一种基于网关的数据脱敏方法与流程
- 国知局
- 2024-06-21 11:26:26
本发明涉及数据脱敏的领域,尤其涉及一种基于网关的数据脱敏方法。
背景技术:
1、随着信息技术的不断发展和智能设备的广泛应用,敏感信息越来越容易被获取和滥用,通过网关对数据脱敏的技术应运而生,实现对隐私数据的保护,避免数据泄露。
2、中国专利公开号:cn116760588a,公开了如下内容,该发明涉及数据脱敏的领域,公开了一种数据脱敏系统及脱敏方法,数据脱敏系统包括:网关、至少一个业务微服务以及鉴权中心微服务,所述业务微服务与所述网关通信连接,所述鉴权中心微服务与所述网关通信连接;所述网关被配置为能够接收用户的脱敏处理请求并根据所述脱敏处理请求向鉴权中心微服务查询脱敏规则,然后判断有无脱敏规则;若有,则执行脱敏规则并响应客户;若无,则直接相应客户;通过在网关统一处理脱敏,避免了各业务微服务繁重的脱敏逻辑开发,也无需为微服务之间的调用与用户调用分别开发两套逻辑,达到了减少工作量、降低成本,易于维护性的效果。
3、但是,现有技术中,还存在以下问题:
4、在现有技术中,在对语音进行脱敏时,若实际发音与违禁词的音调不同,将语音转换成文本语句进行脱敏时容易发生误判,脱敏效果差,现有的脱敏方法未考虑上述因素,根据转换成的文本语句的特征自适应调整脱敏的方法,提高脱敏效果。
技术实现思路
1、为此,本发明提供一种基于网关的数据脱敏方法,用以克服现有技术中,在对语音进行脱敏时,若实际发音与违禁词的音调不同,将语音转换成文本语句进行脱敏时容易发生误判,现有的脱敏方法未考虑上述因素自适应调整脱敏的方法的问题。
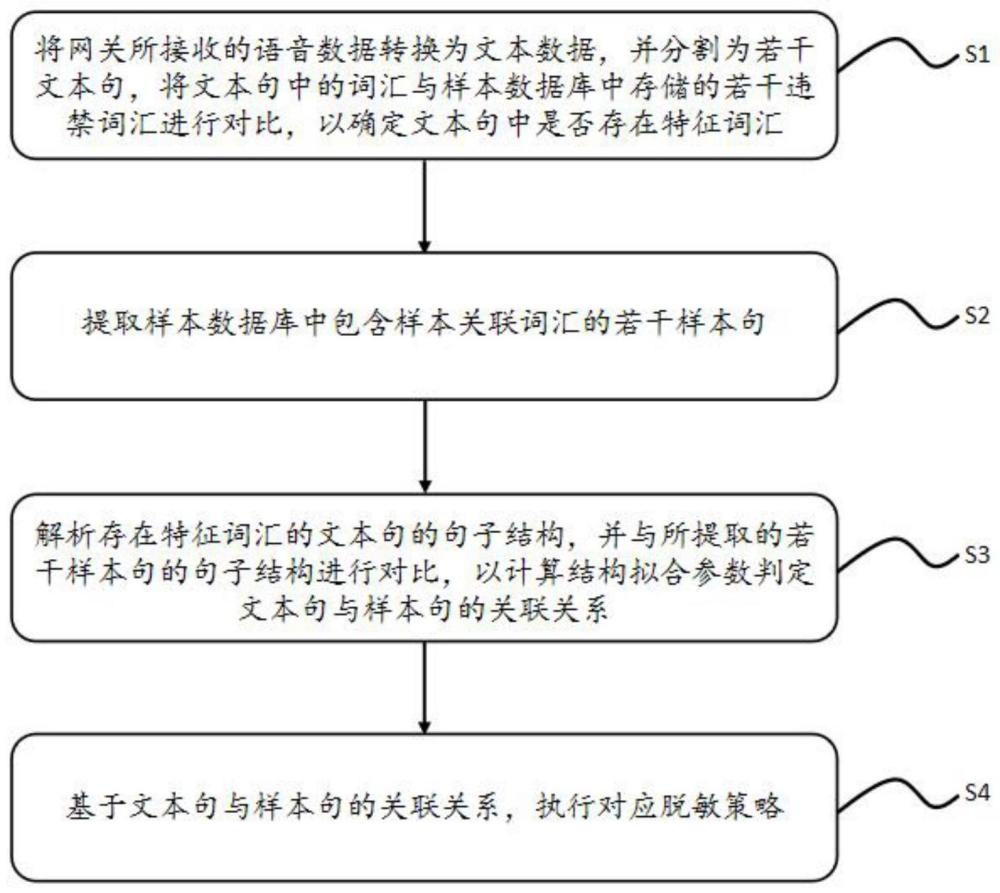
2、为实现上述目的,本发明提供一种基于网关的数据脱敏方法,其包括:
3、步骤s1,将网关所接收的语音数据转换为文本数据,并分割为若干文本句,将文本句中的词汇与样本数据库中存储的若干违禁词汇进行对比,以确定文本句中是否存在特征词汇;
4、步骤s2,提取样本数据库中包含样本关联词汇的若干样本句,所述样本关联词汇为与特征词汇拼音特征相同的违禁词汇;
5、步骤s3,解析存在特征词汇的文本句的句子结构,并与所提取的若干样本句的句子结构进行对比,以计算结构拟合参数判定所述文本句与样本句的关联关系;
6、步骤s4,基于所述文本句与样本句的关联关系,执行对应脱敏策略,包括,
7、分析特征词汇与剩余语句的语义关联度,在语义关联度小于预定标准时对所述文本句进行脱敏;
8、或,确定所述文本句中的非特征词汇,并与所提取的各所述样本句进行对比,根据所述文本句中各所述非特征词汇与各所述样本句的关联度计算关联表征值,以判定所述特征词汇是否为违禁词汇,并在判定所述特征词汇为违禁词汇时对所述文本句进行脱敏。
