基于频率调制的人声合成方法、装置、设备及存储介质与流程
- 国知局
- 2024-06-21 10:40:44
本发明涉及数据处理的,尤其涉及一种基于频率调制的人声合成方法、装置、设备及存储介质。
背景技术:
1、随着语音技术的快速发展,人们对于语音的质量和准确性要求越来越高。特别是在娱乐、通信和语音助手等领域,高质量的语音重构成为了一个关键需求。传统的语音处理方法主要依赖于固定的算法和模型,这些方法在处理复杂的人声信号时可能无法达到理想的效果。
2、尽管有很多技术可以对人声信号进行处理,但现有的方法在提取语音的音色和语义信息方面可能不够精准。音色和语义信息的提取是语音重构的基础,如果提取不准确,将直接影响到重构语音的质量。此外,现有技术在匹配调制参数时,可能没有充分利用预设的参数数据库,导致重构语音与原始语音之间存在差异。再者,现有的声音重构模型可能没有针对不同的声音特点进行个性化的调整,从而降低了语音重构的效果。
3、因此,现有的人声信号处理和重构技术在音色和语义信息提取、调制参数匹配以及声音重构模型调整方面存在明显的局限性,这些问题亟待解决。
技术实现思路
1、本发明提供了一种基于频率调制的人声合成方法、装置、设备及存储介质,用于实现如何解决现有的人声信号处理和重构技术在音色和语义信息提取、调制参数匹配以及声音重构模型调整方面存在的局限性问题。
2、本发明第一方面提供了一种基于频率调制的人声合成方法,所述基于频率调制的人声合成方法包括:
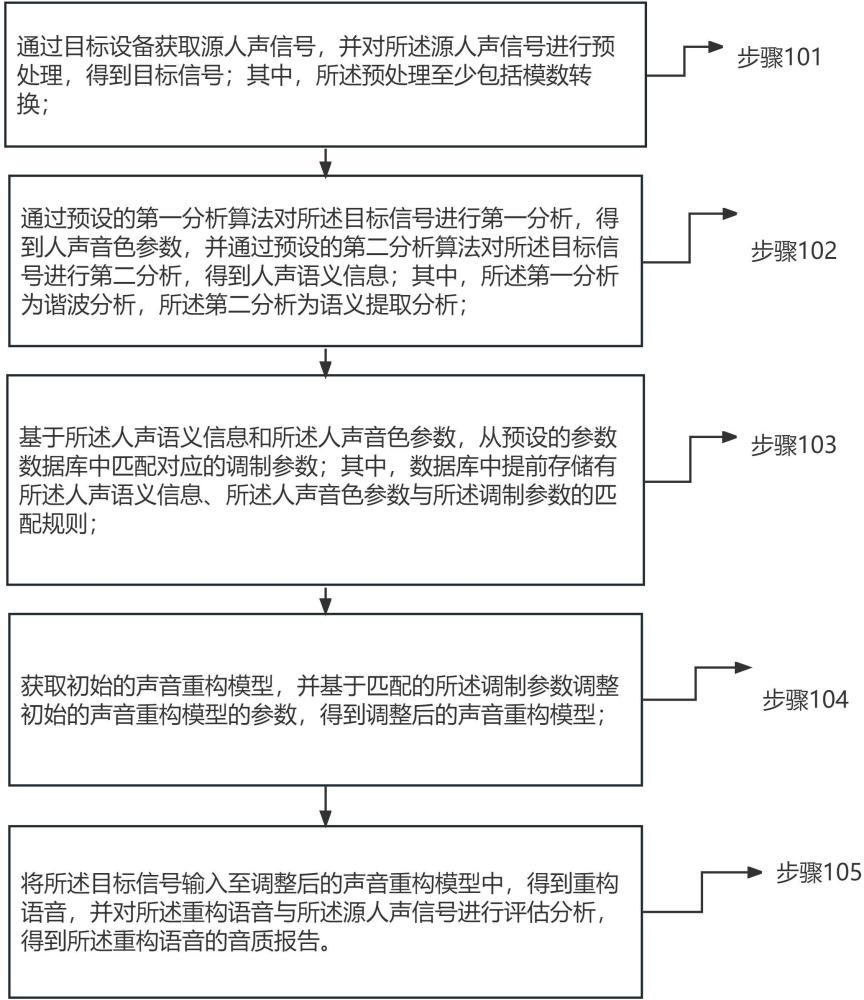
3、通过目标设备获取源人声信号,并对所述源人声信号进行预处理,得到目标信号;其中,所述预处理至少包括模数转换;
4、通过预设的第一分析算法对所述目标信号进行第一分析,得到人声音色参数,并通过预设的第二分析算法对所述目标信号进行第二分析,得到人声语义信息;其中,所述第一分析为谐波分析,所述第二分析为语义提取分析;
5、基于所述人声语义信息和所述人声音色参数,从预设的参数数据库中匹配对应的调制参数;其中,数据库中提前存储有所述人声语义信息、所述人声音色参数与所述调制参数的匹配规则;
6、获取初始的声音重构模型,并基于匹配的所述调制参数调整初始的声音重构模型的参数,得到调整后的声音重构模型;
7、将所述目标信号输入至调整后的声音重构模型中,得到重构语音,并对所述重构语音与所述源人声信号进行评估分析,得到所述重构语音的音质报告。
8、可选的,在本发明第一方面的第一种实现方式中,所述目标设备的选取过程,包括:
9、发送基于无线频率识别的近场通信协议至有源声音地理坐标的初始设备,接收初始设备电子标签反馈的加密认证信息;
10、通过预设的深度学习算法对接收到的加密认证信息进行实时解析,得到解析数据,从所述解析数据中获取采集的数据包,将所述数据包解析为制造商识别块、数据保护框架块和检索识别块;
11、通过训练后的深度神经网络模型解码制造商识别块中的制造商特征信息,并对比预设的制造商数据库,找到与制造商特征信息相关的数据表;
12、从数据保护框架块中解析出初始设备的数据加密框架,并通过预设的哈希函数对数据加密框架进行哈希运算,生成唯一哈希标签;
