一种基于注意力特征拼接及WPD高频带划分的语音增强方法
- 国知局
- 2024-06-21 10:41:32
本发明属于语音降噪,具体涉及一种基于改进wave-u-net网络的智能语音增强方法。
背景技术:
1、在语音识别任务中,原始音源常常存在着各种噪声的干扰,很大程度地影响了语音的质量,会对后续的研究会产生较大的干扰。因此,选用合适的方法进行语音增强提高语音质量是十分必要的。为满足人们对高质量语音的需求等,语音增强技术在学术界和工业领域得到了广泛的研究和应用。
2、传统的语音增强领域涌现出了多种经典算法,例如谱减法、维纳滤波算法、卡尔曼滤波等方法相继被应用到了语音增强领域。上述传统语音增强方法通常依赖于语音信号和噪声信号的一般统计信息进行分析,通过噪声估计方法从包含噪声的语音信号中分离出纯净的语音信号。尽管这些算法都取得了不错的效果,但传统语音增强方法无法适应复杂多变的噪声环境。
3、随着深度学习技术的快速发展,深度学习有自动学习特征表示、实现端到端学习,并具有较强的适应性、泛化能力和鲁棒性等优点,因此逐步应用于语音增强技术中。目前,多种深度学习网络模型在语音识别领域都得到了应用,如深度神经网络(dnn)、递归神经网络(rnn)、卷积神经网络(cnn)、u-net神经网络和transformer神经网络以及wave-u-net网络。
4、wave-u-net网络基于u-net架构,并结合了wave-net的特点,其输入和输出均为时域语音信号,省略了对语音信号进行特征提取等步骤,并且不需要使用带噪语音的相位信息来辅助语音增强任务,使得网络模型的输入输出处理更加简单,更容易实现和调整。在语音增强任务中,引入wave-u-net网络,使得语音增强模型能具备端到端学习、可扩展性、跨尺度特征学习、跳跃连接和并行计算等优势,因此本发明基于wave-u-net网络设计一种改进型的智能语音增强方法。
技术实现思路
1、本发明提供一种改进wave-u-net网络的语音增强方法,该方法结合dwt-wpd模块到wave-u-net网络中,利用离散小波变换(discrete wavelet transform,dwt)解决原始网络中下采样层因混叠而造成信息丢失的问题,同时引入小波包分解(wavelet packetdecomposition,wpd)以解决dwt不能对语音信号高频带作精细地划分的问题。该改进方法同时使用注意力机制替换原始wave-u-net的上、下采样层中间采用的跳跃连接,将低级特征与高级特征进行有效拼接,避免出现语义问题,帮助网络进一步提高语音增强能力。
2、为实现上述目标,本发明采用的技术方案是:
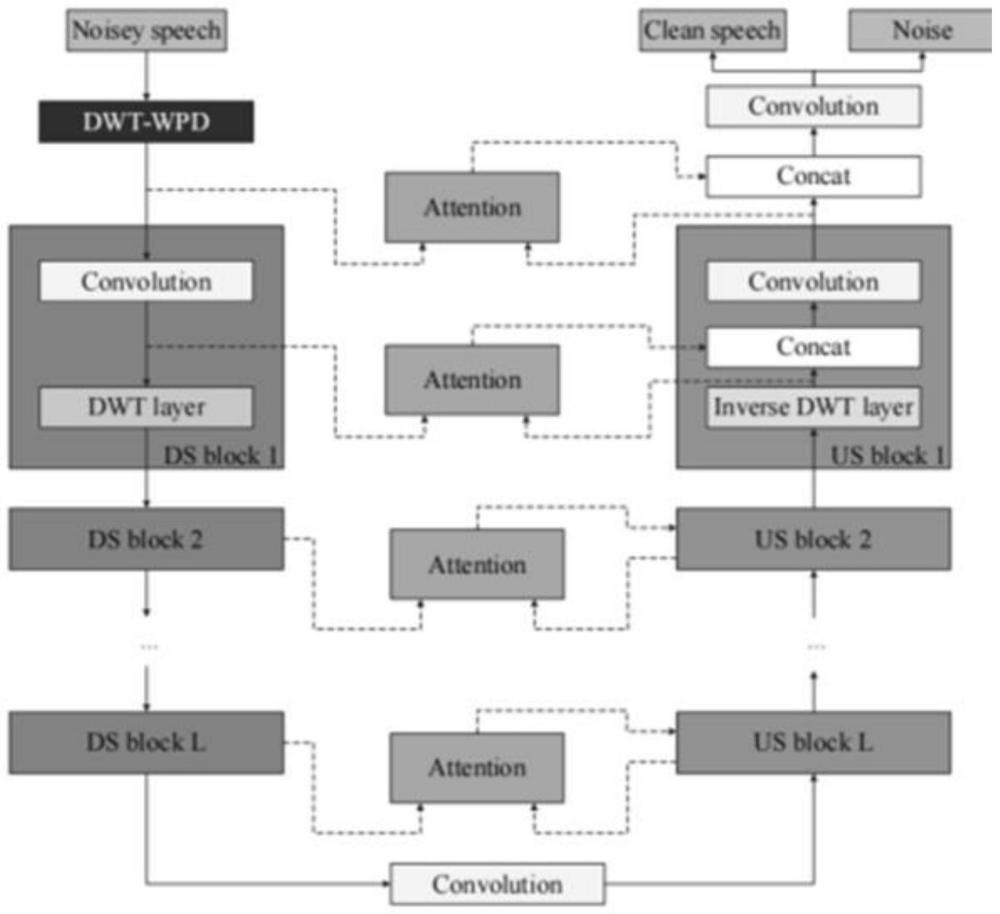
3、一种改进wave-u-net网络的语音增强方法,其网络结构如附图1所示,具体包括如下步骤:
4、s10,在下采样之前构建dwt-wpd模块,避免后续下采样层因没有低通滤波器而导致的混叠,dwt-wpd模块结构如附图2所示。
5、s20,构建ds下采样模块,每个ds模块由l个ds块组成,每个ds块包含卷积层和dwtlayer。具体地,第l块ds层包含convd(c(e)l,f(e))和dwt layer层。
6、s30,将注意力机制替换于wave-u-net体系结构中的跳跃连接。具体地,在解码结构的跳跃连接阶段,使用注意力机制模块代替传统的直接连接方式,将高级特征和低级特征有效整合,更好地提取长期依赖特征。注意力机制的具体结构如附图3所示。
7、s40,构建us上采样模块,每个us块包含inverse dwt layer、连接层和卷积层。具体地,第l块us层包含inverse dwt layer、concat(ds featurel)和convd(c(e)l,f(e))。
