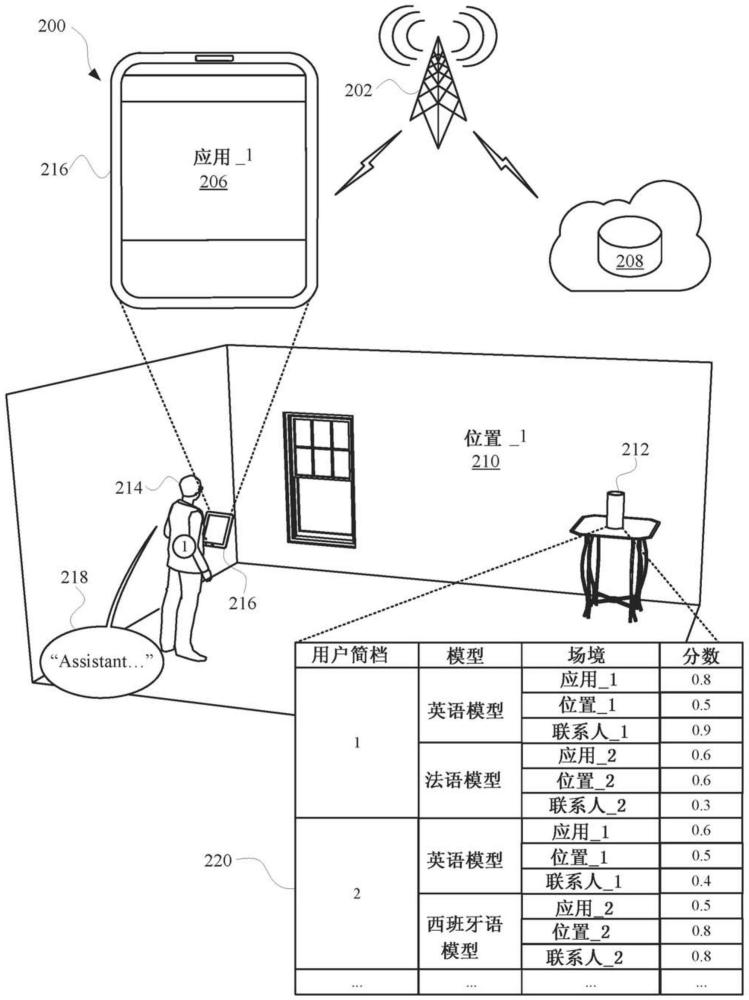
2、本文描述的一些实施方式可以利用各种技术来仅选择一个语言子集,以用于给定用户的给定口头话语的语音识别。例如,给定用户可以具有用户简档,该用户简档具有被指派给用户简档的多个候选语言。多个候选语言可以由用户手动指派给用户简档和/或基于用户跨一个或多个平台上对候选语言的过去使用被自动指派。如下文更详细描述的,仅选择该语言子集可以基于例如被指派给用户简档的多个候选语言的概率度量,该概率度量可以基于用户简档的多个候选语言的过去使用,并且每个该概率度量可以对应于一个或多个场境参数(例如,给定场境参数,每个基于用户简档的对应语言的过去使用)。
3、作为一个特定示例,被指派给用户简档的多个语言中的单个特定语言可以针对一个或多个当前场境参数(例如,通过其检测给定口头话语的客户端设备、一天中的时间和/或一周中的一天)具有被指派的概率度量,其中概率度量指示给定用户说出该单个特定语言的非常高的可能性。基于被指派的概率度量,可以选择单个特定语言,并且仅使用该单个语言的语音识别模型来执行语音识别。执行语音识别可以产生单个语言的对应文本,然后在生成响应于给定口头话语的内容时,该文本可以由自动化助理的附加组件进一步处理。然后,响应的内容可以被提供用于在客户端设备处渲染以呈现给用户。响应的内容可以可选地使用相同的单个语言,或者被提供以使以相同的单个语言渲染。
4、作为另一个特定示例,被指派给用户简档的三个或更多个候选语言中的两个特定语言可以针对一个或多个当前场境参数具有对应的被指派的概率度量,其中每个概率度量至少指示给定用户说出两个特定语言中的对应一个语言的阈值可能性。基于被指派的概率度量,两个特定语言可以被选择,并且只使用这两个特定语言的语音识别模型来执行给定口头话语的语音识别。基于针对一个或多个当前场境参数,其他候选语言的对应的被指派的度量不满足阈值,该其他候选语言可能不被选择用于语音识别。
5、使用该两个特定语言中的第一语言的语音识别模型来执行语音识别可以产生第一语言的相应第一文本以及可选地指示第一文本表示给定口头话语的可能性的第一测量。使用该两个特定语言中的第二语言的语音识别模型执行语音识别可以产生第二语言的相应的第二文本以及且可选地指示第二文本表示给定口头话语的可能性的第二测量。然后,可以选择第一文本或第二文本中的一个作为适当的文本,用于生成和提供响应于给定口头话语的内容。
6、在一些实施方式中,基于第一和第二测量选择第一文本或第二文本中的一个,第一和第二测量指示它们表示给定口头话语的相应可能性。例如,如果第一测量指示第一文本表示给定口头话语的80%的可能性,并且第二测量指示第二文本表示给定口头话语的70%的可能性,则鉴于第一测量指示比第二测量更大的可能性,可以选择第一文本来代替第二文本。在那些实施方式中的一些中,可以进一步考虑两个特定语言的概率度量。例如,再次假设第一测量指示80%的可能性,第二测量指示70%的可能性,并且进一步假设第一语言的概率度量是30%(针对一个或多个场境参数),第二语言的概率度量是65%(针对一个或多个场境参数)。在这样的示例中,可以基于指示第一和第二文本表示给定口头话语的可能性的测量以及第一和第二语言的概率度量两者来选择第二文本代替第一文本。例如,第一文本的分数可以基于70%和65%(例如,基于0.7*0.65的0.455的分数),第二文本的分数可以基于80%和30%(例如,基于0.8*0.3的0.24的分数),并且第一文本基于具有更高的分数而被选择。