9、进一步地,在所述步骤s1中,基于文本句中的词汇与样本数据库中存储的若干违禁词汇的对比结果确定所述文本句中是否存在特征词汇的过程包括,
10、若样本数据库中存在违禁词汇与所述文本句中的词汇的拼音特征相同,则确定所述文本句中存在特征词汇。
11、进一步地,在所述步骤s3中,基于存在特征词汇的文本句的句子结构与所提取的若干样本句的句子结构的对比结果计算结构拟合参数的过程包括,
12、确定所提取的若干样本句中特征样本句的数量,将所述特征样本句的数量与所提取的样本句的数量的比值确定为结构拟合参数,所述特征样本句为与存在特征词汇的文本句的句子结构相同的样本句。
13、进一步地,在所述步骤s3中,基于所述结构拟合参数判定所述文本句与样本句的关联关系的过程包括,
14、将所述结构拟合参数与预设的拟合对比阈值进行对比,
15、若所述结构拟合参数大于等于所述拟合对比阈值,则判定所述文本句与样本句的关联关系为强关联关系;
16、若所述结构拟合参数小于所述拟合对比阈值,则判定所述文本句与样本句的关联关系为弱关联关系。
17、进一步地,在所述步骤s4中,基于所述文本句与样本句的关联关系判定执行的脱敏策略的过程包括,
18、若判定所述文本句与样本句的关联关系为强关联关系,则分析特征词汇与剩余语句的语义关联度,在语义关联度小于预定标准时对所述文本句进行脱敏;
19、若判定所述文本句与样本句的关联关系为弱关联关系,则确定所述文本句中除所述特征词汇外剩余的若干词汇,并与所提取的各所述样本句进行对比,以计算所述文本句与所提取的各所述样本句对应的若干关联表征值,以基于各所述关联表征值中的最大值判定所述特征词汇是否为违禁词汇,并在判定所述特征词汇为违禁词汇时对所述文本句进行脱敏。
20、进一步地,在所述步骤s4中,对所述文本句进行脱敏的过程包括将所述文本句对应的语音数据删除。
21、进一步地,根据所述文本句中各所述非特征词汇与样本句的语义关联度计算关联表征值的过程包括,
22、计算各所述文本句中各所述非特征词汇与样本句的语义关联度,将关联度平均值确定为关联表征值。
23、进一步地,在所述步骤s4中,基于各所述关联表征值中的最大值判定所述特征词汇是否为违禁词汇的过程包括,
24、确定各所述关联表征值中的最大值,将所述最大值与预设的关联表征对比阈值进行对比,
25、若所述最大值大于等于所述关联表征对比阈值,则判定所述特征词汇为违禁词汇。
26、进一步地,在所述步骤s4中还包括,在需要进行脱敏的文本句的数量与文本数据中文本句的数量的比值超过预定比例时发出警示消息,以警示所接收的语音数据异常。
27、进一步地,在所述步骤s1中,所述网关单次所接收的语音数据的数据量不超过预定数据量阈值。