13、在所述数据表中筛选包含唯一哈希标签的数据列;其中,所述数据列包括多个具有数据采集权限的初始设备及其对应的编码;
14、基于训练后的文本相似性评价模型,将每个初始设备对应的编码与检索识别块进行字符级别的相似性评估,选拔出与检索识别块的字符级别相似度高于设定阈值的设备作为采集源人声信号的目标设备。
15、可选的,在本发明第一方面的第二种实现方式中,所述基于所述人声语义信息和所述人声音色参数,从预设的参数数据库中匹配对应的调制参数,包括:
16、基于获取的人声语义信息和人声音色参数,通过预设的参数处理规则,将所述人声语义信息与人声音色参数进行分离处理,得到语义特征数据和音色特征数据;其中,所述语义特征数据由字符汇、语句结构和情境含义组成,所述音色特征数据由声带震动、发音形式和声道共振特征组成;
17、从语义特征数据提取第一语义数据和从音色特征数据中提取第二音色数据;其中,所述第一语义数据由多个语义单位组成,所述第二音色数据由一系列的声学特征组成;
18、基于预设的音色特征组合规则,将所述第一语义数据与所述第二音色数据组合为目标声音特征组合;
19、根据所述目标声音特征组合,对预设的标准编码表进行重新编排,生成声音编码表;
20、利用声音编码表对第一语义数据和第二音色数据进行解码,得到语义音色数据;
21、根据所述语义音色数据,在预设参数数据库中查找对应的调制参数;其中,数据库中提前存储有语义音色数据与调制参数的映射关系。
22、可选的,在本发明第一方面的第三种实现方式中,所述文本相似性评价模型的训练过程,包括:
23、获取语料库数据,利用深度学习技术对语料库数据进行语义理解和字符级别的识别标记,得到文本数据,将所述文本数据输入至初级的深度学习网络中;所述初级的深度学习网络包含一个字符级相关度模型、一个字符变化模式预测模型,以及一个字符分布模式解析模型;
24、基于所述字符级相关度模型,通过代码扫描语料库中每个字符的出现频率和对应位置信息,生成字符级识别表格;其中,所述字符级识别表格记录每个字符的位置、出现频率和分布情况;
25、通过字符变化模式预测模型,结合时间序列分析和字符级分析,对字符出现的变化进行预测,生成动态模式预测表;其中,所述动态模式预测表记录低频字符、高频字符和噪声字符的更迭变化模式;
26、通过字符分布模式解析模型对字符的分布模式进行解析,生成字符级分布图;其中,所述字符级分布图中所有的预测事件都以分布图的形式保存;
27、根据预测得到的字符级识别表格、动态模式预测表、字符级分布图和实际的字符级识别表格、实际的动态模式预测表、实际的字符级分布图计算对应的误差值;分别运用自适应超参数调整算法、动态学费率调整算法和批量归一化优化算法优化网络的权重,调整文本相似性评价模型的参数,并将各个误差值最小化,经过多次优化调整,得到训练后的文本相似性评价模型。
28、可选的,在本发明第一方面的第四种实现方式中,所述预处理还包括:噪声去除、基音周期检测、语音分割和频率特征提取。
29、本发明第二方面提供了一种基于频率调制的人声合成装置,所述基于频率调制的人声合成装置包括:
