一种语音情感识别方法、装置、电子设备和存储介质与流程
- 国知局
- 2024-06-21 11:26:12
本公开涉及计算机,尤其涉及一种语音情感识别方法、装置、电子设备和存储介质。
背景技术:
1、语音是日常生活中交流的主要媒介,它不仅传达了思想,还表达了说话人的情感状态,情感交互在人类信息的沟通中有着重要的意义。随着人工智能技术的不断发展,情感识别技术是人机交互的基础性技术之一,目前,研究者正致力于研究通过人工智能技术来识别语音中说话人的情绪,语音情感识别可以检测用户的心理健康,以及在不同的场景(例如,数字人、客服)对用户或客服的情感变化进行对应的反馈和回复等。情感识别也利于家长关注孩子的心理健康等指标,通过学习和识别声音中存在的焦虑、兴奋、愤怒等情感,实现更加个性化的交流。
2、在语音情感识别的过程中,通常会对一段短音频进行情感识别,并且预测出这段音频对应的情感类别,例如愤怒,高兴,平静等。对于长音频的场景,例如电话、节目访谈、视频质检等,通常也是将长音频按一定的时长(例如5s)或者通过话音激活检测(vad,voiceactivity detection)对音频进行切分,然后利用短句的语音情感识别模型进行情感分类的识别。
3、然而在相关技术中,语音情感识别的准确性较低。
技术实现思路
1、本公开提出了一种语音情感识别技术方案。
2、根据本公开的一方面,提供了一种语音情感识别方法,包括:
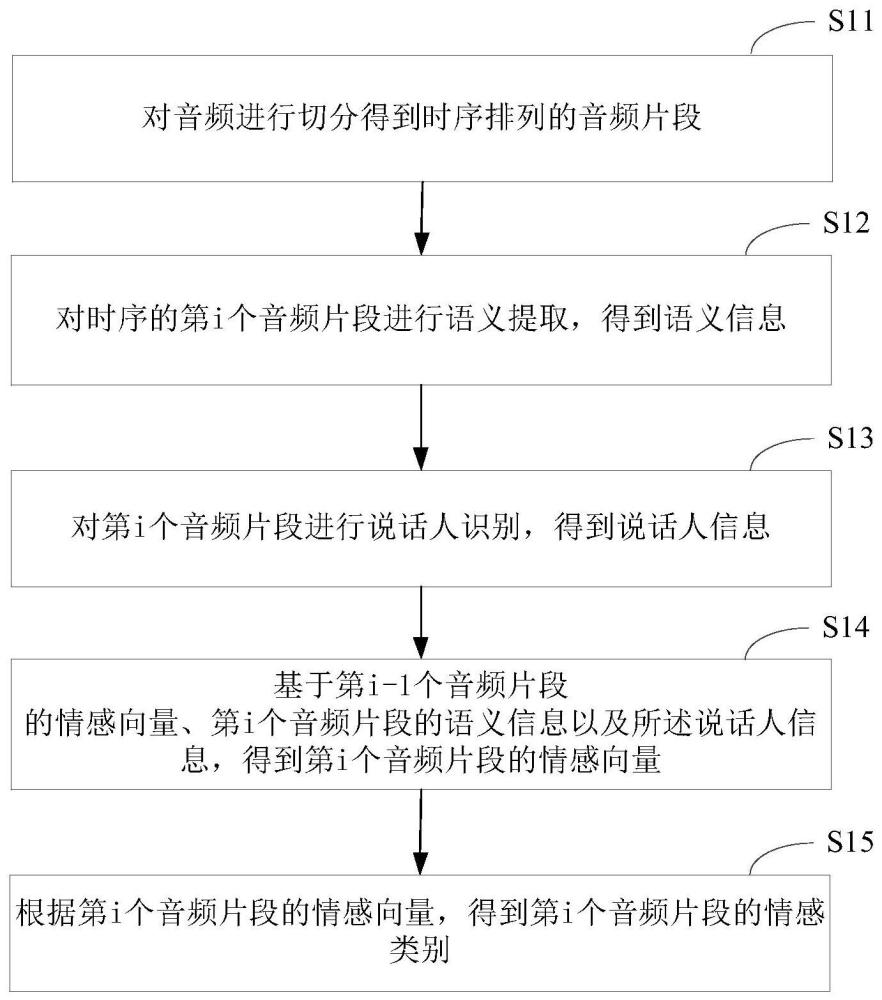
3、对音频进行切分得到时序排列的音频片段;
4、对时序的第i个音频片段进行语义提取,得到语义信息,其中,所述语义信息中融合了前i-1个视频片段的语义信息,i为大于1的正整数;
5、对第i个音频片段进行说话人识别,得到说话人信息;
6、基于第i-1个音频片段的情感向量、第i个音频片段的语义信息以及所述说话人信息,得到第i个音频片段的情感向量;
7、根据第i个音频片段的情感向量,得到第i个音频片段的情感类别。
8、在一种可能的实现方式中,所述对时序的第i个音频片段进行语义提取,得到语义信息,包括:
9、对时序的第i个音频片段进行语音识别,得到文本信息;
10、基于时序的连续多个音频片段的文本信息,进行基于上下文的语义提取,得到第i个音频片段的语义信息,所述连续多个音频片段包含第i个音频片段。
11、在一种可能的实现方式中,所述对时序的第i个音频片段进行语义提取,得到语义信息,包括:
12、对时序的第i个音频片段进行语音识别,得到文本信息;
13、基于时序的连续多个音频片段的文本信息,进行基于上下文的语义提取,得到第i个音频片段的文本信息中各词的词嵌入;
14、对各词嵌入进行基于自注意力机制的特征融合,得到融合特征,作为第i个音频片段的语义信息。
15、在一种可能的实现方式中,所述基于第i-1个音频片段的情感向量、第i个音频片段的语义信息以及所述说话人信息,得到第i个音频片段的情感向量,包括:
16、基于第i-1个音频片段的情感向量、第i个音频片段的语义信息以及所述说话人信息,对第i个音频片段进行基于自注意力机制的特征提取,得到第i个音频片段的情感向量。
