一种自动评价个人情绪和语音匹配度的方法与流程
- 国知局
- 2024-06-21 11:26:07
本发明涉及人工智能,具体为一种自动评价个人情绪和语音匹配度的方法。
背景技术:
1、个人情绪和语音的匹配度一般用在人物/演员表演、配音相关的领域,市面上的部分配音软件一般是通过文字转语音进行ai配音,这些配音仅限于根据文字生成语音,一般不包括发音、嘴型、面部肌肉的走向等相关特征匹配,极个别的软件可以进行嘴型的匹配,但一般属于动画领域。
2、而牵涉到真人人物音视频时,其中,部分视频存在个人情绪与语音匹配度较差的情况,对于这些情况一般是通过人工对其个人情绪与语音的匹配度进行评价,这样,则存在工作量较大,不同评价人对个人情绪与语音的匹配度评定标准存在差异,且准确性容易受到不同评价人的主观因素影响。
3、为此我们提出一种自动评价个人情绪和语音匹配度的方法用于解决上述问题。
技术实现思路
1、本发明的目的在于提供一种自动评价个人情绪和语音匹配度的方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种自动评价个人情绪和语音匹配度的方法,包括以下步骤:
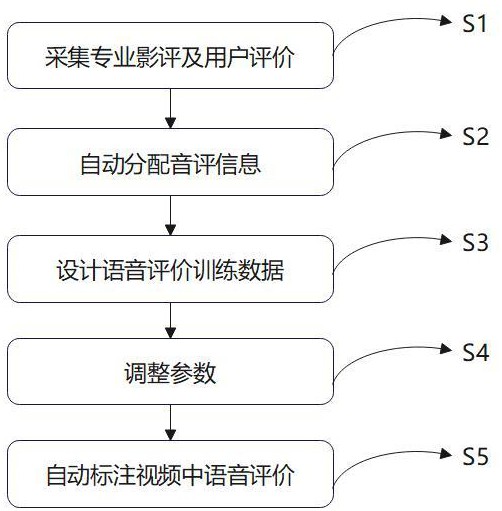
3、s1:采集专业影评及用户评价,通过网络对带有专业影评和用户评价的音视频进行采集;
4、s2:自动分配音评信息,对同一个音视频下的专业影评、用户评价中关键词进行提取,并根据关键词的词性进行等级划分,等级划分为第一等级、第二等级和第三等级,按照等级划分对音视频进行自动分配;
5、s3:设计语音评价训练数据,获取处于第一等级内多个音视频的第一相关度;将其中第一相关度最高的音视频记为第一音视频,将其相关度记为旧第一相关度,将第一音视频中提取的第一特征的特征因子、第二特征的特征因子以及其对应的评价记为数据a,对数据a进行保存;
6、s4:调整参数,输入符合s1和s2的新音视频,记为第二音视频,将第二音视频进行s3的训练,得到新第一相关度,将第二音视频中提取的第一特征的特征因子、第二特征的特征因子以及其对应的评价记为数据b;根据数据b对数据a进行调整;
7、s5:自动标注视频中语音评价,通过输入新音视频,将其记为第三音视频,对第三音视频进行第一相关度的提取,根据其第一相关度与s3中的第一相关度的关系对语音评价的相关度进行获取,即可将对应的评价自动标注在第三音视频上。
8、优选的,在所述s1中,所述通过网络采集的带有专业影评和用户评价的音视频具有以下特征:
9、 t1、音视频中需同时出现人物和人物语音;
10、 t2、音视频下的专业影评和用户评价的总量需大于等于100条;
11、 t3、音视频中人物的微表情、人物语音要清晰、音视频的时长需大于20秒。
12、优选的,在所述s2中,对同一个音视频下的专业影评、用户评价中关键词提取的步骤包括:
13、a1、对同一音视频对应的专业影评和用户评价中关于评价个人情绪(演员表演)关键词和评价人物语音(配音)关键词进行提取;
14、a2、对同一音视频对应的评价个人情绪(演员表演)关键词和评价人物语音(配音)关键词出现的频率由高到低进行排序;
15、a3、对同一音视频对应的评价个人情绪(演员表演)关键词和评价人物语音(配音)关键词所在的语句与关键词频率最高的语句进行重合度比对;
16、a4、将重合度大于97%的关键词所在语句定义为无效语句,对其进行删除。
17、优选的,在所述s2中,将个人情绪(演员表演)较好、人物语音(配音)好的评价数占总评论数的比值大于95%的定位第一等级;将个人情绪(演员表演)一般、未提及人物语音(配音)的评价数占总评论数的比值大于50%的定为第二等级;将带有个人情绪(演员表演)差、人物语音(配音)不贴合以及存在违和感的评价数占总评论数的比值大于40%定为第三等级,在所述s2中,所述个人情绪(演员表演)和语音(配音)关键词的词性可分为褒义词、中性词、贬义词,其中,褒义词、中性词、贬义词分别与第一等级、第二等级、第三等级对应。
18、优选的,在所述s3中,通过深度神经卷积网络将同一音视频中个人情绪(演员表演)的特征进行提取,记为第一特征,通过深度神经卷积网络将同一音视频中人物语音(配音)的特征进行提取,记为第二特征,其中,第一特征的特征因子可包括性格、嘴型、动作、眼神、面部肌肉走向,第二特征的特征因子包括人物语音(配音)的声量、音色、语调、声音的起始点与结束点、语速,第一相关度即同一音视频中第一特征和第二特征的匹配度(个人情绪和语音的匹配度)。
19、优选的,在所述s4中,若新第一相关度数值大于旧第一相关度数值,则根据数据b对s3中的数据a进行调整,若新第一相关度数值小于等于旧第一相关度数值,则对s3中的数据a不调整。
20、优选的,在所述s4中,对所述第二音视频进行周期性的增加。