7、这些和其他仅选择用户的候选语言子集以用于用户的口头话语的语音识别的实施方式可以节省各种设备资源(例如,执行语音识别的客户端设备和/或远程自动化助理组件),因为只有对应于语言子集的语音识别模型被用于执行语音识别。此外,利用语言的概率度量和/或生成的文本的测量的这些和其他实施方式可以增加自动化助理基于适当文本生成响应内容的可能性。这样可以得到改进的自动化助理,并且还可以节省各种资源,因为它减轻了自动化助理使用不是口头话语中正在说的语言的语言基于文本识别提供错误的响应内容的风险。错误响应内容风险的这样的减轻防止在试图改正错误响应内容时对进一步的用户接口输入(以及该输入的处理)的进一步资源密集型检测。
8、本文描述的一些实施方式可以另外地或替代地利用各种技术以执行指派给给定用户的用户简档的多个语言中的每一个的给定用户的给定口头话语的语音识别。在那些实施方式中,多个语言的概率度量(可选地取决于当前场境参数)和/或语音识别中的每一个的测量仍然可以被用来适当地选择语音识别中的仅一个以生成和提供响应于给定口头话语的内容。作为一个特定示例,假设给定用户在给定用户的用户简档中仅指派了第一语言和第二语言。进一步假设第一语言具有60%的概率度量,第二语言具有40%的概率度量。可以使用第一语言的第一语音识别模型来执行给定口头话语的语音识别,以生成第一语言的第一文本,以及指示第一文本表示给定口头话语的70%可能性的测量。也可以使用第二语言的第二语音识别模型来执行给定口头话语的语音识别,以生成第二语言的第二文本,以及指示第二文本表示给定口头话语的70%可能性的测量。然后,可以选择第一文本或第二文本之一作为适当的文本,用于生成和提供响应于给定口头话语的内容。例如,基于第一语言概率度量(60%)高于第二语言概率度量(40%),并且基于第一和第二文本测量相同(70%),可以选择第一文本代替第二文本。
9、这些和其他利用语言概率度量和/或生成文本测量的实施方式可以增加自动化助理基于适当文本生成响应内容的可能性。这样可以得到改进的自动化助理,并且还可以节省各种资源,因为它减轻了自动化助理使用不是口头话语中正在说的语言的语言基于文本识别提供错误的响应内容的风险。错误响应内容风险的这样的减轻防止在试图改正错误响应内容时对进一步的用户接口输入(以及该输入的处理)的进一步资源密集型检测。
10、如上所述,可以确定提供口头话语的用户的用户简档,并且使用该用户简档来标识指派给该用户简档的语言和/或该语言的概率度量,以用于本文描述的各种实施方式。在一些实施方式中,基于确定捕获口头话语的音频数据的至少一部分具有与指派给用户简档的特征相对应的一个或多个特征(例如,语调、音高、音调、口音、语调和/或任何其他特征),来确定用户简档。例如,可以使用一个或多个声学模型来处理音频数据,以确定音频数据的特征,并且将这些特征与候选用户简档(例如,与通过其接收音频数据的客户端设备相关联的候选用户简档)的特征相比较,并且基于指示充分匹配的比较,将候选用户简档之一确定为音频数据的用户简档。