17、在一种可能的实现方式中,所述基于第i-1个音频片段的情感向量、第i个音频片段的语义信息以及所述说话人信息,对第i个音频片段进行基于自注意力机制的特征提取,得到第i个音频片段的情感向量,包括:
18、对第i个音频片段进行基于自注意力机制的特征提取,得到中间参数向量,所述中间参数向量包括:查询向量、键向量和值向量;
19、将第i-1个音频片段的情感向量、第i个音频片段的语义信息以及所述说话人信息,分别融合到所述键向量和值向量中,得到融合键向量和融合值向量;
20、基于所述查询向量、所述融合键向量和所述融合值向量,确定第i个音频片段的情感向量。
21、在一种可能的实现方式中,所述方法基于神经网络模型实现,所述神经网络模型的训练方法包括:
22、获取样本音频,所述样本音频中包含时序的多个样本音频片段;
23、将所述样本音频输入所述神经网络模型,以对样本音频中的第i个样本音频片段进行语义提取,得到融合了前i-1个样本音频片段语义的语义信息;对第i个样本音频片段进行说话人识别,得到说话人信息;基于第i-1个样本音频片段的情感向量、第i个样本音频片段的语义信息以及所述说话人信息,得到第i个样本音频片段的情感向量;根据第i个样本音频片段的情感向量,得到第i个样本音频片段的预测情感类别;
24、基于预测情感类别和标注情感类别之间的损失,对神经网络模型中的参数进行调整。
25、在一种可能的实现方式中,所述获取样本音频,包括:
26、对音频文件进行切分,得到多个样本音频片段,并标注各样本音频片段的情感类别;
27、随机获取连续的多个样本音频片段,作为样本音频。
28、根据本公开的一方面,提供了一种语音情感识别装置,包括:
29、切分单元,用于对音频进行切分得到时序排列的音频片段;
30、语义提取单元,用于对时序的第i个音频片段进行语义提取,得到语义信息,其中,所述语义信息中融合了前i-1个视频片段的语义信息,i为大于1的正整数;
31、说话人识别单元,用于对第i个音频片段进行说话人识别,得到说话人信息;
32、情感向量确定单元,用于基于第i-1个音频片段的情感向量、第i个音频片段的语义信息以及所述说话人信息,得到第i个音频片段的情感向量;
33、情感类别确定单元,用于根据第i个音频片段的情感向量,得到第i个音频片段的情感类别。
34、在一种可能的实现方式中,所述语义提取单元,用于:
35、对时序的第i个音频片段进行语音识别,得到文本信息;
36、基于时序的连续多个音频片段的文本信息,进行基于上下文的语义提取,得到第i个音频片段的语义信息,所述连续多个音频片段包含第i个音频片段。
37、在一种可能的实现方式中,所述语义提取单元,用于:
38、对时序的第i个音频片段进行语音识别,得到文本信息;
39、基于时序的连续多个音频片段的文本信息,进行基于上下文的语义提取,得到第i个音频片段的文本信息中各词的词嵌入;
40、对各词嵌入进行基于自注意力机制的特征融合,得到融合特征,作为第i个音频片段的语义信息。
