一种基于双向匹配迁移的水下目标探测识别方法
- 国知局
- 2024-06-21 10:41:46
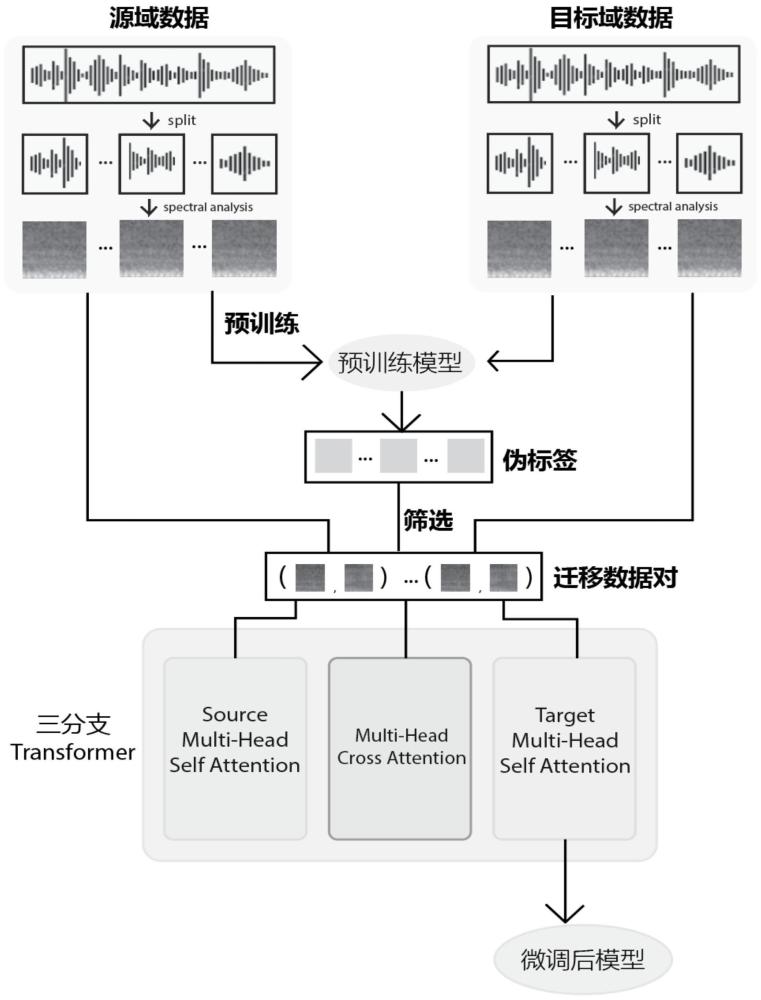
本发明属于水下目标探测识别领域,尤其涉及一种基于双向匹配迁移的水下目标探测识别方法。
背景技术:
1、基于被动声呐的水下目标识别主要通过声呐进行水下信号采集,由于水下信号复杂,噪音多,需要进行预处理,包括去噪,滤波,时频分析等,从处理后的信号中提取有效的特征,例如频率、能量、波形等,以区分不同的水下目标。最后利用机器学习或其他算法将特征向量与已知目标的特征向量进行比较,以将信号分类为不同的水下目标。
2、作为机器学习的一个分支,深度学习今年来已经成为主流的分类识别算法,大部分文章采用简单的单层卷积网络,或者深层卷积网络来对特征进行分类识别,最后通过全连接层来获得最终的分类结果。这其中yang等[yang h,li j,shen s,et al.a deepconvolutional neural network inspired by auditory perception for underwateracoustic target recognition[j].sensors,2019,19(5):1104.]提出了通过一组多尺度深度滤波器子网络对船舶辐射噪声的复杂频率分量进行分解和建模来分解声音,并将卷积网络加深来模拟的听觉系统以提高分类的准确率。另外对于卷积层的改进有从最后的全连接层入手,hu[hu g,wang k,peng y,et al.deep learning methods for underwatertarget feature extraction and recognition[j].computational intelligence andneuroscience,2018,2018.]等等提出使用极限学习机(elm)来完全取代最后的全连接层来加快训练前馈神经网络的时间并提高模型的泛化性。另外的一大类深度模型采用自动编码模式,如yang等[yang h,xu g,yi s,et al.a new cooperative deep learning methodfor underwater acoustic target recognition[c]//oceans2019-marseille.ieee,2019:1-4.]人2019年通过无监督学习在基于lstm的dae网络中预训练dlstm模型。然后,利用预训练的dlstm模型和softmax分类器对船舶辐射噪声进行分类。类似的ke等[5]使用无监督特征提取进行预训练,提出了一个一维卷积自编码器-解码器模型,然后对模型进行预训练以从高共振分量中提取特征。这类算法有着相似的思想,通过非监督的预训练先生成一个模型,然后通过少量的标注数据进行微调,这样成功解决了标记数据少的问题。这样的思想在yang等[yang h,shen s,yao x,et al.competitive deep-belief networks forunderwater acoustic target recognition[j].sensors,2018,18(4):952.]2018年提出的竞争深度置信网络中亦有应用,他利用大量未标记数据进行预训练来初始化参数,将隐藏单元先分类用于竞争学习的初始参数,然后逐层训练网络,有监督的微调。但上述内容没有解决微调时面对未标记数据的情况,无法做到无监督的微调。
技术实现思路
1、发明目的:本发明的目的在于提供一种基于双向匹配迁移的水下目标探测识别方法。利用伪标签来解决未标记数据,并通过交叉注意力机制消除微调时的噪音,解决了无监督域适应的难点,能够消除现有的迁移学习面对未标记数据造成的迁移噪音,提升微调后模型的鲁棒性,增强模型面对多种环境的普适性。
2、技术方案:本发明的一种基于双向匹配迁移的水下目标探测识别方法,该方法将适应已标注的源域数据的模型迁移至全新的未标注的目标域数据中,包括如下步骤:
3、s100、分别采集源域数据并标注与未标注的目标域数据,利用源域数据预训练模型为目标域数据生成聚类中心,然后通过聚类算法为所有数据生成伪标签,通过双向匹配机制生成迁移数据对,并剔除标签不一致的数据对;