11、在这些实施方式中的一些实施方式中,被确定为具有与映射到用户简档的特征相对应的特征的音频数据的部分是对应于被配置为调用自动化助理的调用短语的部分。自动化助理的调用短语包含一个或多个热词/触发词,并且可以是例如“hey assitant(嘿助理)”、“ok assitant(好的助理)”和/或“assitant(助理)”。通常,包括助理接口的客户端设备包括一个或多个本地存储的声学模型,客户端设备利用这些声学模型来监测口头调用短语的出现。这种客户端设备可以利用本地存储的模型本地处理接收到的音频数据,并且丢弃不包括口头调用短语的任何音频数据。然而,当接收到的音频数据的本地处理指示口头调用短语的出现时,客户端设备将使该音频数据和/或随后的音频数据由自动化助理进一步处理。
12、例如,当本地处理指示调用短语的出现时,可以发生进一步的处理来确定用户简档,和/或可以发生进一步的处理来根据本文描述的实施方式来执行语音识别。例如,在一些实施方式中,当利用本地存储的声学模型对音频数据的一部分的本地处理指示该部分中出现口头调用短语时,来自本地存储的声学模型的输出可以指示音频数据的该部分的特征,并且可以将这些特征与候选用户简档的特征进行比较,以确定对应于口头调用短语(并且因此,对应于口头调用短语之后的音频数据的该部分)的用户简档。此外,例如,当利用本地存储的声学模型的本地处理指示在音频数据的一部分中出现口头调用短语时,附加声学模型(本地或远程)可以可选地用于处理音频数据的至少一部分,确定音频数据的至少一部分的特征,以及确定对应于这些特征的用户简档。在一些实施方式中,可以利用附加的或替代的技术来确定提供口头话语的用户的用户简档,诸如使用来自客户端设备的相机的输出来确定提供在客户端设备处检测到的口头话语的用户的用户简档的技术。
13、如上所述,可以为设备或应用的特定用户创建用户简档,以便尤其表征用户的语言偏好。可以向用户提供对其用户简档的控制,并且用户可以控制是否为用户创建任何用户简档。用户的用户简档可以识别用户在与设备或应用互动时可以使用的多个不同语言。在一些实施方式中,用户可以手动创建或修改用户简档,以便用户可以手动指明用户可以使用其与自动化助理互动的偏好语言。例如,用户可以提供明确的自然语言输入,诸如“myname is chris and i speak english(我的名字是克里斯,我说英语)”,以便使自动化助理将用户简档中的英语语言设置为用户在与自动化助理通信时最可能说出的语言。作为另一个示例,用户可以提供诸如“i speak english and spanish(我说英语和西班牙语)”的明确自然语言输入,以便使自动化助理在他/她的用户简档中将英语和西班牙语都设置为用户的候选语言。另外地或替代地,被指派给用户的用户简档的一个或多个候选语言可以基于与用户相关联并可由自动化助理访问的信息,诸如电子邮件、联系人姓名、包括文本的图像、位置数据等。例如,用户的用户简档可以包括基于用户使用候选语言与自动化助理(和/或其他平台)的过去交互的候选语言。此外,用户的用户简档可以可选地具有被指派给候选语言中的每一个候选语言的一个或多个相应概率。对于用户的用户简档,语言的一个或多个概率可以基于用户与自动化助理的过去交互和/或与其他平台(例如,电子邮件平台、消息传递平台和/或搜索平台)的过去交互的对该语言的使用。
