数据标注方法、装置和语音识别方法、装置与流程
- 国知局
- 2024-06-21 11:28:12
本公开涉及计算机,特别涉及一种数据标注方法、数据标注装置、语音识别方法、语音识别装置、电子设备和非易失性计算机可读存储介质。
背景技术:
1、目前,随着人工智能技术的高速发展,以chatgpt为代表的通用聊天机器人程序呈现出了巨大的应用潜力。asr(automatic speech recognition,自动语音识别)技术旨在将一段说话人的音频转写为对应的文字,是通用聊天机器人系统最重要的信息交互入口之一。
2、然而,在许多实际的语音交互场景应用中,待识别的语音中可能存在发音不准、语速多变、方言口音、背景噪音、远场混响等多种干扰因素,给asr模型的泛化性能和通用性能提出了新的挑战。
3、为了进一步提高asr模型的性能,最有效的途径之一便是丰富asr模型训练过程中所使用的标注数据。通常情况下,满足应用需求的asr模型的训练集包括数万小时(甚至更多)的语音标注数据,其中每一个标注数据由一段音频和对应内容的文本对组成。
4、在相关技术中,主要通过人工方式,对数据进行标注。
技术实现思路
1、本公开的发明人发现上述相关技术中存在如下问题:数据标注的人工成本高、效率低。
2、鉴于此,本公开提出了一种数据标注技术方案,能够降低数据标注的人工成本,提高数据标注的效率。
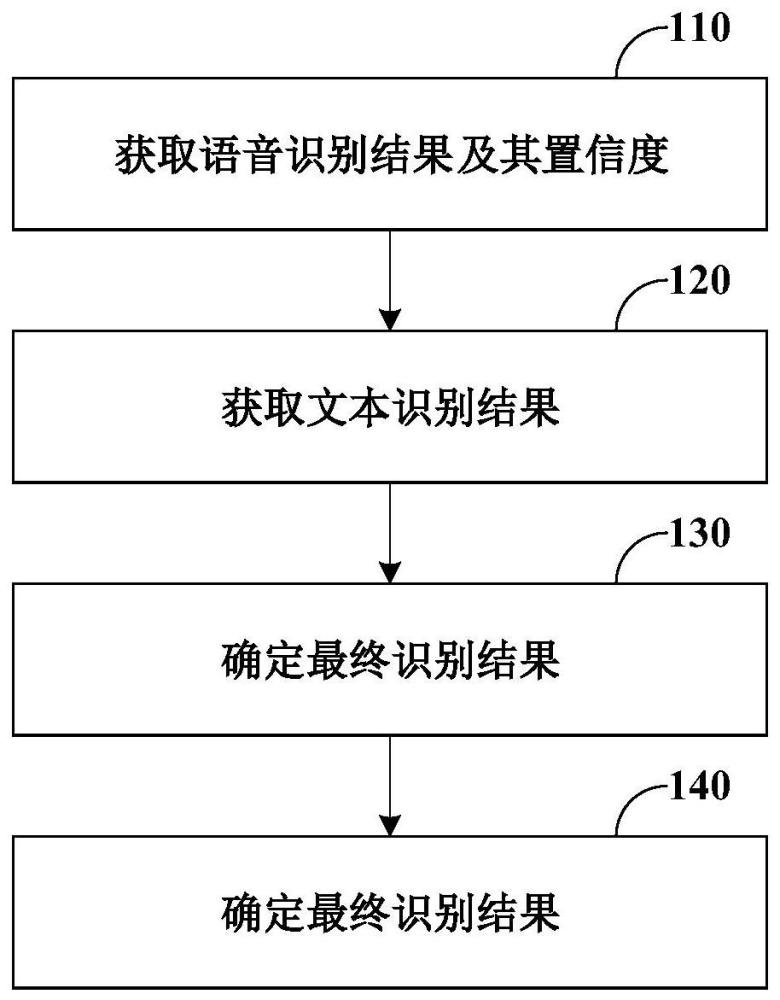
3、根据本公开的一些实施例,提供了一种数据标注方法,包括:利用语音识别模型,对视频的音频流数据进行语音识别,以获取语音识别结果和语音识别结果的置信度;利用文本识别模型,对视频的字幕区域进行文本识别,以获取文本识别结果;根据置信度,对语音识别结果与文本识别结果进行融合处理,以确定最终识别结果;根据最终识别结果,对音频流数据进行标注。
4、在一些实施例中,对语音识别结果与文本识别结果进行融合处理包括:根据语音识别结果与文本识别结果之间差异的程度和置信度,对语音识别结果与文本识别结果进行融合处理。
5、在一些实施例中,对语音识别结果与文本识别结果进行融合处理包括:根据置信度和差异的程度,确定将语音识别结果或者文本识别结果作为候选识别结果;对候选识别结果进行校正,以确定最终识别结果。
6、在一些实施例中,确定将语音识别结果或者文本识别结果作为候选识别结果包括:在置信度大于第一置信度阈值且差异的程度小于差异阈值的情况下,根据差异的类型,确定将语音识别结果或者文本识别结果作为候选识别结果。
7、在一些实施例中,确定将语音识别结果还是文本识别结果作为候选识别结果包括:在差异包括的插入类差异的数量小于或等于数量阈值的情况下,将文本识别结果作为候选识别结果,插入类差异用于表征语音识别结果中包括文本识别结果中不存在的字符。
8、在一些实施例中,确定将语音识别结果还是文本识别结果作为候选识别结果包括:在差异包括的插入类差异的数量大于数量阈值且置信度大于第二置信度阈值的情况下,将语音识别结果作为候选识别结果,插入类差异用于表征语音识别结果中包括文本识别结果中不存在的字符,第二置信度阈值大于第一置信度阈值。
9、在一些实施例中,确定最终识别结果包括:在差异的程度大于或等于差异阈值且置信度大于第二置信度阈值的情况下,将语音识别结果确定为最终识别结果,第二置信度阈值大于第一置信度阈值。
10、在一些实施例中,对候选识别结果进行校正包括:建立语音识别结果中多个语音识别词中的每一个与文本识别结果中多个文本识别词中的每一个之间的对应关系;根据对应关系,对候选识别结果进行校正。