8、s101,数据首先通过dwt进行处理,通过一系列的低通滤波器和高通滤波器将语音信号分解成不同频率范围的子带。这个过程产生了包含低频和高频信息的不同尺度的小波系数。
9、s102,对所选择的小波系数应用wpd,将其进一步分解成更小的子带。这个过程使用一组低通和高通滤波器对每个子带进行再次分解,以获得更细粒度的频域表示。
10、s103,再将所选择的小波包系数进行逆小波包变换进行重构,得到增强后的语音信号。
11、s104,对重构后的语音信号进行后处理步骤,如去噪、音量调整、动态范围压缩等。
12、s201,convd(x,y)表示具有x个大小为y的滤波器的一维卷积层,其所有的卷积层都是没有填充的,用卷积层得到的特征图有奇数个时间点。
13、对于特征图z=[z1,…,zc]∈rt*c其中t和c分别是时间点数和特征通道数,特征通道索引记为c,一般情况下t为偶数。其中,dwt层根据改进后的方案对zc进行小波变换,具体地,该方案包括四个步骤:
14、第一步是时间分割,将zc的每个特征通道分割为奇样本分量和偶样本分量
15、第二步是进行预测,使用预测算子p从计算出并从减去预测得到误差分量ec∈rt/2,
16、
17、由于在时间分割步骤会引起混叠,因此第三部为更新阶段,通过对ec应用更新操作符u并将其添加到来计算平滑的偶数样本分量sc∈rt/2,
18、
19、第四步是缩放步骤,其中sc和ec分别用一个归一化常数a及其倒数进行缩放,进而得到将上述操作应用于z所有的通道后,dwt层沿通道轴连接和形成向下采样的特征映射
20、
21、s202,dwt层如附图4所示。
22、s301,注意力机制模块中通过额外的一维卷积和核大小为1,用于计算注意力权重:
23、
24、其中bl表示注意力权重的向量,σ表示sigmoid函数,dsl表示输入序列的特征向量,usl表示上下文向量,bl,1表示偏置项,用于调整注意力权重的偏移。中间特征层输入给卷积以得到注意力掩码:
25、
26、al表示注意力掩码(attention mask)的向量,σ表示sigmoid函数,是卷积操作的权重矩阵,bl是前面公式中计算得到的注意力权重,bl,2为偏置项,用于调整注意力掩码的偏移。最后将al与dsl逐项乘积结果连接到usl。
27、s401,inverse dwt layer是执行上述s202中dwt layer过程的反向操作,如附图5所示。
28、s402,concat(x)表示前一层输出与x沿通道轴的连接。
29、s403,convd(x,y)表示具有x个大小为y的滤波器的一维卷积层,其所有的卷积层都是没有填充的,用卷积层得到的特征图有奇数个时间点。
30、s404,最后一层的us模块输出的特征图与对应ds层的特征图进行特征合并。再通过卷积进行特征的整合和调整。
31、与原始wave-u-net相比,本发明的有益效果是:
32、本发明结合dwt-wpd模块到wave-u-net网络中,利用离散小波变换(dwt)解决了原始网络中下采样层因混叠而造成的信息丢失问题,同时使用小波包分解(wpd)解决dwt不能对信号高频带作精细划分的问题。
33、本发明提出注意力机制模块取代原始wave-u-net的跳跃连接。利用注意力机制将不同级别的特征进行有效拼接,避免出现语义问题,帮助网络进一步提高语音增强能力。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21241.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表