14、在一些实施方式中,由用户简档标识的每个语言可以与概率相关联,该概率可以取决于用户在其中与自动化助理交互的场境。例如,当用户提供用于初始化自动化助理以执行特定动作的调用短语时,用户简档可以标识用户将使用特定语言的概率。替代地或另外地,与特定语言相关联的概率可以是动态的,并且在用户和自动化助理之间的对话会话期间改变。语言中的每一个可以对应于一个或多个语音识别模型,用于将体现特定语言的音频输入转换成表征该输入的文本和/或其他语义表示。当选择将用于解释来自用户的输入的语言或用户简档时,自动化助理可以选择适合于特定交互的语音识别模型。
15、用于确定用于特定交互的语言模型的过程可以包括操作,诸如:使用一个或多个语言模型处理音频数据流,以监测用于调用自动化助理的调用短语的出现。操作还可以包括基于处理检测在音频数据的一部分中的调用短语的出现。基于该处理或使用一个或多个附加语言模型的任何附加处理,可以确定关于音频数据是否包括对应于存储的用户简档的调用短语。当音频数据包括对应于存储的用户简档的调用短语时,可以标识被指派给用户简档的语言。基于所标识的语言和/或音频数据的部分,可以选择语言模型。使用所选择的语言模型,可以处理音频数据的附加部分,并且可以基于音频数据的附加部分的处理将响应内容提供回用户。
16、在一些实施方式中,当用户简档与多个不同的语言相关联,并且每个语言与交互期间将使用相应语言的概率相关联时,每个语言的概率可以是动态的。例如,在开始用户和自动化助理之间的对话会话之前,用户简档可以初始地指示第一语言具有为a(例如,70%)的概率,第二语言具有为b(例如,30%)的概率。在交互期间,自动化助理可以检测到第一查询使用的是第二语言。作为响应,自动化助理可以使得与用户简档相关联地存储的一个或多个概率被修改。例如,在对话的至少剩余部分期间,用户简档可以指示第一语言的概率降低(例如,5%),第二语言的概率可以增加(例如,95%)。
17、多个用户简档可由自动化助理管理,该助理可通过由多个不同用户交互的计算设备访问。这样,由自动化助理选择的语言模型可以基于根据与自动化助理交互的用户而选择的用户简档。自动化助理可以标识用户简档和在用户简档中被指示为至少在即时场境中具有被用户使用的阈值可能性的一个或多个语言。在一些实施方式中,用户可以与和不同设备相关联的多个用户简档相关联,或者与标识特定设备偏好的语言的单个用户简档相关联。例如,当与车载自动化助理通信时,用户可能偏好在他们的车上说特定的语言,但是偏好在也存在说不同语言的其他人的他们的家里说不同的语言。因此,用户简档可以标识多个设备和语言以及所标识的多个设备中的每个设备的对应概率。
18、在一些实施方式中,为特定用户选择的语言可以基于自动化助理可用的应用数据。这种应用数据可以对应于加载到用户通过其与自动化助理交互的设备上的应用。例如,包括自动化助理接口的计算设备也可以托管包括以特定语言写的电子邮件的电子邮件应用。自动化助理可以确认特定的语言(例如法语),并确认当操作计算设备、应用和/或可以与自动化助理相关联的任何其他设备或模块时,用户偏好使用该特定语言与自动化助理交互。例如,自动化助理可以专门提示用户一个问题,诸如“i noticed used you understandfrench,would you like to interact using french?(我注意到您理解法语,您想使用法语进行交互吗?)”取决于响应,自动化助理可以修改用户简档,以指示用户对一个设备或应用使用特定语言进行交互的偏好。