11、在一些实施例中,对候选识别结果进行校正包括:在将语音识别结果作为候选识别结果,且具有对应关系的第一语音识别词和第一文本识别词包含的字符不同的情况下,利用第一文本识别词校正第一语音识别词;在将文本识别结果作为候选识别结果,且具有对应关系的第二语音识别词和第二文本识别词包含的字符不同的情况下,利用第二语音识别词校正第二文本识别词。
12、在一些实施例中,对候选识别结果进行校正包括:在将语音识别结果作为候选识别结果的情况下,利用形近字数据样本,对候选识别结果进行校正,形近字数据样本包括形状的相似程度超过第一阈值的字符之间的对应关系;在将文本识别结果作为候选识别结果的情况下,利用音近字数据样本,对候选识别结果进行校正,音近字数据样本包括读音的相似程度超过第二阈值的字符之间的对应关系。
13、在一些实施例中,差异的程度包括在文本识别结果中与语音识别结果不同的部分占文本识别结果的比例信息。
14、在一些实施例中,视频包括多个图像帧,多个图像帧中的每一个具有至少一个字幕区域,对视频的字幕区域进行文本识别,以获取文本识别结果包括:根据多个图像帧中的每一个具有的至少一个字幕区域的位置信息,确定属于不同图像帧的字幕区域之间的关联关系;对具有关联关系的字幕区域中的文本识别结果片段,进行融合处理;根据融合处理的结果,获取文本识别结果。
15、在一些实施例中,确定多个图像帧中的每一个具有的至少一个字幕区域之间的关联关系包括:根据属于不同图像帧的字幕区域之间的交并比,确定关联关系。
16、在一些实施例中,对视频的音频流数据进行语音识别包括:对音频流数据中包含语音的音频片段进行语音识别;对视频的字幕区域进行文本识别包括:根据音频流数据的音频采样率和视频的图像流数据的图像采样率,确定与音频片段关联的图像流数据中的视频片段;对视频片段的字幕区域进行文本识别。
17、在一些实施例中,标注后的音频流数据用于训练语音识别模型。
18、根据本公开的另一些实施例,提供一种语音识别方法,包括:利用语音识别模型,对待识别音频进行语音识别,语音识别模型利用音频流数据进行训练,音频流数据通过上述任一个实施例中的数据标注方法进行标注。
19、根据本公开的又一些实施例,提供一种数据标注装置,包括:第一识别单元,用于利用语音识别模型,对视频的音频流数据进行语音识别,以获取语音识别结果和语音识别结果的置信度;第二识别单元,用于利用文本识别模型,对视频的字幕区域进行文本识别,以获取文本识别结果;确定单元,用于根据置信度,对语音识别结果与文本识别结果进行融合处理,以确定最终识别结果;标注单元,用于根据最终识别结果,对音频流数据进行标注。
20、根据本公开的再一些实施例,提供一种语音识别装置,包括:获取单元,用于获取待识别音频;识别单元,用于利用语音识别模型,对待识别音频进行语音识别,语音识别模型利用音频流数据进行训练,音频流数据通过上述任一个实施例中的数据标注方法进行标注。
21、根据本公开的又一些实施例,提供一种电子设备,包括:存储器;和耦接至存储器的处理器,处理器被配置为基于存储在存储器装置中的指令,执行上述任一个实施例中的数据标注方法或者语音识别方法。
22、根据本公开的再一些实施例,提供一种非易失性计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述任一个实施例中的数据标注方法或者语音识别方法。
23、在上述实施例中,利用预训练的文本识别模型和语音识别模型,分别对视频中的字幕和音频流数据进行识别,并根据置信度对两种识别结果进行融合,以实现音频流数据的标注。这样,能够自动进行数据标注,降低人工成本高,并提高标注效率。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21693.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表