41、在一种可能的实现方式中,所述情感向量确定单元,用于基于第i-1个音频片段的情感向量、第i个音频片段的语义信息以及所述说话人信息,对第i个音频片段进行基于自注意力机制的特征提取,得到第i个音频片段的情感向量。
42、在一种可能的实现方式中,所述所述情感向量确定单元,用于:
43、对第i个音频片段进行基于自注意力机制的特征提取,得到中间参数向量,所述中间参数向量包括:查询向量、键向量和值向量;
44、将第i-1个音频片段的情感向量、第i个音频片段的语义信息以及所述说话人信息,分别融合到所述键向量和值向量中,得到融合键向量和融合值向量;
45、基于所述查询向量、所述融合键向量和所述融合值向量,确定第i个音频片段的情感向量。
46、在一种可能的实现方式中,所述方法基于神经网络模型实现,所述神经网络模型的训练装置包括:
47、样本获取单元,用于获取样本音频,所述样本音频中包含时序的多个样本音频片段;
48、训练单元,用于将所述样本音频输入所述神经网络模型,以对样本音频中的第i个样本音频片段进行语义提取,得到融合了前i-1个样本音频片段语义的语义信息;对第i个样本音频片段进行说话人识别,得到说话人信息;基于第i-1个样本音频片段的情感向量、第i个样本音频片段的语义信息以及所述说话人信息,得到第i个样本音频片段的情感向量;根据第i个样本音频片段的情感向量,得到第i个样本音频片段的预测情感类别;
49、调整单元,用于基于预测情感类别和标注情感类别之间的损失,对神经网络模型中的参数进行调整。
50、在一种可能的实现方式中,所述样本获取单元,用于:
51、对音频文件进行切分,得到多个样本音频片段,并标注各样本音频片段的情感类别;
52、随机获取连续的多个样本音频片段,作为样本音频。
53、根据本公开的一方面,提供了一种电子设备,包括:处理器;用于存储处理器可执行指令的存储器;其中,所述处理器被配置为调用所述存储器存储的指令,以执行上述方法。
54、根据本公开的一方面,提供了一种计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现上述方法。
55、在本公开实施例中,通过对音频进行切分得到时序排列的音频片段;对时序的第i个音频片段进行语义提取,得到的语义信息中融合了前i-1个视频片段的语义信息;对第i个音频片段进行说话人识别,得到说话人信息;基于第i-1个音频片段的情感向量、第i个音频片段的语义信息以及所述说话人信息,得到第i个音频片段的情感向量;根据第i个音频片段的情感向量,得到第i个音频片段的情感类别。由此,通过多种模态的历史信息表征(语义历史信息表征、语音情感历史信息表征和当前说话人向量)来辅助当前音频片段进行语音情感识别,可以有效地提升长音频语音情感识别场景的准确率。
56、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,而非限制本公开。根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21515.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。