19、在本文描述的一些另外或替代的实施方式中,语音识别模型(或其他语言模型)可以在用户调用自动化助理之前被抢先加载到客户端设备。例如,语言模型可以基于位置数据、消息数据(例如,包括旅行计划的电子邮件)、联系人数据、日历数据和/或可以用于推断用户在即将到来的事件或场境期间偏好特定语言的任何其他数据而被抢先加载到客户端设备。此外,在一些另外或替代的实施方式中,可以基于音频数据中捕获的背景噪声选择语言模型,该背景噪声可用于推断用户在特定场境中可能偏好说出的语言。例如,用户可以明确请求自动化助理翻译内容的特定部分(例如,用户将大声读出的文本、用户正在收听的音频等)。对应于该请求的音频数据可以包括背景噪声,因此自动化助理可以处理音频数据以确定用户正在请求翻译,并且还确定用户希望最终翻译成的语言。
20、在一些实施方式中,由用户简档标识的多个语言可以根据用户对其他语言的兴趣而改变。例如,用户简档可以标识用户的默认语言,但是当用户进一步与自动化助理交互时,自动化助理可以标识使用其与用户互动的附加的语言。结果,自动化助理可以将附加的语言包推送到用户的设备,以便当用户与自动化助理通信时,在设备上操作的语言模型可以正确地转换语音到文本。在一些实施方式中,预期用户在未来的特定时间与自动化助理交互,可以将语言包推送到设备。例如,用户可以创建对应于未来时间的日历事件,并且日历事件的标题可以用与用户简档的默认语言不同的语言编写。当日历事件接近(例如,日历事件的前一天)时,自动化助理可以使得对应于不同语言的语言包被推送到用户创建日历事件的设备。替代地,当日历事件标识一个位置,并且自动化助理知道用户通常在该位置使用的特定计算设备时,自动化助理可以使得语言包被推送到该特定计算设备。这样,可以通过当用户在更快或更易访问的网络上时而不是当用户在旅行或不在可预测地可靠的网络内时推送语言包来优化网络带宽。
21、以上描述是作为本公开的一些实施方式的概述而提供的。这些实施方式的进一步描述以及其他实施方式将在下面更详细地描述。
22、在一些实施方式中,阐述了一种由一个或多个处理器实现的方法,包括操作,诸如:使用一个或多个声学模型处理音频数据以监测被配置为调用自动化助理的调用短语的出现。音频数据可以基于在包括用于与自动化助理交互的自动化助理接口的客户端设备处对用户的口头输入的检测。该方法还可以包括基于使用一个或多个声学模型处理音频数据,检测在音频数据的一部分中的调用短语的出现,以及基于使用一个或多个声学模型处理音频数据或使用一个或多个其他声学模型处理音频数据,确定包括调用短语的音频数据的该部分对应于自动化助理可访问的用户简档。该方法还可以包括标识被指派给用户简档的语言,并选择语言的语音识别模型。语言的语音识别模型可以基于确定音频数据的该部分对应于用户简档,并且基于标识被指派给用户简档的语言。该方法还可以包括使用所选择的语音识别模型来处理在音频数据的该部分之后的音频数据的后续部分,并且使得自动化助理提供响应内容,该响应内容基于使用所选择的语音识别模型处理后续部分而确定。
23、在一些实施方式中,该方法可以进一步包括标识被指派给用户简档的附加语言。此外,选择语音识别模型可以包括选择语音识别模型代替附加语言的附加语音识别模型。
24、在一些实施方式中,选择语音识别模型代替附加语言的附加语音识别模型可以包括标识与音频数据相关联的一个或多个场境参数,并且基于在用户简档中与该语言比与附加语言更强地相关联的一个或多个场境参数来选择语音识别模型。一个或多个场境参数可以包括客户端设备的标识符。一个或多个场境参数可以包括以下中的一个或多个:一天中的时间、一周中的一天以及客户端设备的位置。
