一种基于半监督模型的声音检测方法
- 国知局
- 2024-06-21 11:28:30
本发明属于深度学习领域,具体涉及一种基于半监督模型的声音检测方法。
背景技术:
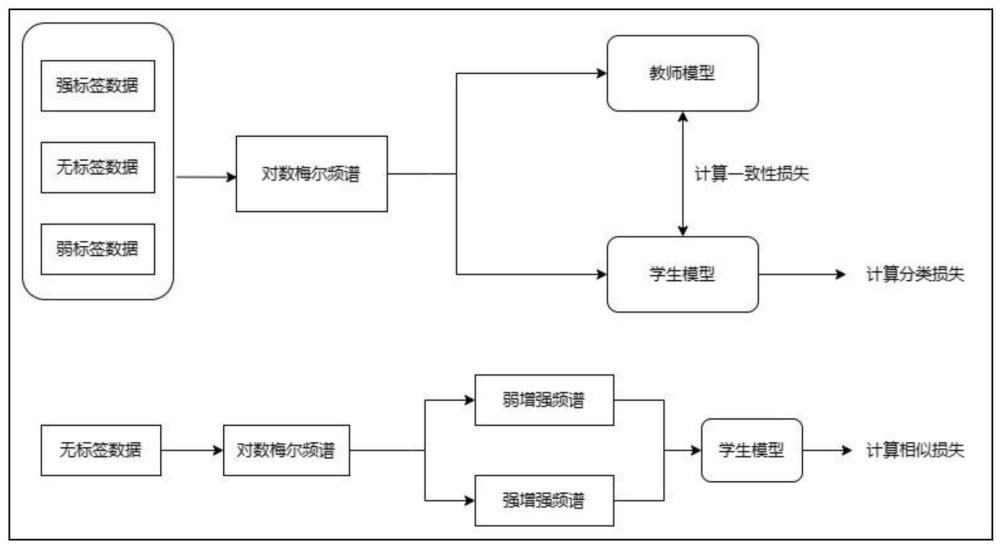
1、sed(sound event detection,声音事件检测)能够识别出一个音频段中存在的事件类别并标注出各事件的起止时间,所以声音事件检测任务可以分成两个子任务,第一是at(audio tagging,音频标记),第二是事件时间戳检测。该任务有三种数据集:10000个强标签音频片段、1578个弱标签音频片段,14412个无标签音频数据。对于强标签数据,每个音频除了包含有事件类别标签外还包含了事件的起止时间戳信息;对于弱标签数据,每个音频片段只包含事件类别标签,而没有事件的起止时间戳信息;对于无标签数据,每个音频既没有事件类别标签,也没有起止时间戳信息。
2、因此为了充分利用无标签数据,声音事件检测大多使用半监督模型。目前常用于声音事件检测的半监督模型是平均教师模型,平均教师模型包括教师模型分支和学生模型分支,两个分支是完全相同的crnn网络结构(convolutional recurrent neural network,crnn),这两个分支只是训练方式和模型参数不同,学生模型的参数是θt,用梯度下降法更新学生模型的参数,那么教师模型的参数θ′t=αθ′t-1+(1-α)θt,是学生参数的指数移动平均法(exponential moving average,ema)更新,即一部分权重来自历史的教师模型权重θ′t-1,另一部分来自于当前学生模型的权重θt。crnn是由cnn和rnn组成的混合模型,充分保留了cnn和rnn的优势,既可以提取特征图上面的显著性特征信息,又可以捕捉上下文的信息。其中cnn能够提取显著性特征信息,但无法获取长时间的上下文信息;而rnn能够捕捉长时间上下文的信息。两者可以互补,crnn经常被用于完成声音事件检测任务。
3、目前的平均教师模型包含两个损失函数:分类损失和一致性损失。
4、分类损失:分类损失是用来衡量学生模型的分类性能的,通过对学生模型的输出预测值和真实标签来计算,所以也称之为监督损失。分类损失还分为片段级别的分类损失和帧级别的分类损失,选择交叉熵损失函数(binary cross entropy,bce)。
5、一致性损失:一致性损失迫使学生模型和教师模型输出结果相同,选择均方误差损失函数(mean square error,mse)。
6、但是当前的一致性损失只强调了同一类别的同一样本的一致性,并不能很好地充分利用无标签数据。
技术实现思路
1、本发明所要解决的技术问题在于:针对现有技术中音频数据中的无标签数据利用不充分的问题,提供了一种基于半监督模型的声音检测方法,对于无标签数据,除了常用的一致性损失,还引入了相似损失,强调了同一类别的不同样本的一致性。使训练的模型更加精确。
2、为解决以上技术问题,本发明提供如下技术方案:一种基于半监督模型的声音检测方法,包括如下步骤:
3、s1、获取强标签音频数据、弱标签音频数据、以及无标签音频数据的对数梅尔频谱,对无标签音频数据的对数梅尔频谱进行预处理得到无标签音频数据的对数梅尔频谱对;
4、s2、针对无标签音频数据的对数梅尔频谱对进行弱增强策略、强增强策略,分别得到弱增强对数梅尔频谱对、强增强对数梅尔频谱对;
5、s3、以强标签音频数据对数梅尔频谱、弱标签音频数据对数梅尔频谱、无标签音频数据对数梅尔频谱、弱增强无标签对数梅尔频谱对、强增强无标签对数梅尔频谱对为输入、音频数据的类别和时间为输出,构建和训练教师模型和学生模型,并且在训练学生模型过程中,针对弱增强、强增强无标签对数梅尔频谱图的预测值进行相似损失计算,针对强标签、弱标签对数梅尔频谱图的预测值进行分类损失计算;同时计算教师模型和学生模型的一致性损失,最终得到半监督声音检测模型;
6、s4、将音频数据输入至半监督声音检测模型中,获得该音频数据的事件类别和事件对应的时间。
7、进一步地,前述的步骤s1具体为:对若干无标签音频数据进行快速傅里叶变换、求能量谱、使用128个滤波器提取梅尔频谱特征、取对数获得对数梅尔频谱,然后两两配对为对数梅尔频谱对(l,r)。
8、进一步地,前述的步骤s3中,教师模型和学生模型的网络架构是crnn结构。
9、进一步地,前述的步骤s2中弱增强策略、以及强增强策略是频率维度遮掩,获得弱增强对数梅尔频谱对(wl,wr)、强增强对数梅尔频谱对(sl,sr),具体为:沿频域轴方向的[f0,f0+f)范围内的连续频率通道进行掩蔽,其中0≤f0<v,v是通道数,f服从[0,f]均匀分布,f是频率遮掩参数。