4、s200、通过生成的迁移数据对进行迁移学习,对步骤s100中的预训练模型进行微调,利用交叉注意力机制消除潜在误配对数据的噪音,最终得到适应目标域数据分布的新模型,而后将采集的目标水域信号输入模型获得探测识别结果。
5、进一步的,步骤s100中,所述源域数据样本数至少应为目标域数据的4-10倍。
6、进一步的,步骤s100中,所述聚类算法采用k-means算法,通过k-means的计算公式为:
7、
8、
9、其中,centerk表示类别k的中心,表示t属于k类的概率,它由目标域数据通过源域数据预训练的模型而获得,而对于t来说它的伪标签yt是与它距离最近的聚类中心,ck表示类别k的中心,ft表示目标域某一样本映射于特征空间中的值。
10、进一步的,步骤s100中,所述双向匹配生成数据对的计算公式为:
11、
12、
13、p=ps∪pt
14、其中,ps是从源域s中挑选的任意一个元素s,与目标域t中距离它最近的元素t所构成的数据对的集合;pt是从目标域t中挑选的任意一个元素t,与源域s中距离它最近的元素s所构成的数据对的集合;ps和pt所取的并集正是双向匹配所生成的全部数据对;而后对比数据对的源域标签以及为目标域生成的伪标签,将两者不一致的数据对剔除数据集得到最终迁移学习所需的数据对。
15、进一步的,步骤s200具体包括如下步骤:
16、s210、将输入对中源域数据与目标域数据分别通过两个自注意力机制网络得到源域注意力得分与目标域注意力得分
17、s220、使用输入对利用交叉注意力机制计算混合注意力得分fusionscore;
18、s230、根据计算出的三个得分分别计算它们对应的交叉熵损失函数;
19、s240、将三者的损失函数累加获得总的损失函数,并通过随机梯度下降法来更新模型参数;
20、s250、在经过多次迭代后,直至模型在测试集上准确率达到95%及以上后,导出模型,利用模型对目标水域所采集的信号进行探测识别。
21、进一步的,步骤s210中,所述自注意力机制网络的计算公式为:
22、
23、其中,q,k,v分别为输入与随机初始化矩阵相乘之后得到的查询向量,键向量与值向量,dk为值向量k的维度,kt表示转置后的键向量,将查询向量与键向量相乘后除以值向量的维度的开平方,最后将其使用softmax函数进行归一化后得到注意力矩阵,然后使用注意力矩阵为值向量加权活得最终的注意力得分,通过上式对源域输入和目标域输入分别计算出两者得分记为与
24、进一步的,步骤s220中,所述交叉注意力机制的计算公式为:
25、
26、其中,qs为源域数据经过矩阵转换后得到的查询向量,而kt,vt为目标域数据对应的键向量与值向量,dk为值向量kt的维度,kt表示转置后目标域键向量,计算所得的交叉注意力得分记为fusionscore。
27、进一步的,步骤s230中,所述交叉熵损失函数的计算公式为:
28、
29、
30、
31、loss=losss+losst+lossdistill
32、其中,targets为源域每个样本对应的标签,pseudot为目标域样本生成的伪标签,源域损失、目标域损失与交叉损失的和是为总的损失,而后通过随机梯度下降法来更新参数。
33、进一步的,步骤s250中,所述的利用训练模型进行水下目标探测识别的具体步骤为:
34、1.利用声纳采集水下目标信号;
35、2.将采集的信号转化为梅尔谱图;
36、3.将梅尔谱图作为模型的输入;
37、4.模型输出探测识别的物体种类结果。
38、有益效果:与现有技术相比,本发明具有如下显著优点:和基于非迁移学习的水下目标探测识别技术相比,本发明能重复利用预训练的大模型,对不同海域无需重复训练大量数据,降低了生成模型的算力成本;和有监督的微调相比,本发明无需对目标域数据进行标注,降低了迁移的成本,从而可以更快应用于新场景中;另外利用交叉注意力机制解决了迁移中误配对的干扰问题,提高了模型的鲁棒性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21265.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表