25、在一些实施方式中,选择语言的语音识别模型可以包括基于被指派给在用户简档中的语言的至少一个概率来选择语音识别模型,其中该至少一个概率基于与用户简档相关联的与自动化助理的先前交互。
26、在一些实施方式中,至少一个概率与一个或多个场境参数相关联,并且该方法可以进一步包括标识一个或多个场境参数与音频数据相关联,基于至少一个概率与被标识为与音频数据相关联的一个或多个场境参数相关联,在选择时使用至少一个概率。
27、在一些实施方式中,使用所选择的语音识别模型来处理在音频数据的该部分之后的音频数据的后续部分可以包括在用该语言生成对应于后续部分的文本时使用所选择的语音识别模型。此外,使自动化助理提供相应内容,该相应内容基于使用所选择的语音识别模型处理后续部分而确定,可以包括:基于文本生成响应内容,并使自动化助理接口渲染基于响应内容的输出。
28、在一些实施方式中,自动化助理可以被配置为访问多个不同的用户简档,该用户简档:在客户端设备处可用,并且与客户端设备的多个不同用户相关联。在一些实施方式中,多个不同的用户简档可以各自标识一个或多个对应的语言以及对应语言中的每一个的对应的语言概率。此外,对应的语言概率可以各自基于多个不同用户中对应的一个用户与自动化助理之间的先前交互。
29、在一些实施方式中,使用所选择的语音识别模型来处理音频数据的后续部分可以包括使用所选择的语音识别模型来生成该语言的第一文本。此外,该方法可以包括标识被指派给用户简档的附加语言,并选择附加语言的附加语音识别模型。选择附加语言的附加语音识别模型可以基于确定音频数据的部分对应于用户简档,并且可以基于标识被指派给用户简档的附加语言。此外,该方法可以包括使用所选择的附加语音识别模型来处理在音频数据的该部分之后的音频数据的后续部分。使用所选择的附加语音识别模型来处理音频数据的后续部分可以包括使用所选择的语音识别模型来生成附加语言的第二文本,并且选择该语言的第一文本,代替附加语言的第二文本。此外,使自动化助理提供基于使用所选择的语音识别模型处理后续部分的而确定的响应内容可以包括:基于选择第一语言的第一文本,使自动化助理提供基于该语言的第一文本来确定的响应内容。
30、在又一实施方式中,由一个或多个处理器实施的方法被阐述为包括诸如处理音频数据的操作。音频数据可以基于在客户端设备处检测用户的口头输入,并且客户端设备可以包括用于与自动化助理交互的自动化助理接口。该方法还可以包括基于音频数据的处理来确定音频数据的至少一部分匹配自动化助理可访问的用户简档,并且标识被指派给用户简档并且对应于特定语言的特定语音识别模型的至少一个概率性的度量。该方法还可以包括基于至少一个概率性的度量满足阈值:选择特定语言的特定语音识别模型,用于处理音频数据,以及使用特定语言的特定语音识别模型来处理音频数据以生成对应于口头输入的特定语言的文本。该方法还可以包括使自动化助理提供基于生成的文本确定的响应内容。
31、在一些实施方式中,用户简档还包括对应于不同语言的至少一个不同语音识别模型的附加概率性的度量。此外,该方法可以包括基于附加概率性的度量不满足阈值,避免使用不同的语音识别模型处理音频数据。