10、进一步地,前述的一种基于半监督模型的声音检测方法,相似度损失计算包括以下子步骤:
11、s3.1、将弱增强频谱对(wl,wr)中的弱增强频谱wl输入到学生模型中得到预测值,即预测的类分布的概率向量ql;
12、s3.2、判断ql是否大于阈值,是则确定弱增强频谱wl为伪标签,然后执行步骤s3.3,否则返回执行s3.1;
13、s3.3、将弱增强频谱wr输入到学生模型中得到预测值,即预测的类分布的概率向量qr,然后用巴氏系数计算ql和qr的相似度bc(ql,qr),如果ql和qr之间的相似度大于置信阈值,是则确认wl和wr相似;然后执行步骤s3.4,否则返回步骤s3.1;
14、s3.4、将强增强频谱sr和弱增强频谱wl输入到学生模型中得到相对应的概率向量p和q,计算p和q的相似损失;
15、进一步地,前述的步骤s3.3中,用巴氏系数计算ql和qr的相似度bc(ql,qr),如下式:
16、其中,x是概率向量的元素值。
17、进一步地,前述的步骤s3.4中,计算相似损失,如下式:
18、simloss=1-bc(p,q)
19、进一步地,前述的步骤s3.2中,预测阈值为0.9。
20、进一步地,前述的一种基于半监督模型的声音检测方法,弱增强采用的频率遮掩手段中的参数f=20,强增强采用的频率遮掩手段中的参数f=40。
21、相较于现有技术,本发明采用以上技术方案的有益技术效果如下:
22、1.优化改进了现有的平均教师模型,提出了相似损失的概念;
23、2.通过充分利用无标签数据提升了检测的准确度;
24、3.传统的一致性损失强调了同一类别的同一样本的一致性,本发明提出的相似损失强调了同一类别的不同样本的一致性。
技术特征:1.一种基于半监督模型的声音检测方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的一种基于半监督模型的声音检测方法,其特征在于,步骤s1具体为:对若干无标签音频数据进行快速傅里叶变换、求能量谱、使用128个滤波器提取梅尔频谱特征、取对数获得对数梅尔频谱,然后两两配对为对数梅尔频谱对(l,r)。
3.根据权利要求1所述的一种基于半监督模型的声音检测方法,其特征在于,步骤s3中,教师模型和学生模型的网络架构是crnn结构。
4.根据权利要求1所述的一种基于半监督模型的声音检测方法,其特征在于,步骤s2中弱增强策略、以及强增强策略是频率维度遮掩,获得弱增强对数梅尔频谱对(wl,wr)、强增强对数梅尔频谱对(sl,sr),具体为:沿频域轴方向的[f0,f0+f)范围内的连续频率通道进行掩蔽,其中0≤f0<v,v是通道数,f服从[0,f]均匀分布,f是频率遮掩参数。
5.根据权利要求4所述的一种基于半监督模型的声音检测方法,其特征在于,相似度损失计算包括以下子步骤:
6.根据权利要求5所述的一种基于半监督模型的声音检测方法,其特征在于,步骤s3.3中,用巴氏系数计算ql和qr的相似度bc(ql,qr),如下式:
7.根据权利要求5所述的一种基于半监督模型的声音检测方法,其特征在于,步骤s3.4中,计算相似损失,如下式:
8.根据权利要求5所述的一种基于半监督模型的声音检测方法,其特征在于,步骤s3.2中,预测阈值为0.9。
9.根据权利要求4所述的一种基于半监督模型的声音检测方法,其特征在于,弱增强采用的频率遮掩手段中的参数f=20,强增强采用的频率遮掩手段中的参数f=40。
技术总结本发明公开了一种基于半监督模型的声音检测方法,通过针对无标签音频数据的对数梅尔频谱对进行弱增强策略、强增强策略,分别得到弱增强、强增强对数梅尔频谱对。本发明以强标签、弱标签、无标签对数梅尔频谱、弱增强、强增强对数梅尔频谱对为输入、音频数据的类别和时间为输出,构建和训练教师模型和学生模型,并且在训练学生模型过程中,针对弱增强、强增强对数梅尔频谱图的预测值进行相似损失计算,针对强标签、弱标签对数梅尔频谱图的预测值进行分类损失计算;同时计算教师模型和学生模型的一致性损失,最终得到半监督声音检测模型。本发明优化改进了现有的平均教师模型,提出了相似损失的概念;通过充分利用无标签数据提升了检测的准确度。技术研发人员:邵曦,唐亦奇,丁卓,刘叔弢,谭涛受保护的技术使用者:南京邮电大学技术研发日:技术公布日:2024/2/19本文地址:https://www.jishuxx.com/zhuanli/20240618/21716.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表