一种基于自适应滤波与神经网络的回声消除方法
- 国知局
- 2024-06-21 11:28:15
本发明涉及声音处理,尤其涉及一种基于自适应滤波与神经网络的回声消除方法。
背景技术:
1、5g时代的来临,voip(voice over internet protocol)通信技术更能够满足广大群众的需求,并且已经得到了广泛的应用。尽管voip通信非常方便,但在通话过程中,会存在回声,影响通话质量,给通话者带来困扰。目前已有的回声消除方案主要基于自适应滤波,但现实声学环境复杂多变,存在大量噪声与混响。传统的自适应滤波难以处理这种情况,无法实现良好的回声消除效果。
技术实现思路
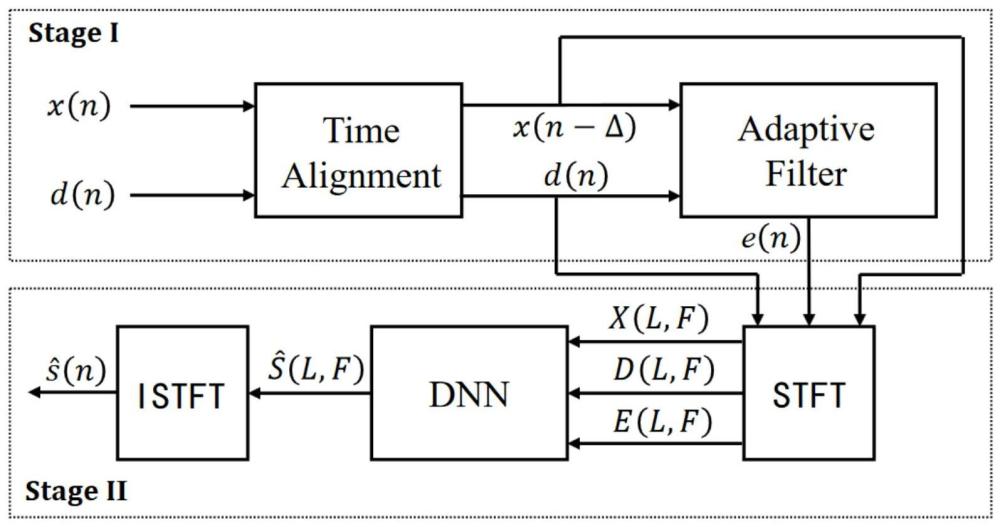
1、针对现有技术中存在的缺陷或不足,本发明所要解决的技术问题是:提供一种基于自适应滤波器和深度神经网络的多级声学回声消除模型。该模型由两部分组成:用于消除线性回声的speex算法,以及进一步消除回声的多尺度时频unet。
2、为了实现上述目的,本发明采取的技术方案为提供一种基于自适应滤波与神经网络的回声消除方法,包括以下步骤:采用speex算法作为自适应滤波器对线性回声进行消除,首先通过时间对齐模块对远端的参考语音信号x(n)和近端的麦克风d(n)进行延迟估计和补偿,从而得到x(n-δ),其中δ代表估计的延迟值;将x(n-δ)与d(n)输入到预先设定的自适应滤波器中,进行初步的回声消除,最后输出线性回声消除后的误差信号e(n);
3、以unet为基本框架,搭建了一个多尺度时频unet对非线性回声进行消除,
4、作为本发明的进一步改进,最大化地利用音频数据,对x(n)、d(n)和e(n)执行了stft处理,将这些信号从时域转化到时频域,从而获得了x(l,f)、d(l,f)和e(l,f),这里的l和f分别代表复值频谱的时间帧和频率帧,将这三个时频域的复值频谱送入预建的深度神经网络进行训练和预测,输出预测的近端语音复值频谱通过istft转换,将转回到估计的近端语音信号完成回声的多阶段消除。
5、作为本发明的进一步改进,所述自适应滤波器的滤波采用多延迟块滤波器,使用了interspeech 2021声学进行回声消除,使用了广义互相关相位变换算法对两个信号进行时间对齐。
6、作为本发明的进一步改进,所述多尺度时频unet先通过相位编码器将复值频谱转为实值频谱,采用一个输入卷积层以提取特征并调整通道数量,构建了主网络,包含三个编码器,两个底层模块,以及三个解码器,利用一个输出卷积层,并应用相应的掩模,从而产生了回声消除后的预测语音频谱。
7、作为本发明的进一步改进,:在所述每个编码器中集成了频率下采样模块、时间频率卷积模块和改良的时频自注意力模块,时频自注意力模块在低计算复杂度的条件下有效地提取语音信息,主要包括两个关键因素:(1)时频自注意力模块将时频自注意力分为了时间自注意力和频率自注意力,时间自注意力和频率自注意力的计算复杂度分别为l2和f2,与简单的自注意相比,计算复杂度从l2×f2降低到l2+f2,(2)在生成自注意图之前集成了1×1点卷积和3×3深度卷积。
8、作为本发明的进一步改进,采用通道时频注意力来连接编码器与解码器,用于捕捉通道与时频维度的特征信息,在整个训练过程中,loss函数使用了复值均方误差(complex mean squared error,cmse)作为损失函数,其cmse的具体计算过程如公式(1)所示:
9、