32、在一些实施方式中,该方法可以包括标识与音频数据相关联的当前场境数据。标识至少一个概率性的度量可以基于当前场境数据和至少一个概率性的度量之间的对应。在一些实施方式中,当接收到口头输入时,当前场境数据可以标识客户端设备的位置或正通过客户端设备访问的应用。在一些实施方式中,当前场境数据标识客户端设备。在一些实施方式中,概率性的度量可以基于用户和自动化助理之间过去的交互。
33、在又一实施方式中,由一个或多个处理器实现的方法被阐述为包括包含接收音频数据的操作。音频数据可以基于在客户端设备处检测用户的口头输入,客户端设备包括用于与自动化助理交互的自动化助理接口。该方法还可以确定音频数据对应于自动化助理可访问的用户简档,并且标识被指派给用户简档的第一语言和被指派给用户简档中的第一语言的第一概率度量。该方法还可以包括选择第一语言的第一语音识别模型。选择第一语言的第一语音识别模型可以基于标识被指派给用户简档的第一语言。该方法还可以包括使用所选择的第一语音识别模型来生成第一语言的第一文本,以及指示第一文本是口头输入的适当表示的可能性的第一测量。该方法还可以包括标识被指派给用户简档的第二语言,以及被指派给用户简档中的第二语言的第二概率度量。另外,该方法可以包括选择第二语言的第二语音识别模型。选择第二语言的第二语音识别模型可以基于标识被指派给用户简档的第二语言。该方法还可以包括使用所选择的第二语音识别模型来生成第二语言的第二文本,以及指示第二文本是口头输入的适当表示的可能性的第二测量。该方法还可以包括选择第一语言的第一文本代替第二语言的第二文本。选择第一语言的第一文本代替第二语言的第二文本可以基于:第一概率度量、第一测量、第二概率度量和第二测量。此外,该方法可以包括,响应于选择第一文本,使得自动化助理提供基于所选择的第一文本确定的响应内容。
34、在一些实施方式中,该方法可以包括标识与音频数据相关联的当前场境。标识第一概率度量可以基于对应于当前场境的第一概率度量。标识第二概率度量可以基于对应于当前场境的第二概率度量。在一些实施方式中,确定音频数据对应于用户简档可以基于将音频数据的特征与用户简档的特征进行比较。
35、本公开的各方面可以有利地减少口头话语在其期间没有被适当的语音识别模型解释的事件。因此,可以接收对用户输入的改进的响应,减少自动化助理不响应或者没有按预期操作的情况。除了改善对于用户的功能性,这还可以通过减少重复命令来减少用于实现这种助理的计算机和/或网络资源的负载,以便达到期望的结果。
36、其他实施方式可以包括存储指令的非暂时性计算机可读存储介质,该指令可由一个或多个处理器(例如,中央处理单元(cpu)、图形处理单元(gpu)和/或张量处理单元(tpu))执行以执行诸如上述和/或本文其他地方描述的方法中的一个或多个的方法。另外其他的实施方式可以包括一个或多个计算机的系统,该计算机包括一个或多个处理器,该处理器可操作以执行存储的指令以执行诸如上述和/或本文其他地方描述的方法中的一个或多个的方法。
37、应该理解,在本文更详细描述的前述概念和附加概念的所有组合都被认为是本文公开的主题的一部分。例如,出现在本公开结尾的所要求保护的主题的所有组合被认为是本文公开的主题的一部分。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21066.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表