30、获取模块,用于通过目标设备获取源人声信号,并对所述源人声信号进行预处理,得到目标信号;其中,所述预处理至少包括模数转换;
31、分析模块,用于通过预设的第一分析算法对所述目标信号进行第一分析,得到人声音色参数,并通过预设的第二分析算法对所述目标信号进行第二分析,得到人声语义信息;其中,所述第一分析为谐波分析,所述第二分析为语义提取分析;
32、匹配模块,用于基于所述人声语义信息和所述人声音色参数,从预设的参数数据库中匹配对应的调制参数;其中,数据库中提前存储有所述人声语义信息、所述人声音色参数与所述调制参数的匹配规则;
33、调整模块,用于获取初始的声音重构模型,并基于匹配的所述调制参数调整初始的声音重构模型的参数,得到调整后的声音重构模型;
34、评估模块,用于将所述目标信号输入至调整后的声音重构模型中,得到重构语音,并对所述重构语音与所述源人声信号进行评估分析,得到所述重构语音的音质报告。
35、本发明第三方面提供了一种基于频率调制的人声合成设备,包括:存储器和至少一个处理器,所述存储器中存储有指令;所述至少一个处理器调用所述存储器中的所述指令,以使得所述基于频率调制的人声合成设备执行上述的基于频率调制的人声合成方法。
36、本发明的第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述的基于频率调制的人声合成方法。
37、本发明提供的技术方案中,有益效果:本发明提供一种基于频率调制的人声合成方法、装置、设备及存储介质,通过目标设备获取源人声信号,并对所述源人声信号进行预处理,得到目标信号;通过预设的第一分析算法对所述目标信号进行第一分析,得到人声音色参数,并通过预设的第二分析算法对所述目标信号进行第二分析,得到人声语义信息;基于所述人声语义信息和所述人声音色参数,从预设的参数数据库中匹配对应的调制参数;获取初始的声音重构模型,并基于匹配的所述调制参数调整初始的声音重构模型的参数,得到调整后的声音重构模型;将所述目标信号输入至调整后的声音重构模型中,得到重构语音,并对所述重构语音与所述源人声信号进行评估分析,得到所述重构语音的音质报告。本发明采用预设的第一分析算法和第二分析算法,分别进行谐波分析和语义提取分析,确保从人声信号中准确地提取出音色参数和语义信息,这为后续的声音重构提供了强有力的基础。并且通过基于提取的人声语义信息和音色参数,从预设的参数数据库中匹配调制参数,可以确保声音重构过程更加个性化和精确。由于数据库中存储有匹配规则,这进一步简化和加速了匹配过程。获取初始的声音重构模型并基于匹配的调制参数进行参数调整,确保重构的声音更加接近于源人声信号的原始特点。这种个性化的模型调整方法大大提高了声音重构的质量。最后将目标信号输入到调整后的声音重构模型中,得到重构语音,然后与源人声信号进行评估分析,得到音质报告。确保其与原始语音尽可能接近,并满足用户的需求。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21143.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表