10、式中,α和β的值分别是0.3和0.7,pcri和pcmag的计算方式如下所示:
11、
12、
13、式中,scri和scmag分别代表干净语音的复值压缩频谱和幅度压缩频谱,
14、表示估计的语音频谱,scri和scmag的计算过程如下:
15、scmag=|smag|c#(4)
16、
17、式中,c是压缩系数,值为0.3。
18、本发明的有益效果是:本发明的主要优点如下:(1)在自适应滤波之前进行了时间对齐,弥补了回声信号的延迟,提升了自适应滤波器的回声消除效果;(2)以unet为基础,构建了一个能多尺度地提取时频维度特征的神经网络;(3)该多级回声消除模型可以在复杂的噪声、混响环境下实现优越的回声消除效果。
技术特征:1.一种基于自适应滤波与神经网络的回声消除方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于自适应滤波与神经网络的回声消除方法,其特征在于:最大化地利用音频数据,对x(n)、d(n)和e(n)执行了stft处理,将这些信号从时域转化到时频域,从而获得了x(l,f)、d(l,f)和e(l,f),这里的l和f分别代表复值频谱的时间帧和频率帧,将这三个时频域的复值频谱送入预建的深度神经网络进行训练和预测,输出预测的近端语音复值频谱通过istft转换,将转回到估计的近端语音信号完成回声的多阶段消除。
3.根据权利要求1所述的基于自适应滤波与神经网络的回声消除方法,其特征在于:所述自适应滤波器的滤波采用多延迟块滤波器,使用了interspeech 2021声学进行回声消除,使用了广义互相关相位变换算法对两个信号进行时间对齐。
4.根据权利要求1所述的基于自适应滤波与神经网络的回声消除方法,其特征在于:所述多尺度时频unet先通过相位编码器将复值频谱转为实值频谱,采用一个输入卷积层以提取特征并调整通道数量,构建了主网络,包含三个编码器,两个底层模块,以及三个解码器,利用一个输出卷积层,并应用相应的掩模,从而产生了回声消除后的预测语音频谱。
5.根据权利要求4所述的基于自适应滤波与神经网络的回声消除方法,其特征在于:在所述每个编码器中集成了频率
6.根据权利要求4所述的基于自适应滤波与神经网络的回声消除方法,其特征在于:采用通道时频注意力来连接编码器与解码器,用于捕捉通道与时频维度的特征信息,在整个训练过程中,loss函数使用了复值均方误差(complex mean squared error,cmse)作为损失函数,其cmse的具体计算过程如公式(1)所示:
技术总结本发明涉及声音处理技术领域,尤其涉及一种基于自适应滤波与神经网络的回声消除方法。该模型由两部分组成:用于消除线性回声的Speex算法,以及进一步消除回声的多尺度时频UNet。主要优点如下:(1)在自适应滤波之前进行了时间对齐,弥补了回声信号的延迟,提升了自适应滤波器的回声消除效果;(2)以UNet为基础,构建了一个能多尺度地提取时频维度特征的神经网络;(3)该多级回声消除模型可以在复杂的噪声、混响环境下实现优越的回声消除效果。技术研发人员:徐诗韵,王明江受保护的技术使用者:哈尔滨工业大学(深圳)(哈尔滨工业大学深圳科技创新研究院)技术研发日:技术公布日:2024/2/19本文地址:https://www.jishuxx.com/zhuanli/20240618/21702.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表