28、与现有技术相比,本发明通过将网关所接收的语音数据转换为文本数据,并分割为若干文本句,将文本句中的词汇与样本数据库中存储的若干违禁词汇进行对比,以确定文本句中是否存在特征词汇,提取样本数据库中包含样本关联词汇的若干样本句,解析存在特征词汇的文本句的句子结构,并与所提取的若干样本句的句子结构进行对比,以计算结构拟合参数判定文本句与样本句的关联关系,基于文本句与样本句的关联关系,执行对应脱敏策略,通过上述过程考虑实际发音与违禁词的音调不同时脱敏效果差的问题,自适应调整脱敏的方法,提高网关对数据的脱敏效果。
29、尤其,本发明中,将文本句中的词汇与样本数据库中存储的若干违禁词汇进行对比,以确定文本句中是否存在特征词汇,在实际情况中,在将语音数据转换为文本数据时受语音数据的音调等因素的影响,因此所转换成的文本数据是与语音数据具有相同拼音特征的文本句,因此,将文本句中的词汇与样本数据库中存储的若干违禁词汇进行对比,确定出文本句中与样本数据库中的违禁词汇的拼音特征相同的词汇,即特征词汇,便于后续对存在特征词汇的文本句进行特定的处理,以提高网关的脱敏效果。
30、尤其,本发明中,计算结构拟合参数判定文本句与样本句的关联关系,结构拟合参数表征了存在特征词汇的文本句的句子结构与所提取的若干样本句的句子结构的相似程度,在实际情况中,两个句子的句子结构相似程度较高,意味着它们具有较相似的语法结构,因此两个句子所表达的意思就具有较高的相似度,即文本句与样本句的关联关系越强,因此,本发明根据结构拟合参数将文本句与样本句的关联关系进行分类,以针对关联关系的强弱进行对应的脱敏策略,提高了网关对数据进行脱敏的效果。
31、尤其,本发明中,若判定文本句与样本句的关联关系为强关联关系,则分析特征词汇与剩余语句的语义关联度,在语义关联度小于预定标准时对文本句进行脱敏,强关联关系表征了文本句与样本句所表达的意思具有较高的相似度,在实际情况中,此时如果特征词汇与剩余语句的语义关联度较小,即搭配不合理,则可表明特征词汇是违禁词汇,因此在语义关联度小于预定标准时对文本句进行脱敏。
32、尤其,本发明中,若判定文本句与样本句的关联关系为弱关联关系,则计算文本句与所提取的各样本句对应的若干关联表征值,基于各关联表征值中的最大值判定特征词汇是否为违禁词汇,在判定特征词汇为违禁词汇时对文本句进行脱敏,弱关联关系表征了文本句与样本句所表达的意思具有较低的相似度,不能确定特征词汇是否为违禁词汇,在这种情况下,需要对文本句进行进一步地判定,本发明中的关联表征值可表明文本句的非特征关键词与样本句的关联程度,若各关联表征值中的最大值高于预设的关联表征对比阈值,即可表明特征词汇是违禁词汇,通过上述过程在不能确定特征词汇是否为违禁词汇的情况下,对文本句进行进一步判定,提高了通过网关进行数据脱敏的效果。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21537.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表