21、优选的,在所述s5中,所述第三音视频的第一相关度在85-100之间的范围选用第一等级内的评价,所述第三音视频的第一相关度在40-84之间的范围选用第二等级内的评价,所述第三音视频的第一相关度在0-39之间的范围选用第三等级内的评价。
22、优选的,在所述s5中,在对同一等级内的评价进行选用时,优先选用出现频率较高的评价。
23、优选的,在所述s5中,通过爬虫对单位时间内新增的专业影评和用户评价中的高频词汇进行收集,若高频词汇与关键词词意相同,即可将高频词汇对所述s2中的关键词进行替换。
24、与现有技术相比,本发明的有益效果是:
25、1.能够自动评价音视频中个人情绪与语音的匹配度,并提高其评价匹配度的准确性,能够节省人工评价音视频所需要的时间,避免人工评价可能产生的误差,准确性高,具有同一音视频中个人情绪和语音匹配度的评定误差小的优点;
26、2.能够降低网络水军刷屏对专业影评和用户评价的影响,通过对专业影评和用户评价不进行区分,能够使得评价匹配度更贴合大众的评价结果,增加大众对匹配度评价结果的认同度;
27、3.能够对新的音视频进行评价的自动标注,节省大量人工评价标注音视频所需要的工作量,能够对语音评价进行实时更新,使语音评价与时俱进。
技术特征:1.一种自动评价个人情绪和语音匹配度的方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种自动评价个人情绪和语音匹配度的方法,其特征在于:在所述s1中,所述通过网络采集的带有专业影评和用户评价的音视频具有以下特征:
3.根据权利要求1所述的一种自动评价个人情绪和语音匹配度的方法,其特征在于:在所述s2中,对同一个音视频下的专业影评、用户评价中关键词提取的步骤包括:
4.根据权利要求1所述的一种自动评价个人情绪和语音匹配度的方法,其特征在于:在所述s2中,将个人情绪较好、人物语音好的评价数占总评论数的比值大于95%的定位第一等级;将个人情绪一般、未提及人物语音的评价数占总评论数的比值大于50%的定为第二等级;将带有个人情绪差、人物语音不贴合以及存在违和感的评价数占总评论数的比值大于40%的定为第三等级。
5.根据权利要求1所述的一种自动评价个人情绪和语音匹配度的方法,其特征在于:在所述s3中,通过深度神经卷积网络将同一音视频中个人情绪的特征进行提取,记为第一特征,通过深度神经卷积网络将同一音视频中人物语音的特征进行提取,记为第二特征。
6.根据权利要求1所述的一种自动评价个人情绪和语音匹配度的方法,其特征在于:在所述s4中,若新第一相关度数值大于旧第一相关度数值,则根据数据b对s3中的数据a进行调整,若新第一相关度数值小于等于旧第一相关度数值,则对s3中的数据a不调整。
7.根据权利要求1所述的一种自动评价个人情绪和语音匹配度的方法,其特征在于:在所述s4中,对所述第二音视频进行周期性的增加。
8.根据权利要求1所述的一种自动评价个人情绪和语音匹配度的方法,其特征在于:在所述s5中,所述第三音视频的第一相关度在85-100之间的范围选用第一等级内的评价,所述第三音视频的第一相关度在40-84之间的范围选用第二等级内的评价,所述第三音视频的第一相关度在0-39之间的范围选用第三等级内的评价。
9.根据权利要求8所述的一种自动评价个人情绪和语音匹配度的方法,其特征在于:在所述s5中,在对同一等级内的评价进行选用时,优先选用出现频率较高的评价。
10.根据权利要求1所述的一种自动评价个人情绪和语音匹配度的方法,其特征在于:在所述s5中,通过爬虫对单位时间内新增的专业影评和用户评价中的高频词汇进行收集,若高频词汇与关键词词意相同,即可将高频词汇对所述s2中的关键词进行替换。
技术总结本发明公开了人工智能技术领域的一种自动评价个人情绪和语音匹配度的方法,包括以下步骤,S1:采集专业影评及用户评价,通过网络对带有专业影评和用户评价的音视频进行采集;S2:自动分配音评信息,对同一个音视频下的专业影评、用户评价中关键词进行提取,并根据关键词的词性进行等级划分,等级划分为第一等级、第二等级和第三等级,按照等级划分对音视频进行自动分配;S3:设计语音评价训练数据;本发明能够自动评价音视频中个人情绪与语音的匹配度,并提高其评价匹配度的准确性,能够节省人工评价音视频所需要的时间,准确性高;能够使得评价匹配度更贴合大众的评价结果,增加大众对评价结果的认同度。技术研发人员:刘迎春,刘珏廷,林果园受保护的技术使用者:江苏慧言智语安全科技有限公司技术研发日:技术公布日:2024/2/6本文地址:https://www.jishuxx.com/zhuanli/20240618/21502.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表